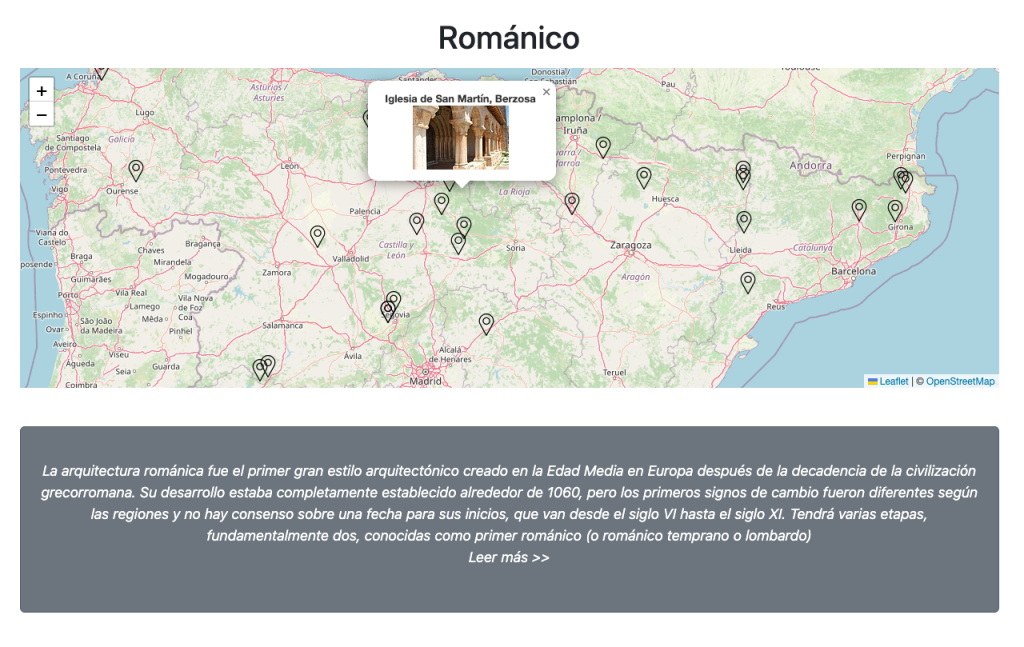
De archivos XML aislados a un ecosistema de datos sanitarios interoperables con RAG y Análisis Predictivo
Los datos de medicamentos existen, son públicos y están bien documentados… pero están fragmentados, no están enlazados y no permiten razonamiento ni exploración semántica real.
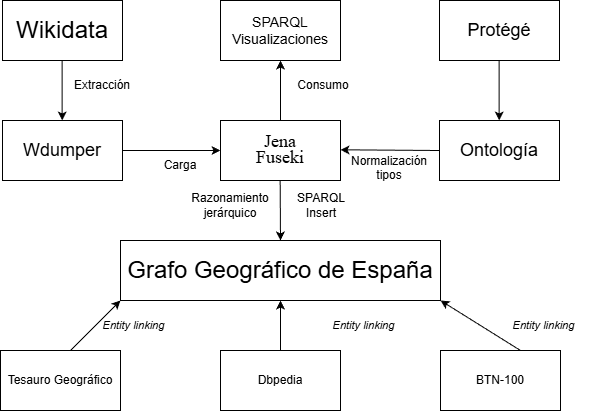
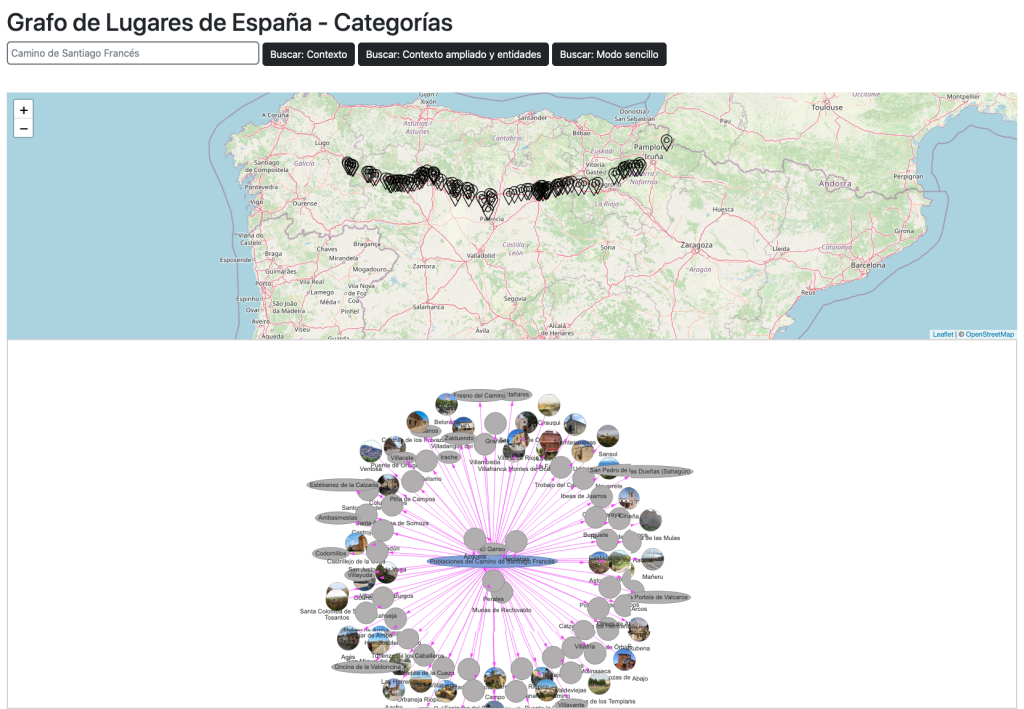
Este proyecto aborda ese problema transformando el Nomenclátor oficial de la AEMPS en un grafo de conocimiento sanitario interconectado con ontologías biomédicas internacionales.
La información sanitaria pública es vasta pero fragmentada. La Agencia Española de Medicamentos (AEMPS) ofrece datos cruciales en XML y Excel; Wikidata y DBpedia poseen el contexto biológico; y las ontologías como ATC o DOID (Human Disease Ontology) estructuran el conocimiento médico. El problema es que estos mundos no se hablan entre sí.
HealthKG nace con un objetivo: romper estos silos. Es una arquitectura de conocimiento que ingesta, normaliza y vincula estas fuentes para permitir preguntas complejas como: «¿Qué principios activos aprobados en España interactúan con este gen y qué enfermedades tratan según la literatura internacional?»
Transformación de datos institucionales a Knowledge Graph
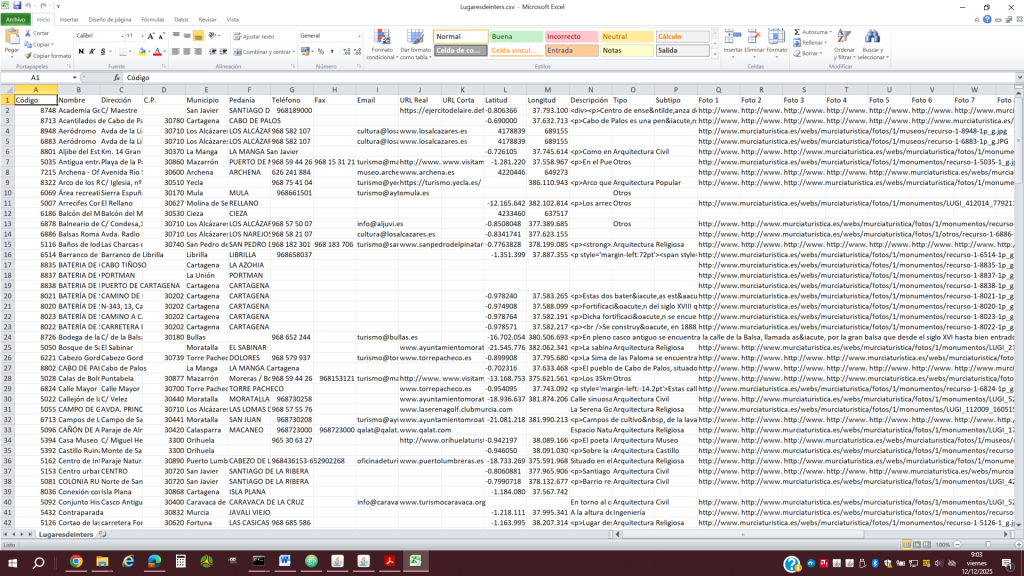
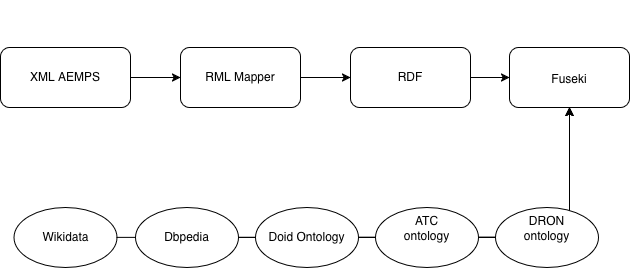
El primer desafío fue transformar los diccionarios XML de la AEMPS (Nomenclátor) y varios archivos en .xls de facturación y medicamentos en tripletas RDF estandarizadas.
Según define la propia AEMPS:
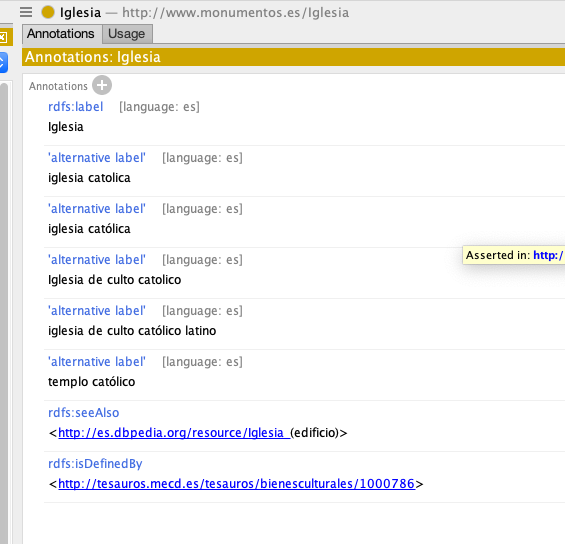
«El Nomenclátor de prescripción es una base de datos de medicamentos diseñada para proporcionar información básica de prescripción a los sistemas de información asistenciales.»
y
«El Nomenclátor de prescripción incluye para todos los medicamentos autorizados y comercializados, financiados y no financiados, los datos relativos a su identificación e información técnica (a título informativo contiene también información de medicamentos suspendidos, revocados o que han dejado de estar comercializados desde mayo de 2013).»
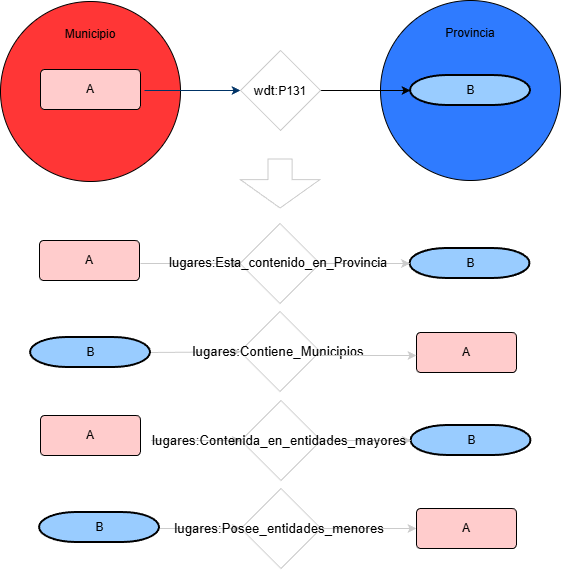
El Nomenclátor no modela explícitamente relaciones semánticas entre medicamentos, principios activos y efectos. Este proyecto convierte relaciones implícitas en entidades y propiedades explícitas, habilitando razonamiento y navegación.
Stack Tecnológico:
- RML (RDF Mapping Language): Para mapear estructuras XML complejas (prescripciones) a nuestra ontología.
- Tarql: Para la conversión ágil de archivos Excel/CSV.
- Apache Jena Fuseki: Como Triple Store para orquestar el grafo.
Diseño Ontológico y Modelado
Partiendo de los diccionarios ya creados por el Ministerio y de las propias necesidades del futuro grafo creo las clases y propiedades en Protégé:
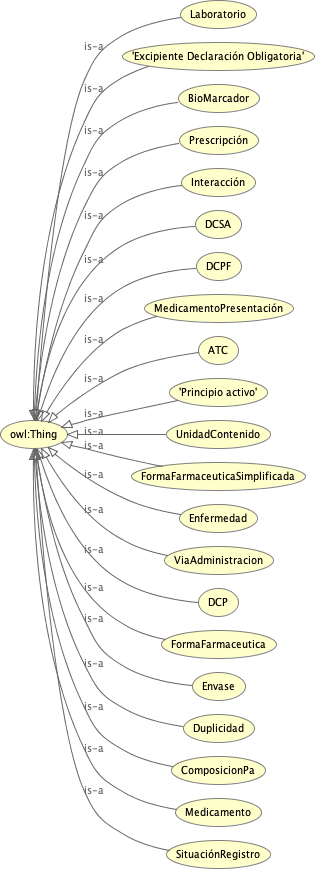
Diseño una ontología central (med:) capaz de actuar como «pegamento» entre las distintas fuentes. Creamos clases que no existían explícitamente en los datos originales, como med:Interacción o med:Biomarcador, transformando simples notas de texto en entidades conectadas.
Se añaden varias clases no existentes en los diccionarios:
- med:Medicamento vinculada con prescripciones, principios activos y laboratorios.
- med:Enfermedad vinculada con principios activos.
- med:Interacción vincula pares de códigos ATC, y principios activos.
- med:Duplicidad vincula pares de códigos ATC, y principios activos.
- med:Biomarcador vincula principios activos y genes.
Un grafo de contexto de 169M de triples
Con el objetivo de poseer un grafo de «contexto» para los medicamentos realizo una extracción controlada de Wikidata. El punto de unión básico proyectado van a ser los principios activos. Sustancias químicas, naturales o artificiales utilizadas para la fabricación de medicamentos y que producen un efecto terapéutico. El grafo de «contexto» extraído posee tipos de entidades como: Entidad química, molecular function, biological process, class of disease, gene, taxon, chromosome, y un largo etcétera.
En sí mismo compone un grafo biológico muy completo. Conteniendo 169.374.083 millones de triples. De esta manera conseguimos un subgrafo temático que utilizo como contexto semántico local y que permite razonamiento cruzado.
Entity linking multi-grafo
Un grafo aislado no aporta valor. La potencia de HealthKG reside en su conectividad con la nube de datos abiertos enlazados (LOD):
- Reconciliación Química: Vinculamos más de 2.200 principios activos de la AEMPS con Wikidata y DBpedia. Esto nos permitió importar propiedades moleculares y genéticas que la AEMPS no posee.
- Jerarquización ATC: Los códigos ATC planos se vincularon a la ATC Ontology, permitiendo consultas jerárquicas (ej: «Dame todos los antiinflamatorios», no solo el Ibuprofeno).
- Enfermedades y Tratamientos: Mediante técnicas de procesamiento de texto y coincidencia de etiquetas, inferimos la relación enfermedadTieneTratamiento cruzando datos de Dbpedia y Wikidata con nuestros principios activos.
Vinculamos datos de:
- Wikidata
- Dbpedia (es)
- ATC ontology
- DOID
- DRON
Estrategias de emparejamiento de entidades en grafos heterogéneos
Principios activos
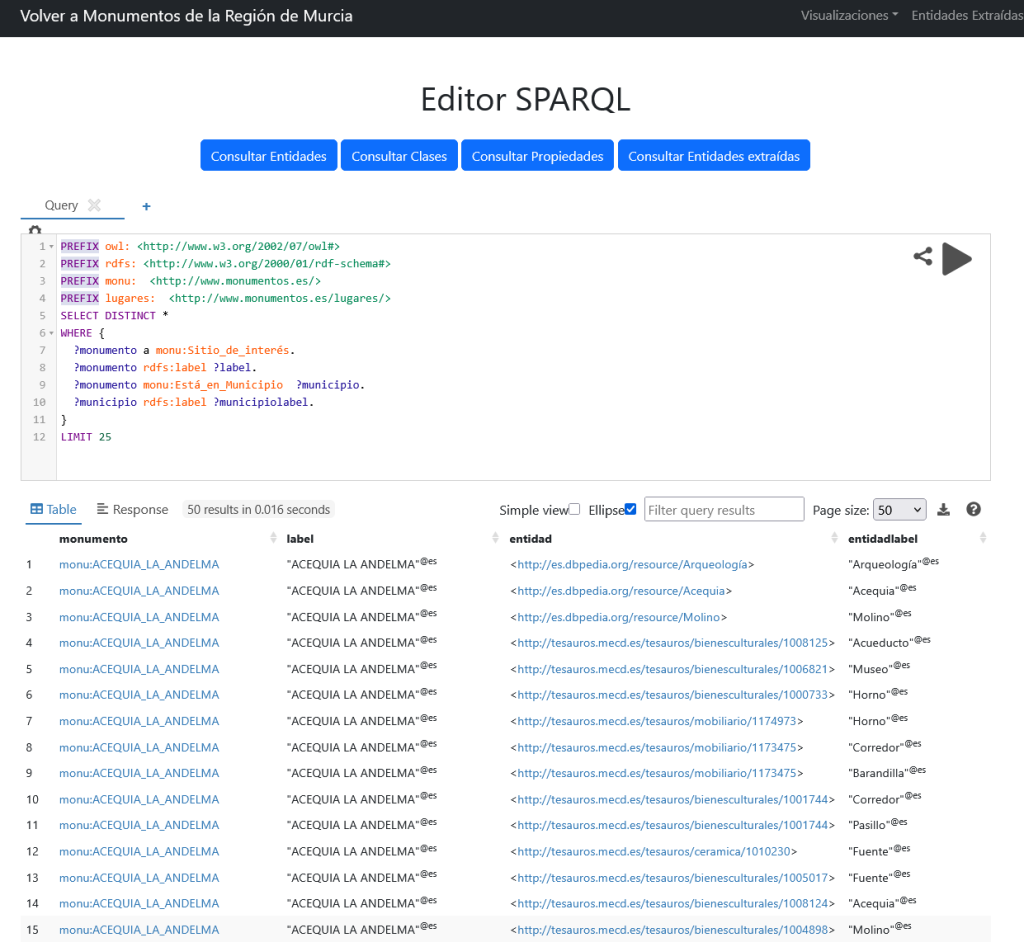
El primer emparejamiento de entidades que realizamos es entre los principios activos de nuestro grafo de medicamentos y las sustancias químicas presentes en el grafo de contexto y en Dbpedia en español para aumentar la conectividad y el acceso a información.
Este será el puente principal por el que unificar las distintas fuentes que tenemos entre manos y comenzar a lograr que los datos AEMPS dejen de estar aislados. De este modo podremos saltar desde un medicamento a su principio activo y de este a la enfermedad que trata, función que regula, gen, etc o seguir otros caminos en estas relaciones…
| med:PrincipioActivo | 3.167 |
| Dbpedia (emparejados) | 1.153 |
| Wikidata (emparejados) | 1.184 |
| med:esVariacionDePrincipioActivo | 1.115 |
Teniendo en cuenta que 1.115 principios activos son variaciones de otros ya emparejados hemos conseguido emparejar unos 2.200 principios activos, mas de dos tercios del total.
Consulta para construir los principios que son med:esVariacionDePrincipioActivo:
PREFIX rdfs: <http://www.w3.org/2000/01/rdf-schema#>
PREFIX rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#>
PREFIX med: <http://www.medicamentos.es/>
construct {
?principioactivo2 med:esVariacionDePrincipioActivo ?principioactivo1; #El principio activo 2 será una variación del 1
}
WHERE {
?principioactivo1 a med:PrincipioActivo;
rdfs:label ?principioactivo1label .
?principioactivo2 a med:PrincipioActivo;
rdfs:label ?principioactivo2label ;
# El nombre del principio 2 comienza igual que el nombre del prinicipo 1
FILTER (strStarts(?principioactivo2label, ?principioactivo1label)).
filter (?principioactivo2 != ?principioactivo1 )
}Lenguaje del código: PHP (php)Ejemplo de resultado:
http://www.medicamentos.es/PrincipioActivo/990
rdf:type med:PrincipioActivo ;
rdfs:label "ABACAVIR"@es ;
med:codigoPrincipioActivo "1111A" ;
med:nroPrincipioActivo "990" .
http://www.medicamentos.es/PrincipioActivo/11578
rdf:type med:PrincipioActivo ;
rdfs:label "ABACAVIR CLORHIDRATO"@es ;
med:codigoPrincipioActivo "1111CH" ;
med:nroPrincipioActivo "11578" .
prinactiv:11578 med:esVariacionDePrincipioActivo
prinactiv:990 .Lenguaje del código: JavaScript (javascript)Enfermedades
Los principios activos son un paso necesario para vincular enfermedades tratadas por los medicamentos. Para generar y vincular enfermedades utilizaremos nuestra clase med:Enfermedad. En nuestro grafo de contexto extraído de Wikidata tenemos un tipo enfermedad (Q112193867) y una propiedad (P2176)que la vincula al principio activo como tratamiento.
- Primero construimos nuestras entidades med:Enfermedad a partir del tipo Q112193867.
- Luego generamos la propiedad med:enfermedadTieneTratamiento.
También quería extraer y vincular enfermedades de Dbpedia. Esta posee la clase Disease, con la que construir la nuestra. Sin embargo, Dbpedia no posee una propiedad que vincule un enfermedad y un tratamiento, para ello desarrollo un método plausible que nos permite crear dicha propiedad.
Rescatamos los Wikilinks (enlaces dentro de los artículos de Wikipedia) de cada entidad de tipo med:Enfermedad y los comparamos con nuestros principios activos, previamente vinculados con owl:sameAs. Es altamente probable que los artículos sobre una enfermedad contengan referencias a las sustancias que se usan en su tratamiento.
Construir la relación enfermedad tiene tratamiento Dbpedia:
PREFIX med: <http://www.medicamentos.es/>
PREFIX owl: <http://www.w3.org/2002/07/owl#>
PREFIX rdfs: <http://www.w3.org/2000/01/rdf-schema#>
prefix prinactiv: <http://www.medicamentos.es/PrincipioActivo/>
construct {
?enfermedad med:enfermedadTieneTratamiento ?principioActivo.
}
WHERE {
?enfermedad a <http://dbpedia.org/ontology/Disease>.
?enfermedad <http://dbpedia.org/ontology/wikiPageWikiLink> ?WikiLink.
service <https://javiermurcia.tech/lab/Medicamentos> {
?principioActivo a med:PrincipioActivo;
owl:sameAs ?WikiLink.
}
}Lenguaje del código: HTML, XML (xml)Esta consulta construye relaciones tratamiento–enfermedad en Dbpedia, donde dicha propiedad no existe explícitamente, usando enlaces internos de Wikipedia como señal semántica.

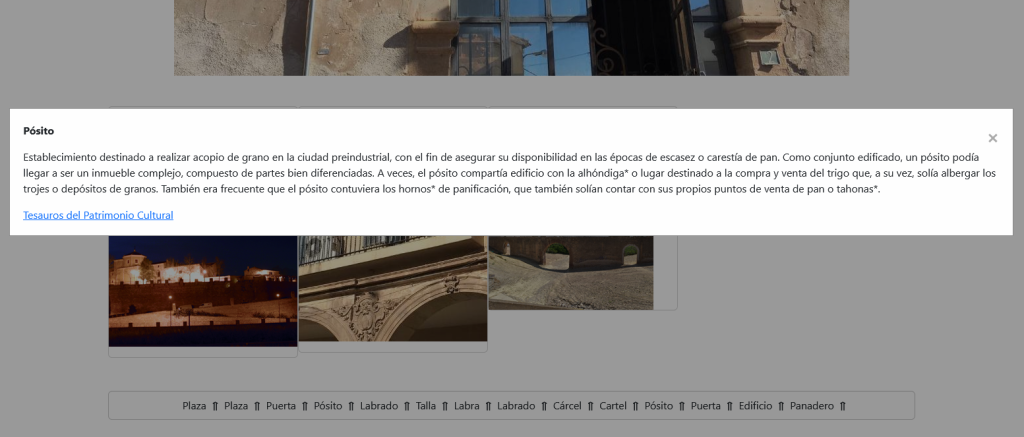
Como vemos en la imagen para la enfermedad «Reflujo gastroesofágico» la coincidencia entre tratamientos de la parte superior Dbpedia y la parte inferior grafo de contexto extraído de Wikidata, es altamente significativa.
Aprovechando que Dbpedia posee categorías construyo una taxonomía de las enfermedades con tratamientos farmacológicos. Lo que resultará muy útil para la navegación posterior. Partiendo de Categoría:Enfermedades_por_especialidad_médica, construimos las demás.
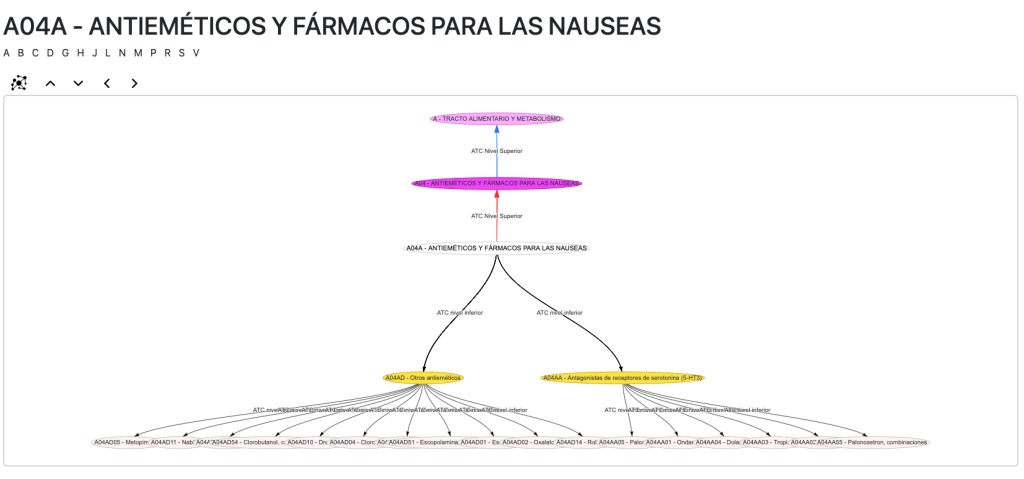
Códigos ATC
La AEMPS incluye un diccionario de códigos ATC. El código ATC o Sistema de Clasificación Anatómica, Terapéutica y Química, es un índice de sustancias farmacológicas y medicamentos, organizados según grupos terapéuticos.
Sin embargo, tal cual se encuentra no compone ni siquiera un árbol jerárquico por el que poder navegar. La solución: vincular mis entidades a la ATC ontology, que posee una organización en subclases que mejorará nuestras consultas, razonamientos y navegación.
Creando los Biomarcadores como clase e entidades
La base datos de Prescripciones incluye biomarcadores farmacogenómicos con aquellos principios activos con los que se ha establecido una conexión. Pero estos, no existen como entidades independientes, primero construyo a partir de las prescripciones en las que aparecen, junto a sus principios activos y los vinculo a los genes a los que hacen referencia en el grafo de contexto biológico.
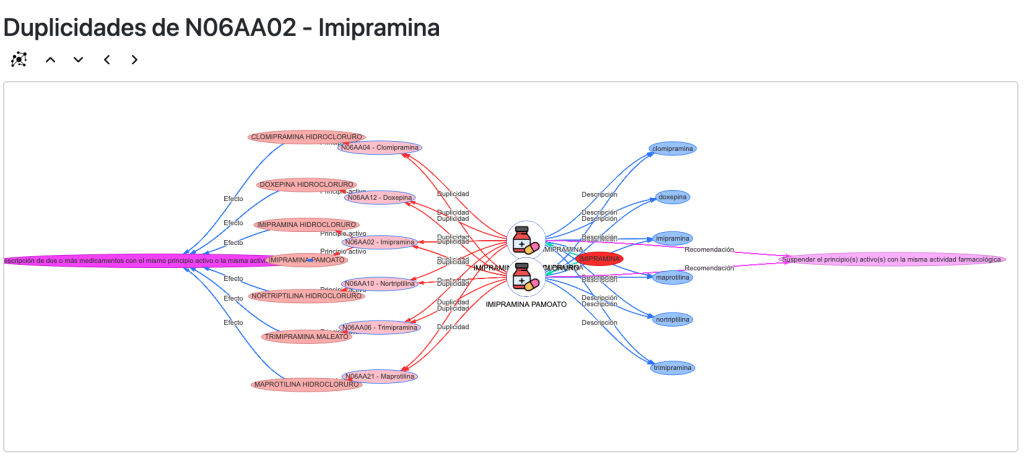
Interacciones y Duplicidades
De igual modo ocurre con las interacciones y las duplicidades
que no existen como entidades sino solamente como relaciones. Lo que hago es relacionar los códigos ATC que interaccionan. Las prescripciones simplemente apuntan a un código ATC con el que interacciona, yo relaciono los códigos ATC y los principios activos:
Construyendo las interacciones:
PREFIX med: <http://www.medicamentos.es/>
PREFIX rdfs: <http://www.w3.org/2000/01/rdf-schema#>
construct {
?interaccion a med:Interacción;
med:interaccionaCon ?ATCinteraccion;
rdfs:label ?rdfslabel2;
med:seRefiereATC ?ATC;
med:efectoInteraccion ?efectoInteraccion;
med:recomendacionInteraccion ?recomendacionInteraccion;
med:tienePrincipioActivo ?PrincipioActivo;
med:principioActivoInteraccion ?PrincipioActivo2;
}
WHERE {
?a a med:Prescripción.
?a med:codigoATC ?codigoATC.
BIND(URI(CONCAT( "http://www.medicamentos.es/Interacción/" ,?codigoATC) ) AS ?label ) .
?a med:tieneComposicionPa ?tieneComposicionPa.
?a med:atcInteraccion ?atcInteraccion.
?a med:efectoInteraccion ?efectoInteraccion;
med:recomendacionInteraccion ?recomendacionInteraccion.
?b a med:Prescripción;
med:codigoATC ?atcInteraccion;
med:tieneComposicionPa ?tieneComposicionPa2;
med:atcInteraccion ?codigoATC;
med:efectoInteraccion ?efectoInteraccion;
med:recomendacionInteraccion ?recomendacionInteraccion.
?ATC a med:ATC;
med:codigoATC ?codigoATC.
?ATCinteraccion a med:ATC;
med:codigoATC ?atcInteraccion;
BIND(URI(CONCAT( STR(?label) ,"+") ) AS ?label2 ) .
BIND(URI(CONCAT( STR(?label2) , ?atcInteraccion) ) AS ?interaccion) .
BIND(CONCAT( STR(?codigoATC) , "+") AS ?rdfslabel) .
BIND(CONCAT( STR( ?rdfslabel) , ?atcInteraccion) AS ?rdfslabel2) .
?PrincipioActivo a med:PrincipioActivo;
med:nroPrincipioActivo ?tieneComposicionPa.
?PrincipioActivo2 a med:PrincipioActivo;
med:nroPrincipioActivo ?tieneComposicionPa2;
}Lenguaje del código: PHP (php)Doid.owl y The Drug Ontology
Vinculamos con la ontología doid.owl. La Human Disease Ontology, compone una clasificación integral de enfermedades humanas organizadas por etiología. Lo que hago es emparejar las enfermedades que ya poseo con una ontología profesional para aumentar la conectividad y la base de verificabilidad del grafo.
Finalmente vinculo también nuestros principios activos con la ontología dron (The Drug Ontology). Yendo de nuestros principios a los extraídos de Wikidata, usamos sus labels en inglés y de ellos hacia la dron.
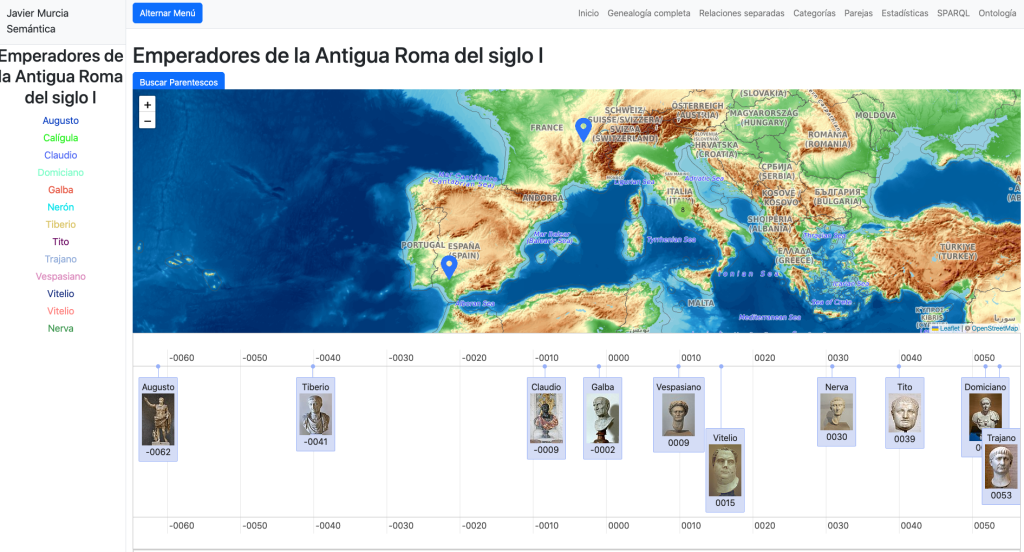
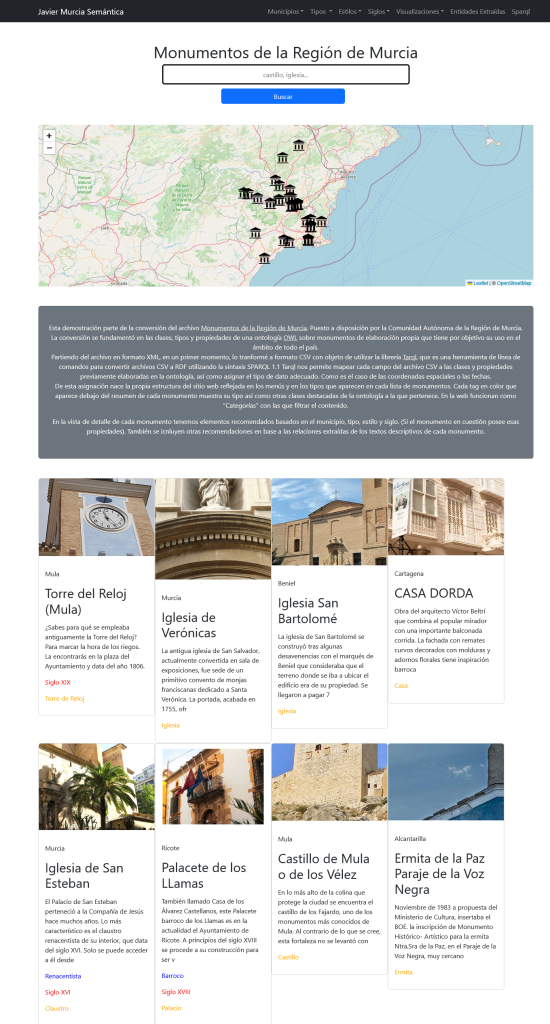
Navegación por descubrimiento semántico
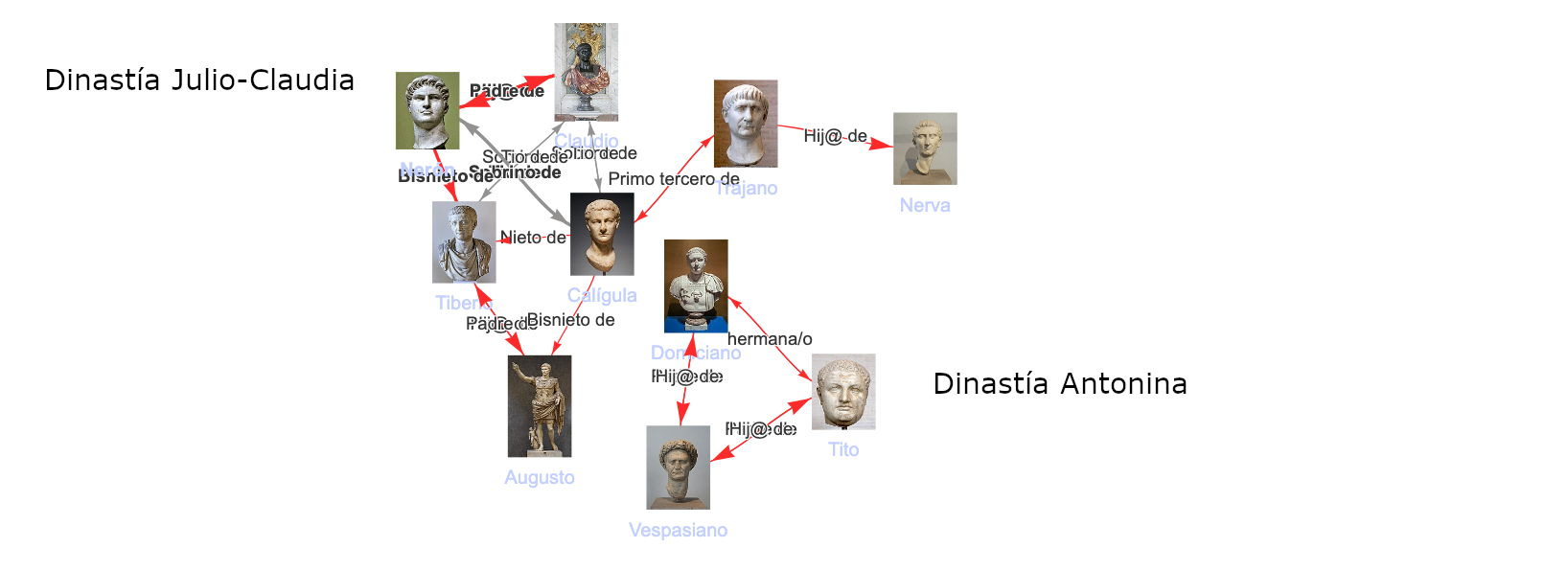
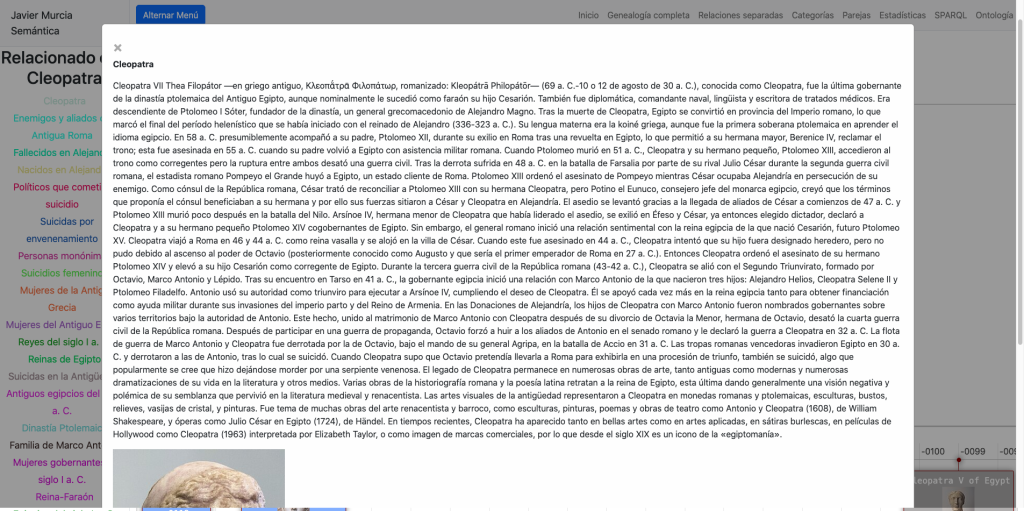
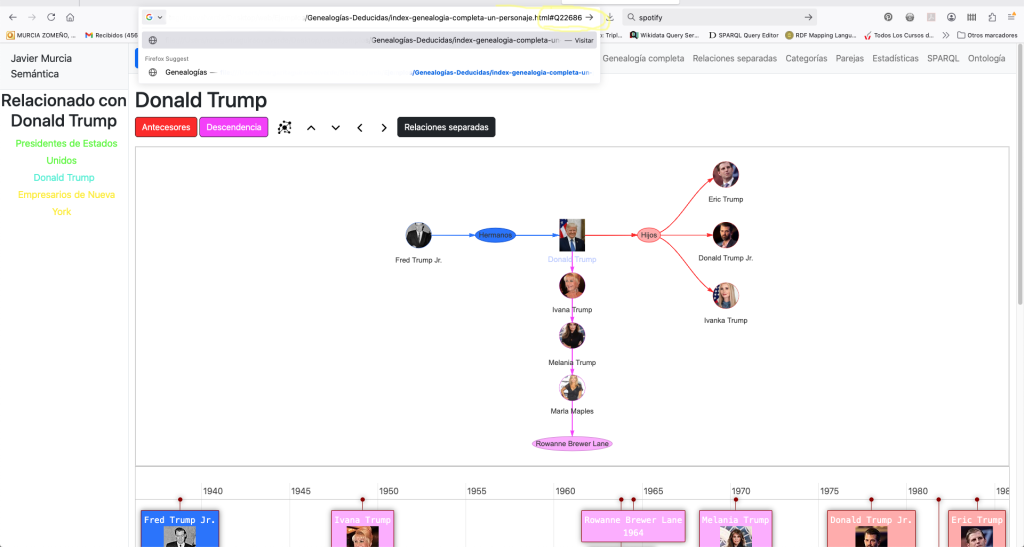
Para hacer el grafo accesible, desarrollé una interfaz de Navegación por Descubrimiento. A diferencia de un buscador tradicional, aquí el usuario «surfea» las relaciones:
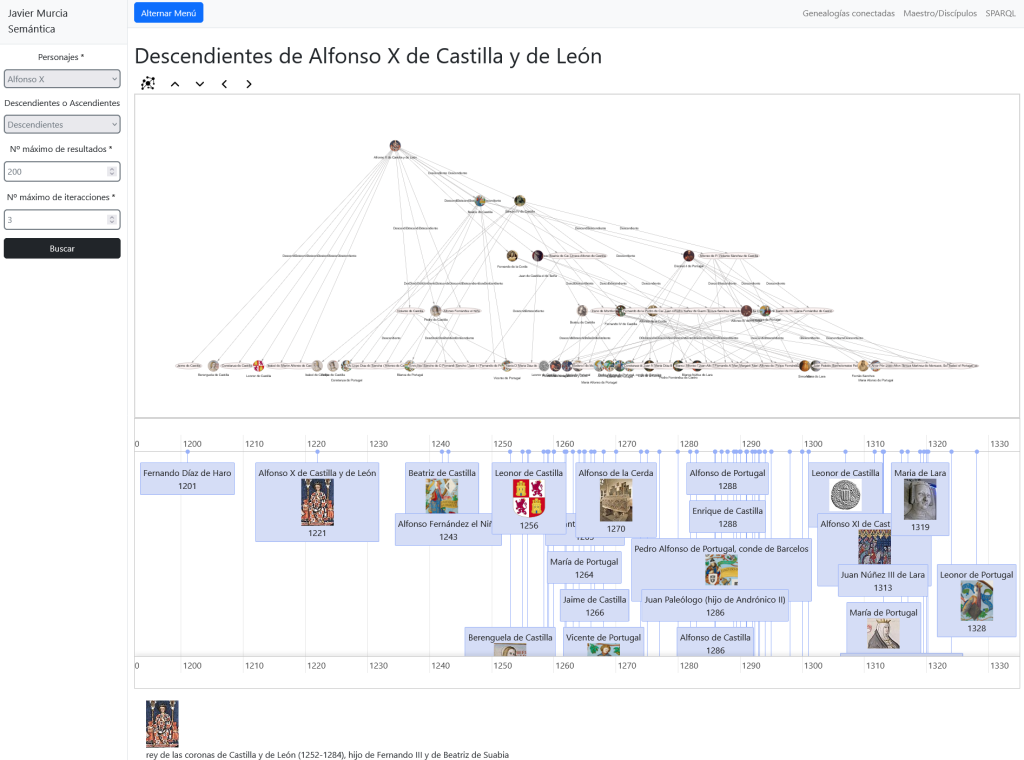
- De un Laboratorio en el mapa -> a sus Medicamentos en una línea de tiempo.
- De un Medicamento -> a su Principio Activo -> a las Enfermedades que trata.
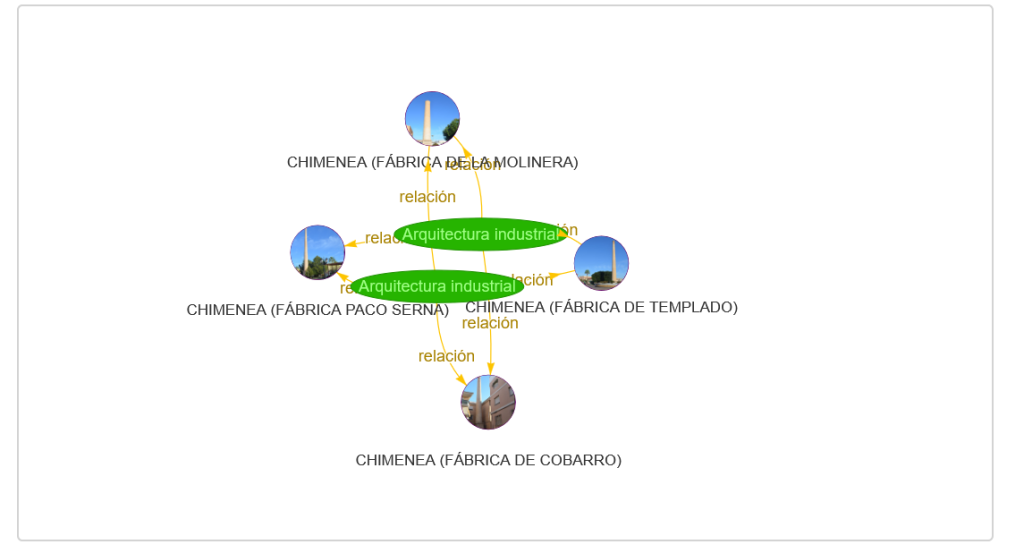
- Visualización de Interacciones y Duplicidades no como listas de alerta, sino como grafos de red.
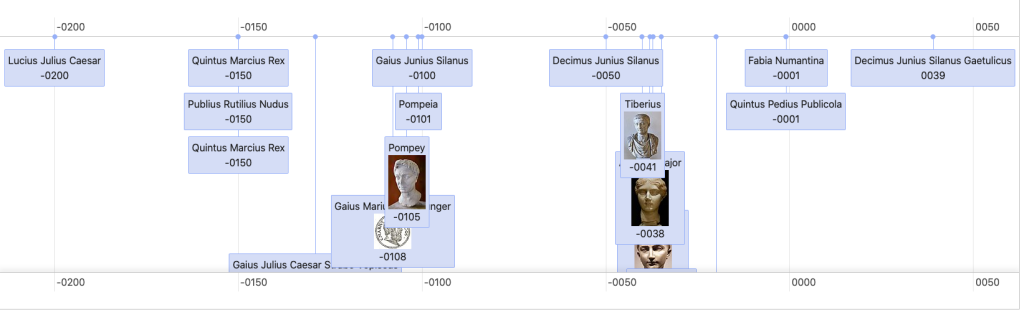
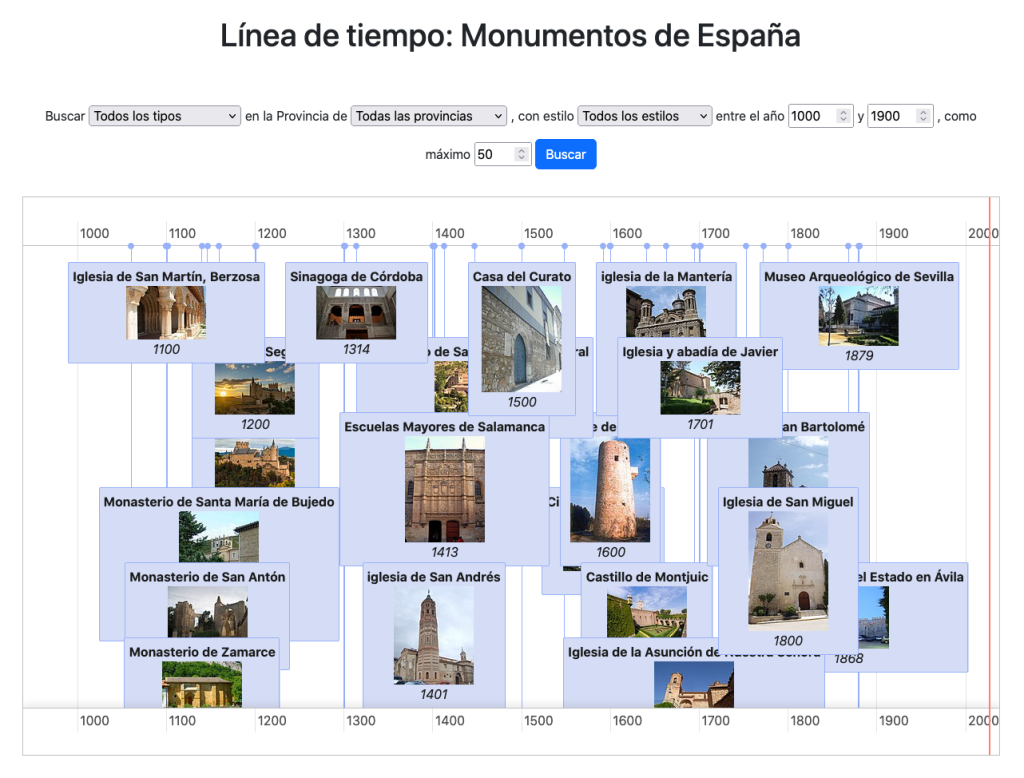
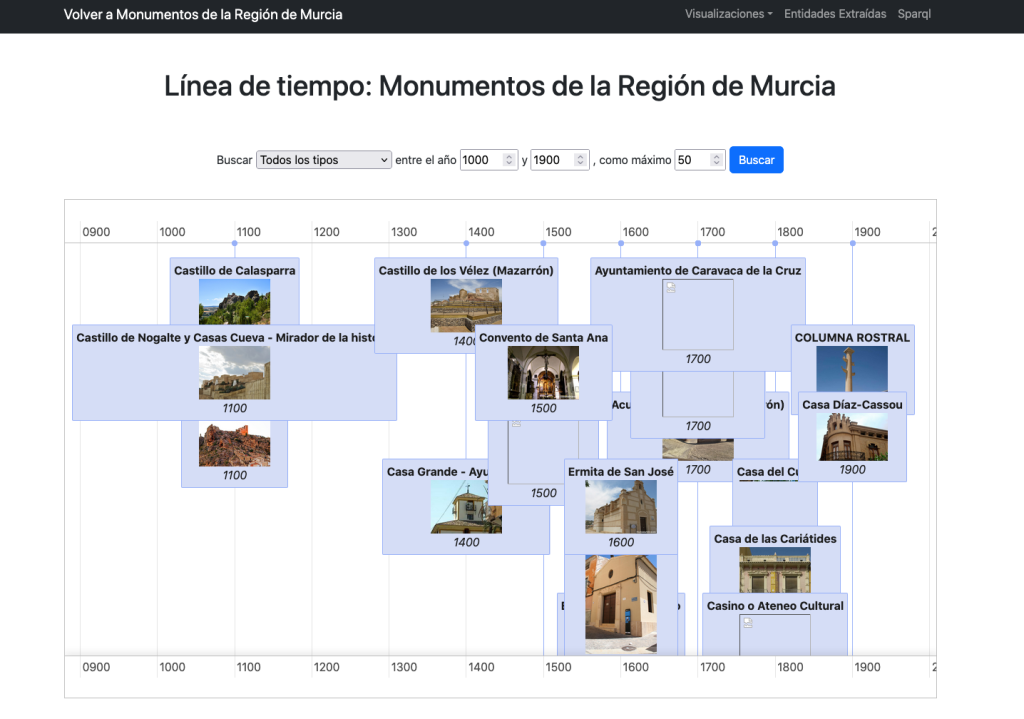
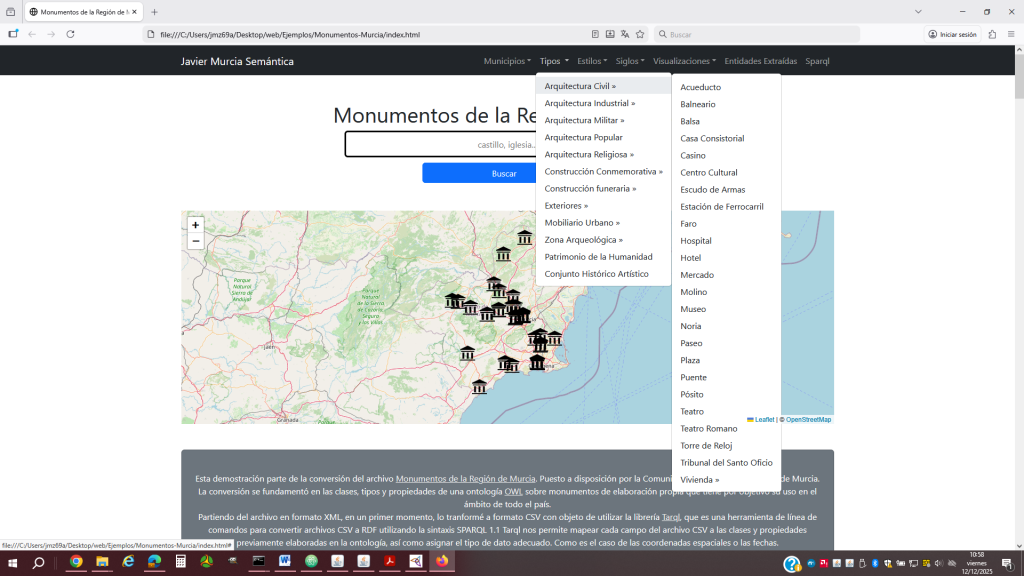
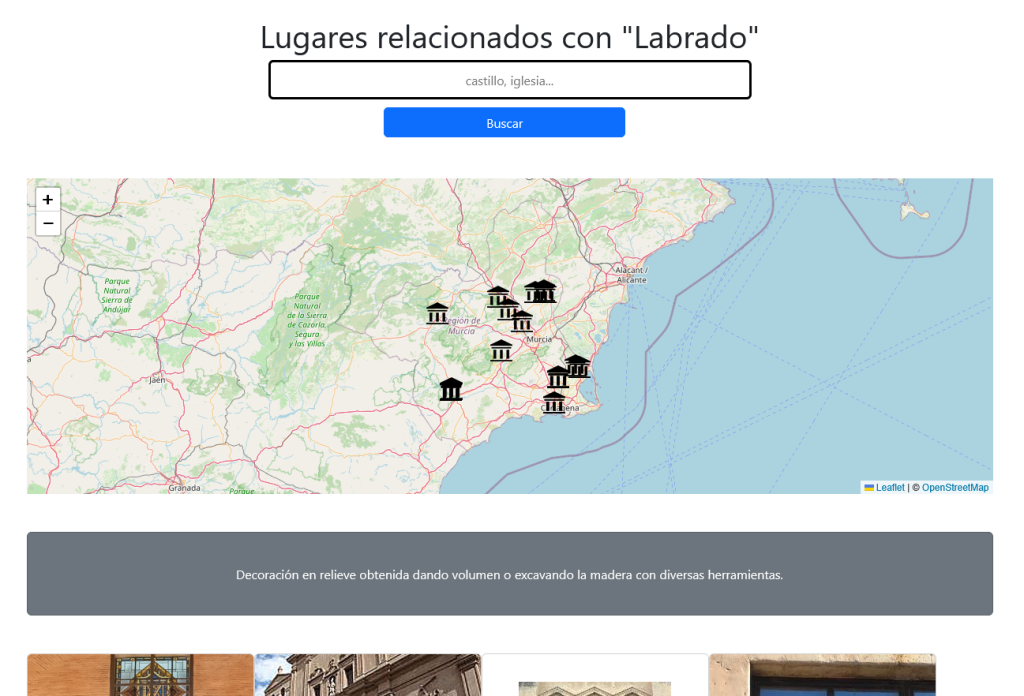
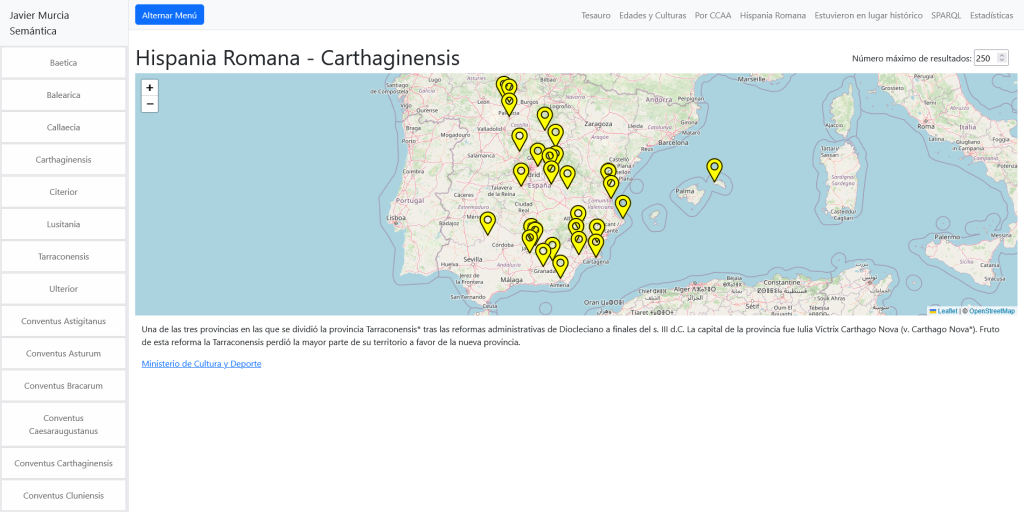
En la Home comenzamos con un listado de Laboratorios farmacéuticos que tienen una sede en España desplegados en un mapa. Podemos seleccionarlos y cargar los medicamentos que les corresponden en una línea de tiempo.
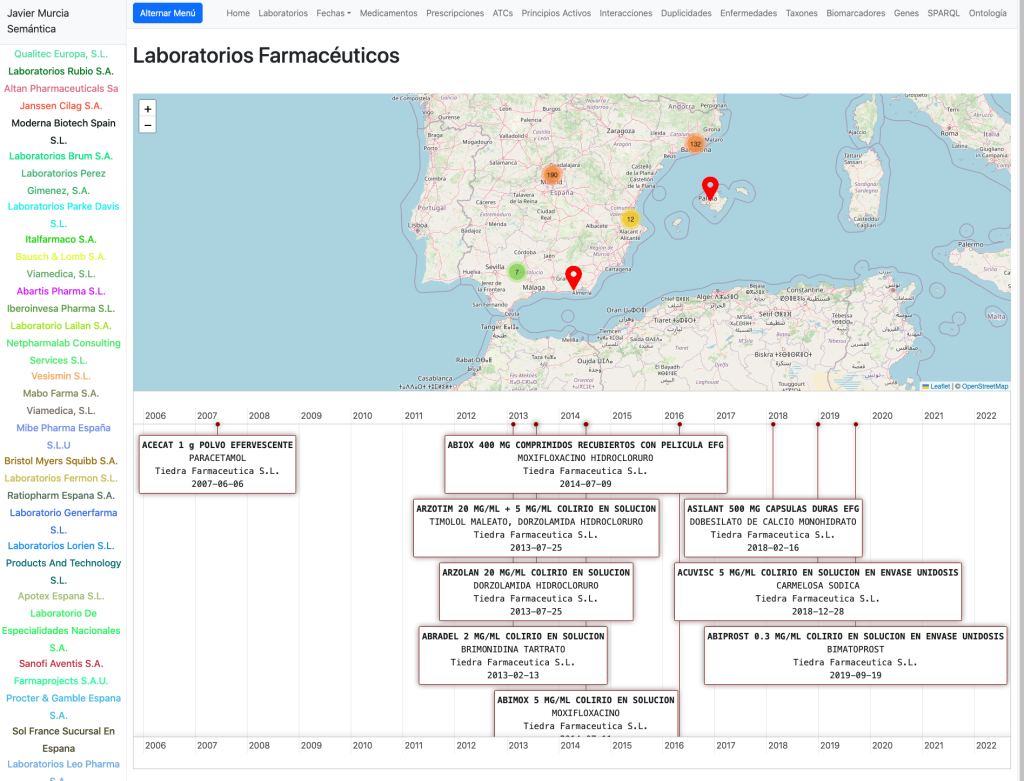
Podemos cargar un laboratorio seleccionándolo y cargarlo en una página especial:
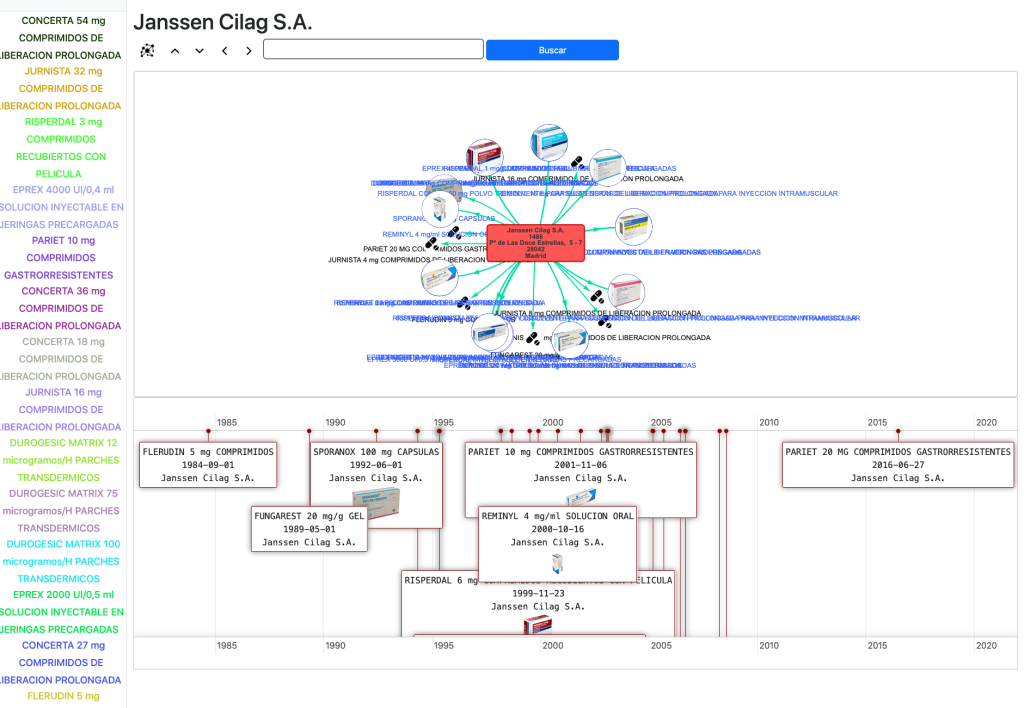
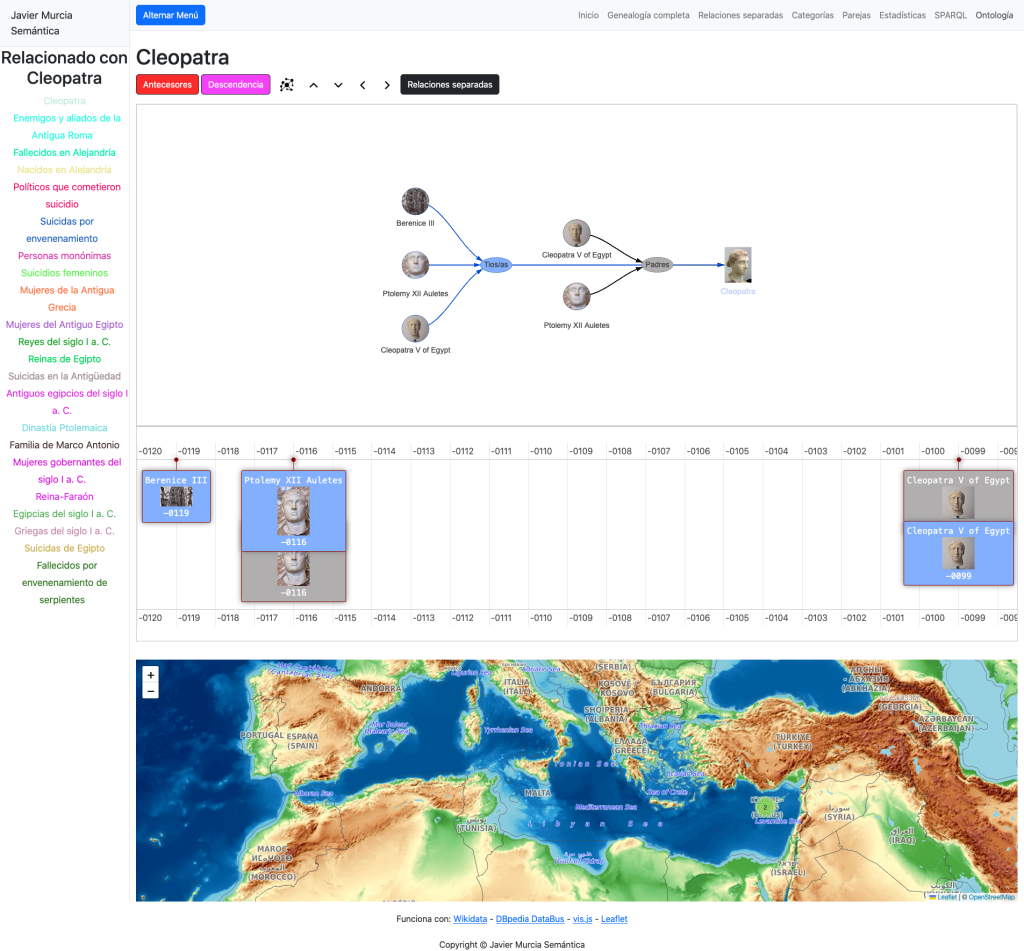
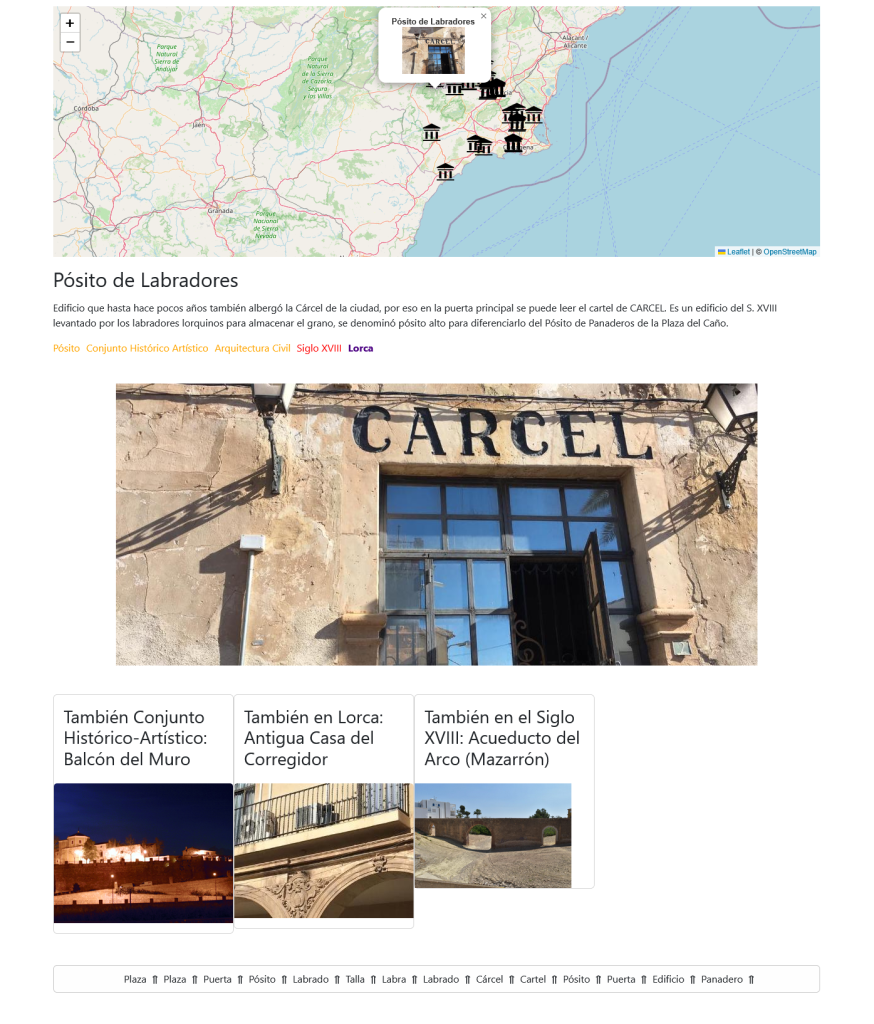
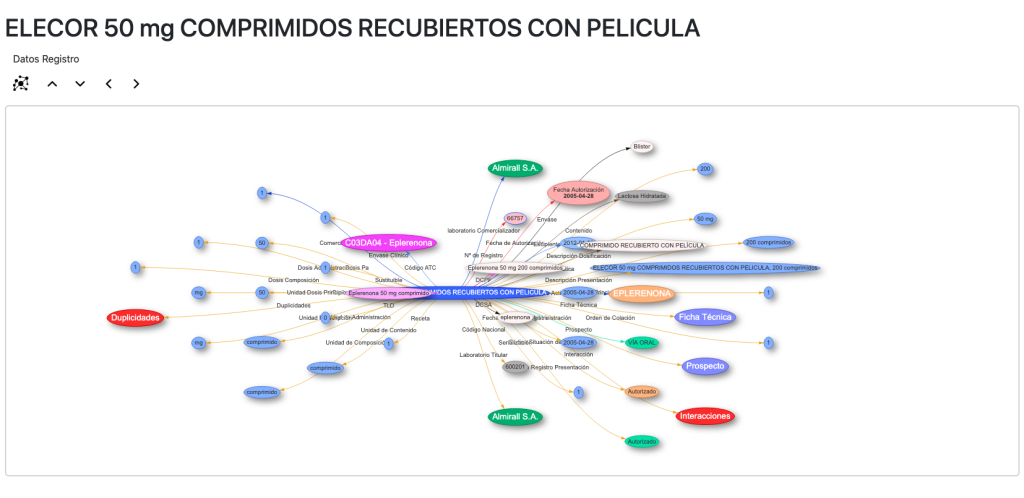
Si seleccionamos cualquier medicamento en la línea de tiempo abrimos una página especial para medicamentos:
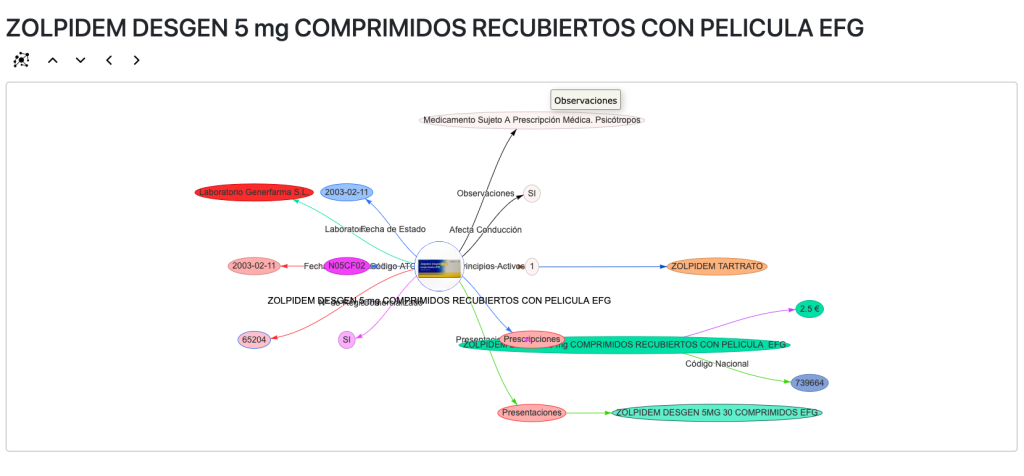
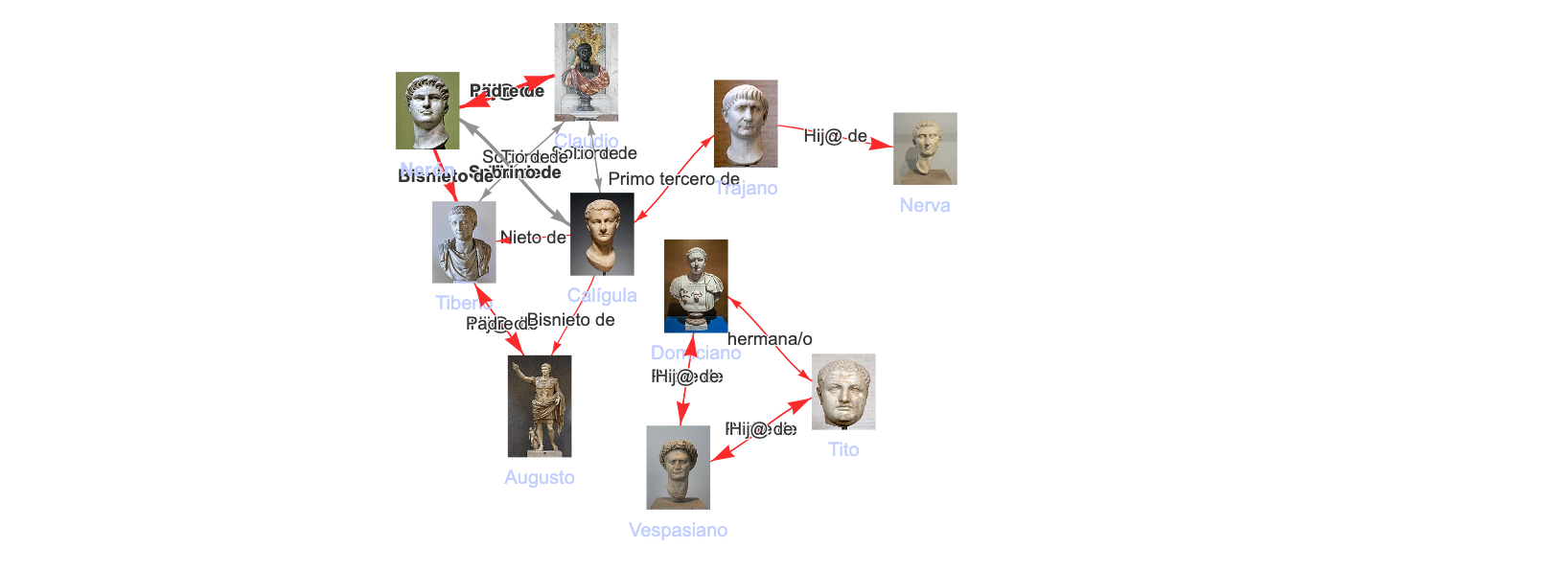
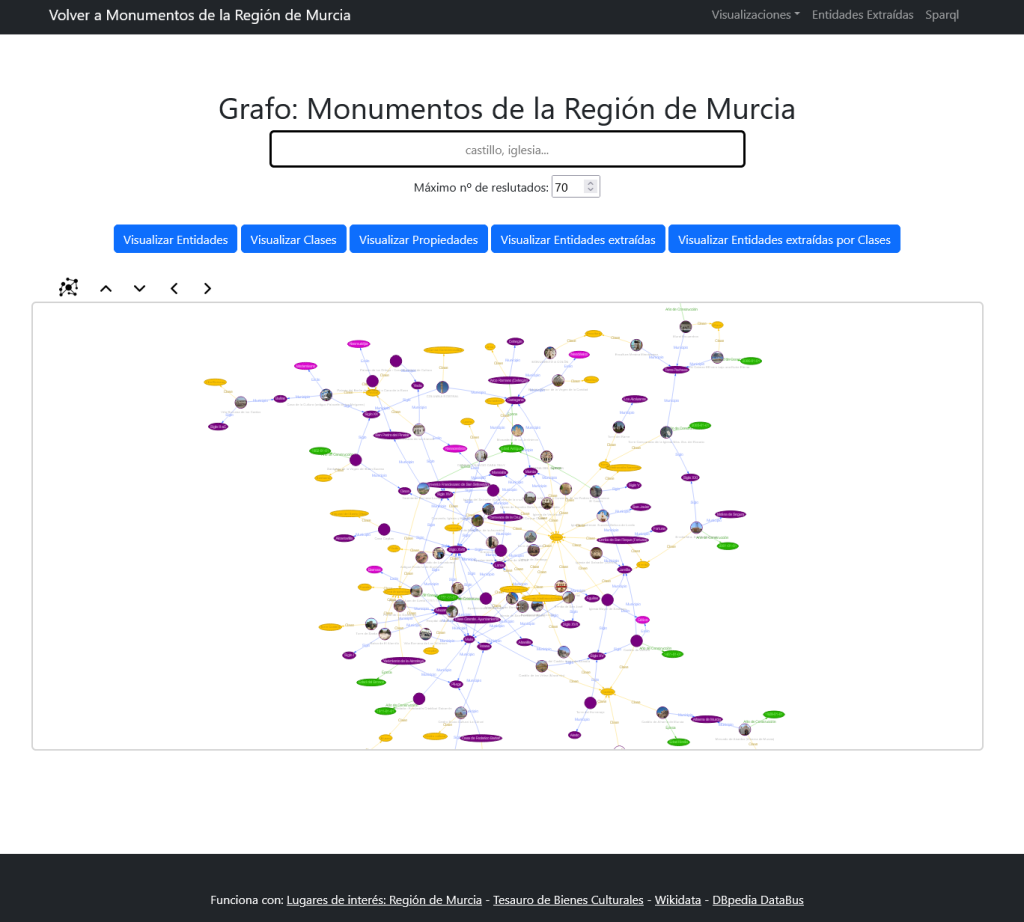
En esta y en las siguientes vistas usamos la librería vis.js para visualizar las entidades y relaciones del grafo y navegamos a través del propio grafo haciendo clic en ellas. Podemos cargar los principios activos del medicamento, las prescripciones, los códigos ATC, etc.
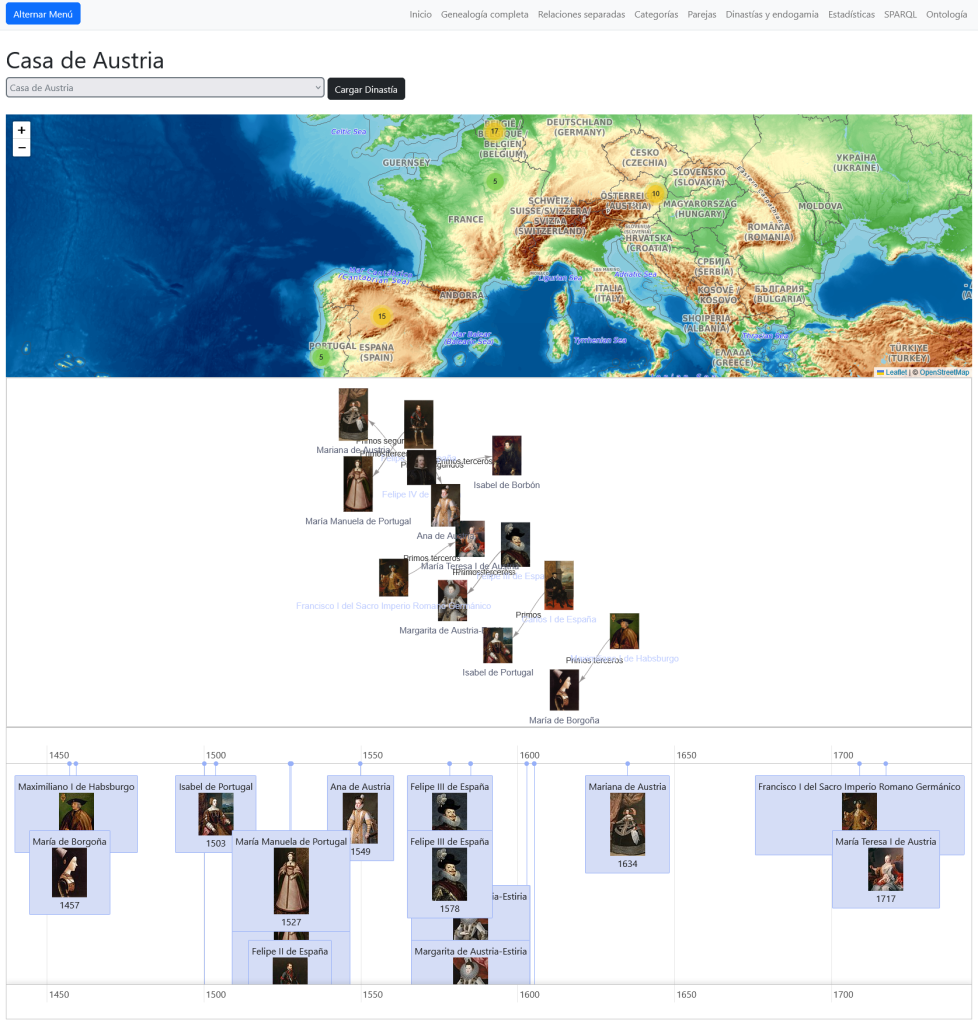
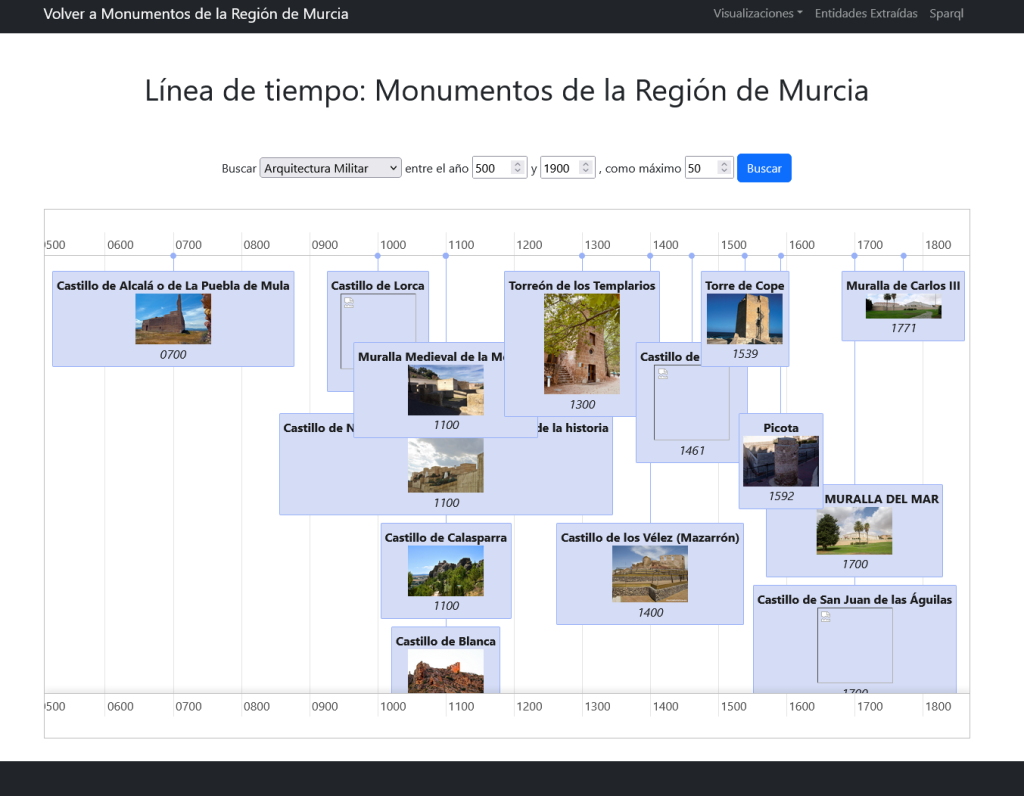
Tenemos una vista donde desplegar medicamentos en una linea de tiempo por fecha de autorización:
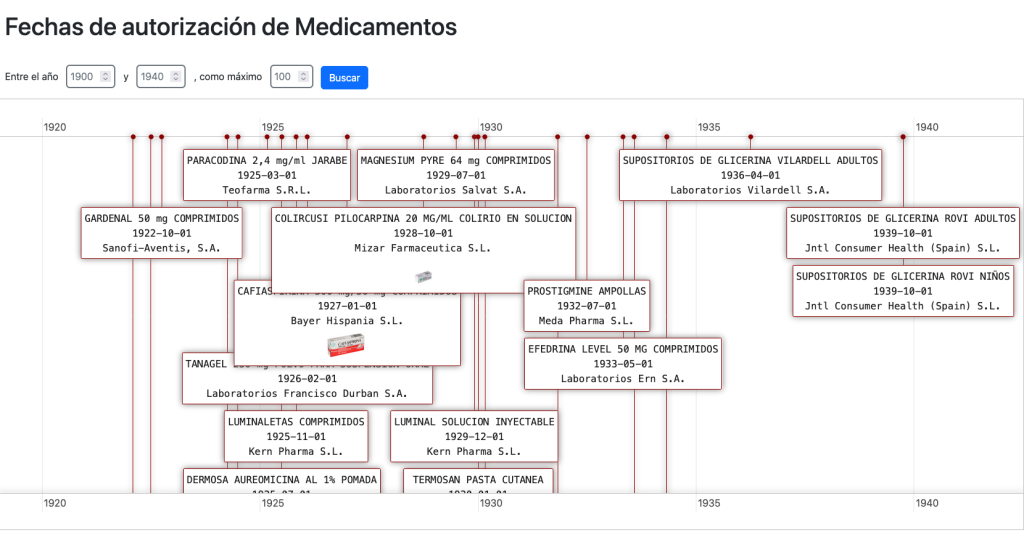
…una forma de visualizar la historia de la farmacología.
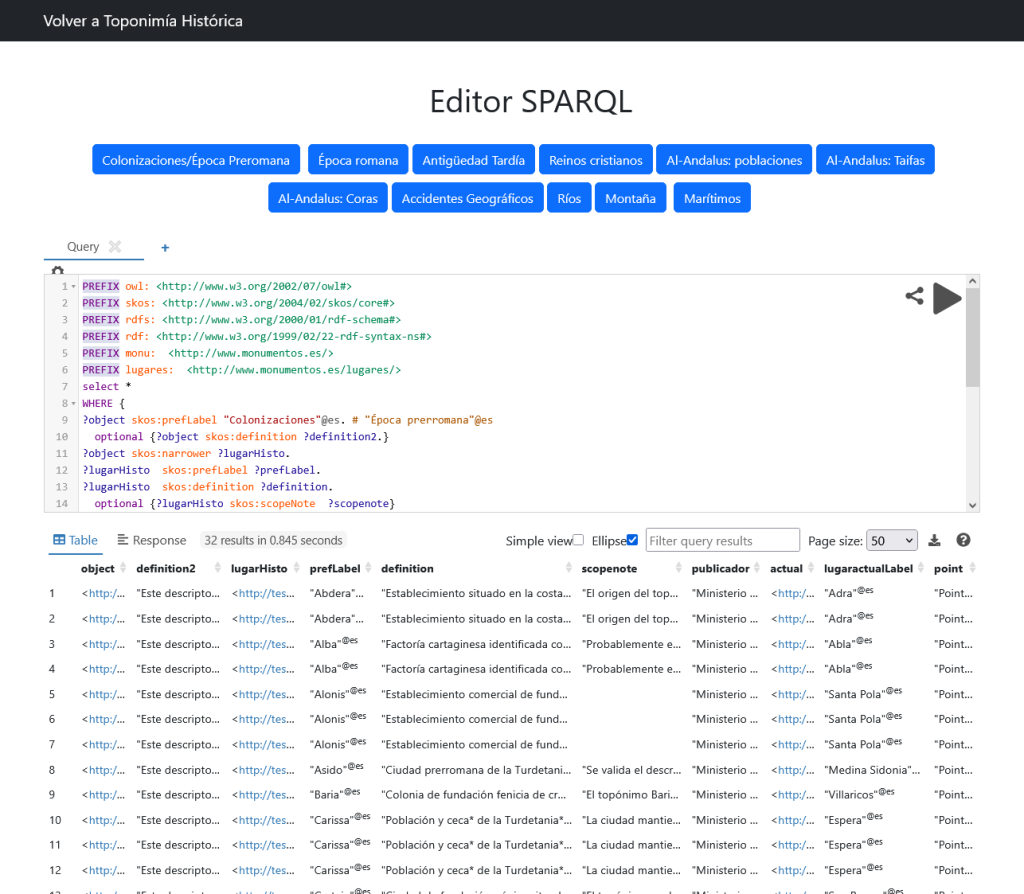
En la vista Prescripciones se pueden visualizar todas las propiedades de la base de datos Nomenclátor de Prescripciones, y por supuesto muchos de sus nodos son navegables y abren otras vistas:
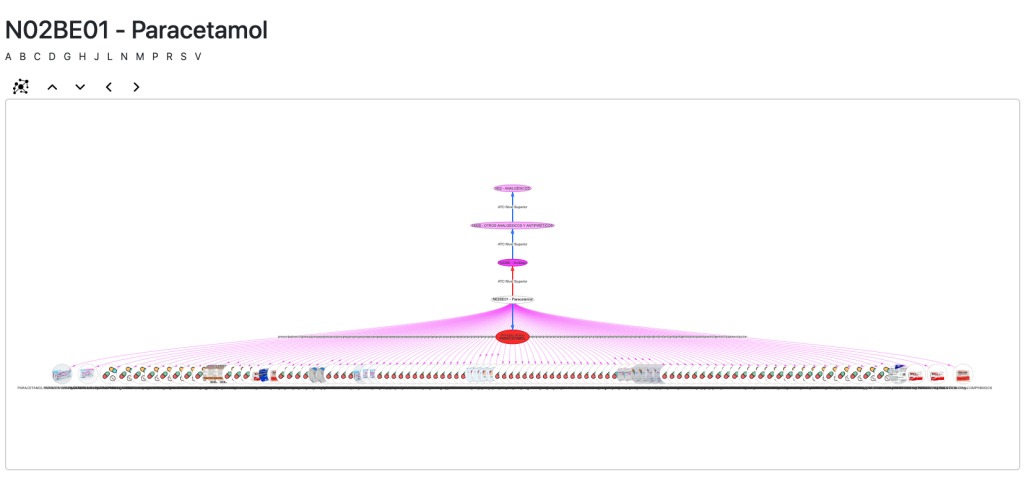
La vista ATC es particularmente interesante pues podemos navegar por sus jerarquías de códigos a los que se añaden los principios activos y los medicamentos cuando están vinculados:

La vista para los principios activos es muy completa. En ella tenemos una descripción, si está disponible y navegación a través de los nodos a a los códigos ATC, clases de sustancia a la que pertenece y enfermedades para las que sirve como tratamiento.

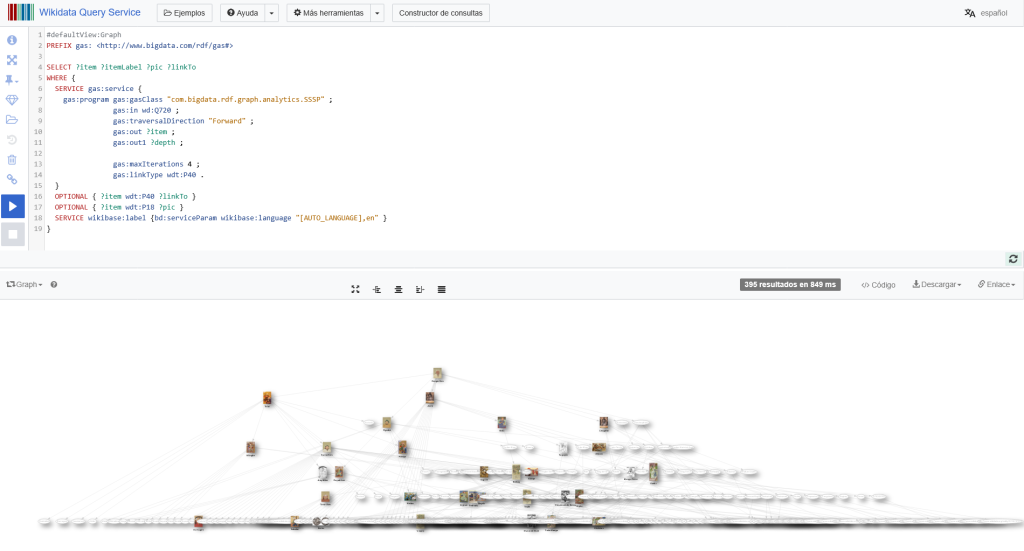
Tenemos también acceso a las posibles interacciones, medicamentos y prescripciones para ese principio activo. Igualmente podemos acceder a nuestro grafo de contexto para ese principio activo (Wikidata):
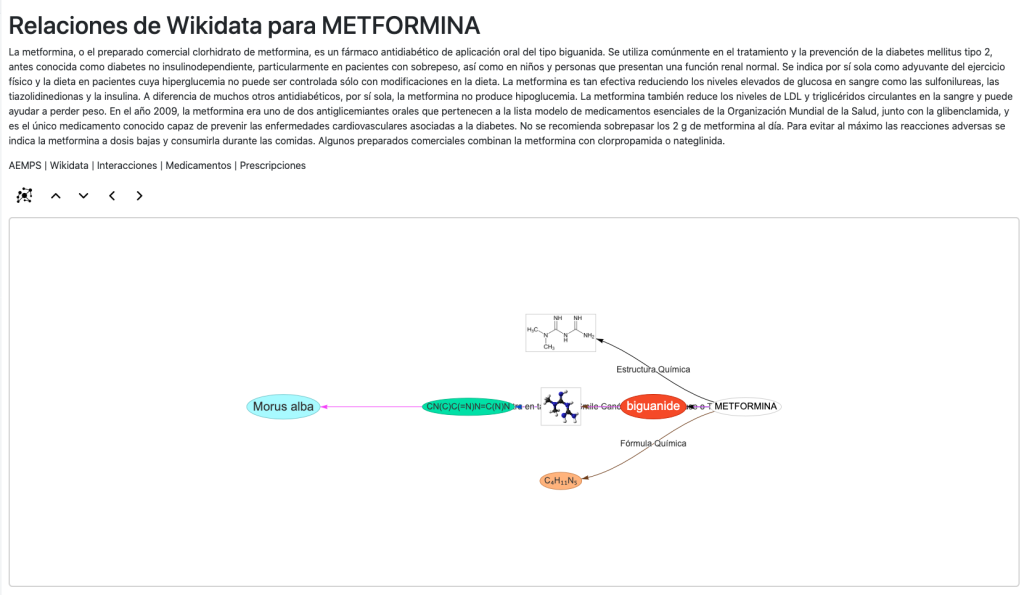
Además contamos con una vista propia para las interacciones:

Y otra para duplicidades:
Contamos con una vista para las enfermedades, con doble visualización de datos: tanto de Dbpedia como de Wikidata y tenemos navegación por categorías de enfermedades en el panel lateral.

Poseemos vistas para Taxones, Biomarcadores y Genes que aparecen con asiduidad en las relaciones de enfermedades, principios activos…
Verificación
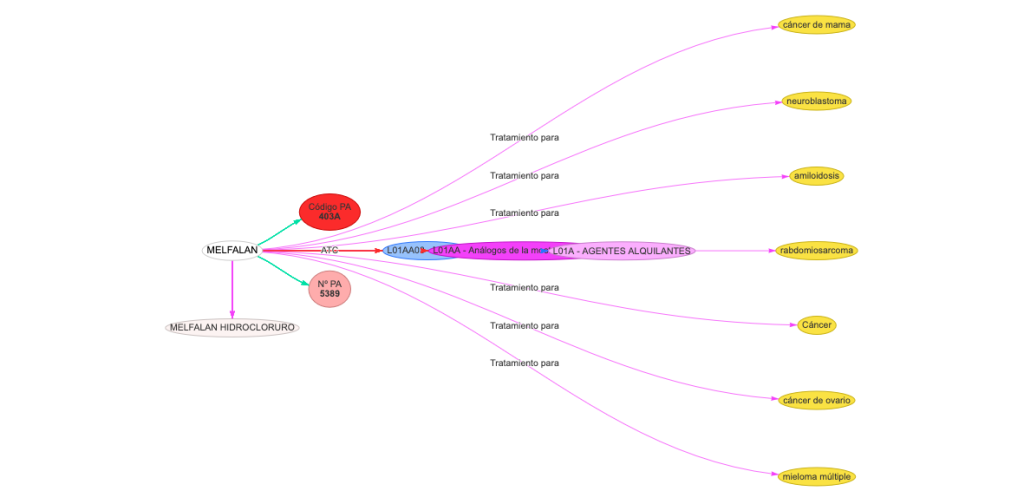
Una prueba de verificación de que las deducciones realizadas han sido acertadas es la comparación entre la ficha técnica de un medicamento y la propiedad «tratamiento para» de su principio activo. Siendo el resultado altamente satisfactorio.

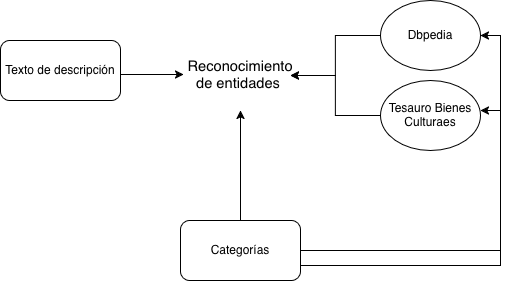
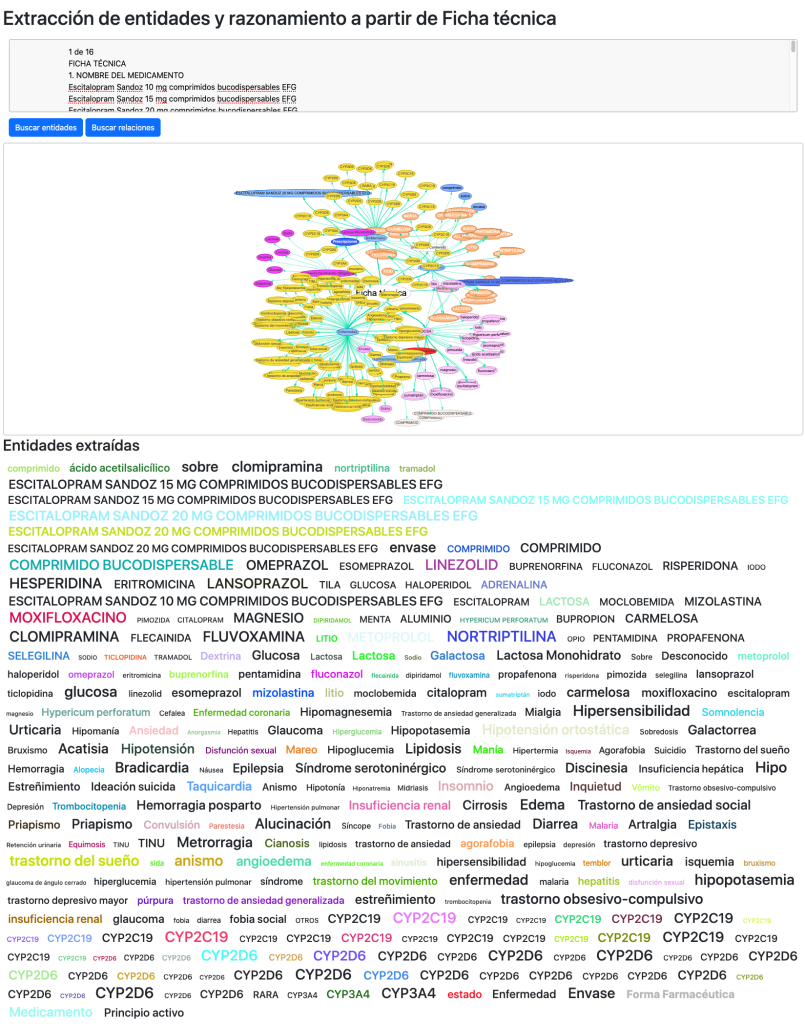
Otro de los test que realizo para comprobar la completitud y capacidad del grafo se muestra en la sección extracción de entidades y razonamiento, donde a partir de una ficha técnica oficial de un medicamento, reconocemos y extraemos entidades gracias al grafo o bien extraemos entidades y las confrontamos entre sí para buscar relaciones entre ellas.

Reconocimiento de entidades:
Extracción de entidades, propiedades y relaciones:
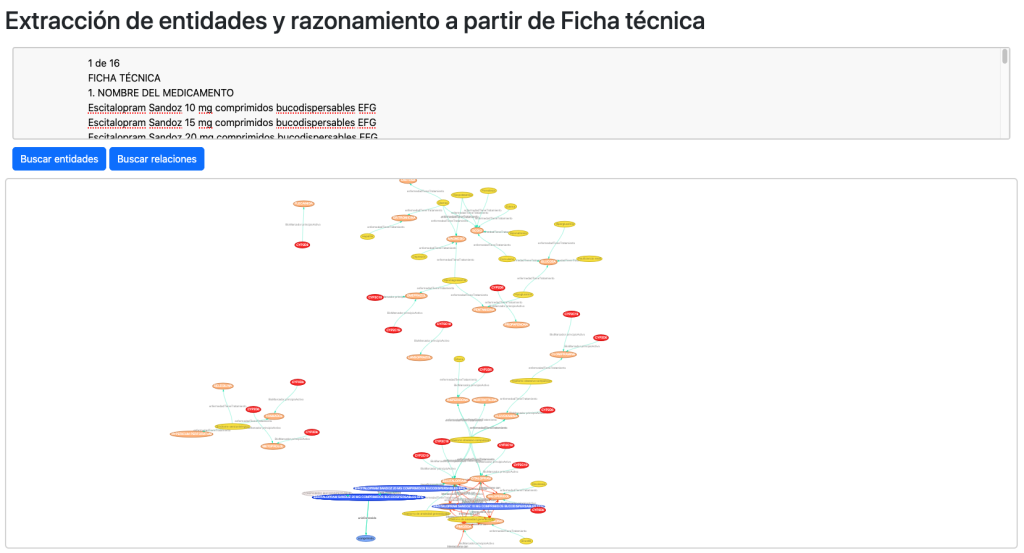
Los resultados son positivos, reconociendo de una única ficha técnica 380 entidades y 131 relaciones relevantes.
Validación con IA Generativa (RAG)
(Knowledge Graph como capa de razonamiento para LLMs)
Realicé un experimento de Retrieval-Augmented Generation (RAG) con el grafo.
- Presento una ficha técnica plana a un LLM (Gemini/ChatGPT).
- Después Presenté la misma ficha enriquecida con las entidades y relaciones extraídas a partir de mi grafo (CSV estructurado).
Les paso el resultado en csv de la consulta al grafo de medicamentos que extrae entidades y relaciones de la misma ficha técnica que antes les presenté, explicando de que se trata el csv, su estructura y pidiendo que lo usen junto a la ficha para explicar y extraer nuevas conclusiones.
Resultado: Los modelos fueron capaces de explicar contraindicaciones y mecanismos de acción con mucha mayor precisión y contexto biológico al disponer de los datos estructurados del grafo. Esto valida el uso de HealthKG como base de conocimiento para asistentes clínicos inteligentes.
- El grafo añade relaciones nuevas
- El grafo actúa como “ground truth”
Futuras mejoras
- Incorporación de SnomedCT.
- Conversión e inclusión de los productos sanitarios y los medicamentos veterinarios de la AEMPS.
- Vinculación de otros grafos biológicos para la configuración de un ecosistema de consulta e investigación.
- Desarrollo de un sistema RAG sistemático.
- Incorporación de pathways.
El Grafo en Cifras
- 3.7 Millones de tripletas generadas.
- 169 Millones de tripletas de contexto biológico integradas.
- 20.000+ Enfermedades catalogadas.
- 2.700+ Interacciones farmacológicas modeladas.
| med:ATC | 7.049 |
| med:BioMarcador | 267 |
| med:DCP | 6.657 |
| med:DCPF | 9.882 |
| med:DCSA | 2.358 |
| med:Duplicidad | 1.658 |
| med:Enfermedad | 20.301 |
| med:Envase | 50 |
| med:ExcipienteDeclObligatoria | 558 |
| med:FormaFarmaceutica | 259 |
| med:FormaFarmaceuticaSimplificada | 72 |
| med:Interacción | 2.763 |
| med:Laboratorio | 1.498 |
| med:Medicamento | 25.792 |
| med:MedicamentoPresentación | 20.296 |
| med:Prescripción | 29.377 |
| med:PrincipioActivo | 3.167 |
| med:SituaciónRegistro | 3 |
| med:UnidadContenido | 56 |
| med:ViaAdministracion | 57 |
| Triples Totales | 3.751.788 |
| Grafo de contexto biológico | 169.374.083 |
Capacidades utilizadas en el proyecto
- Diseño de ontologías de dominio complejo.
- Transformación de datos institucionales a RDF.
- Entity linking a gran escala.
- Construcción de grafos de conocimiento sanitarios.
- Inferencia semántica y razonamiento.
- Integración KG + LLM.
- Desarrollo de front-ends semánticos.