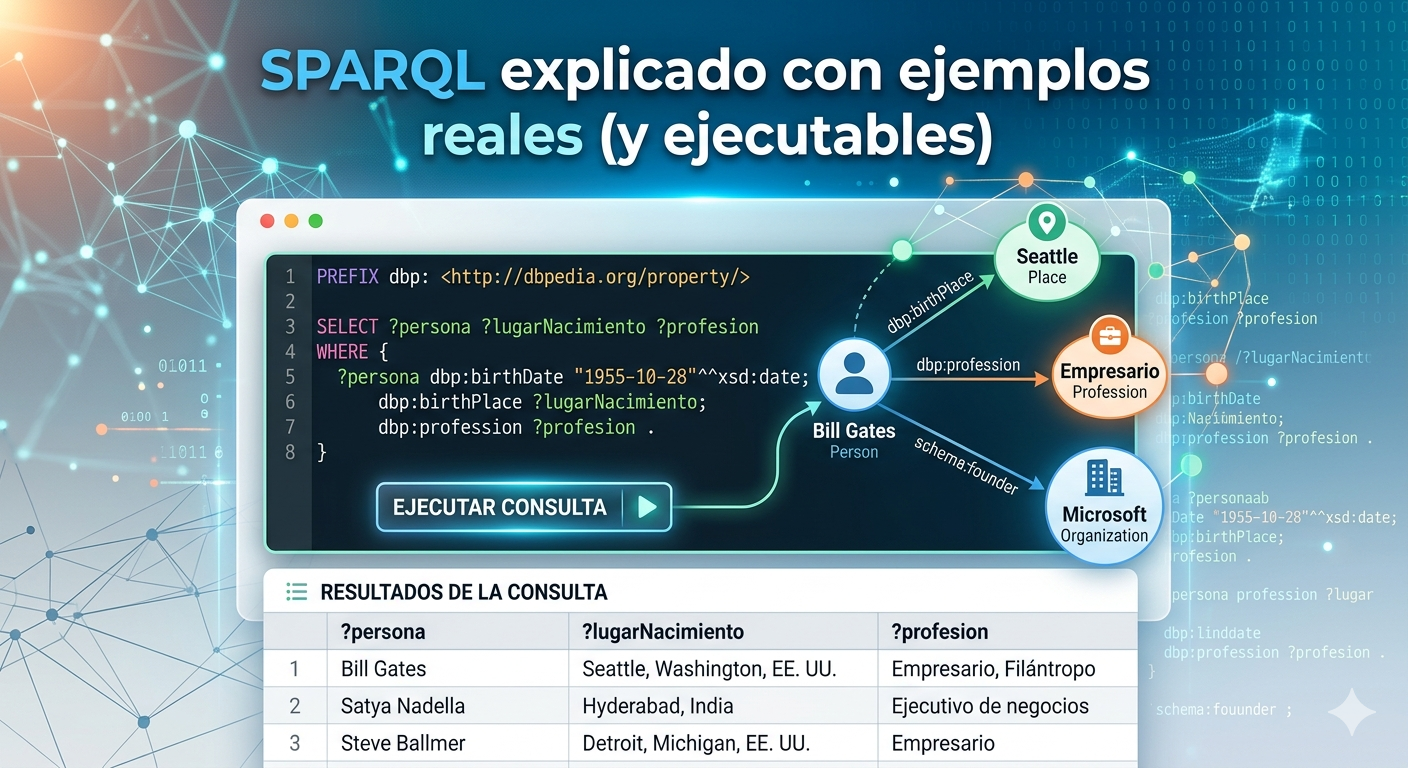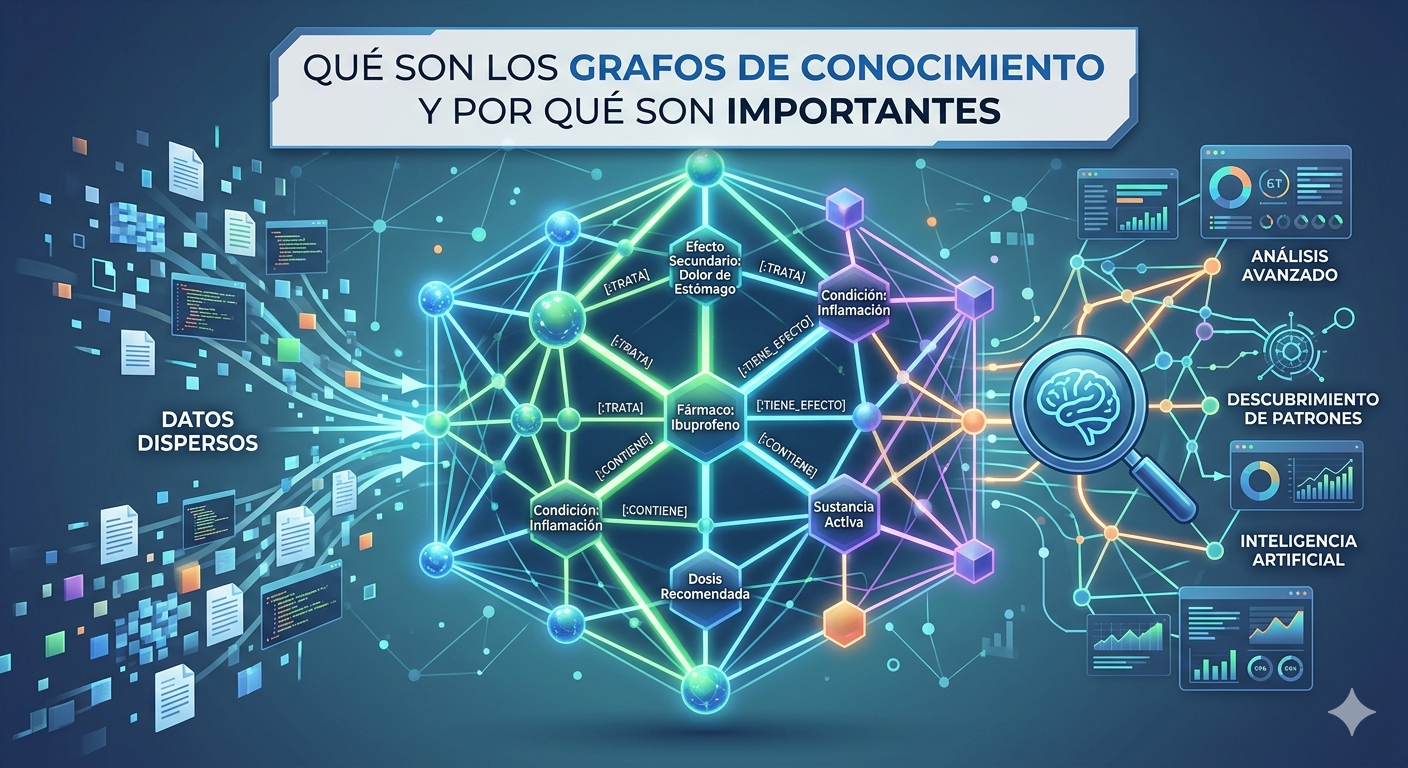
En la era de la Inteligencia Artificial y el Big Data, estructurar la información no es suficiente; necesitamos que las máquinas entiendan el significado de esa información. Aquí es donde entra en juego la creación de ontologías, la piedra angular de la Web Semántica y de los sistemas modernos de toma de decisiones.
Si alguna vez te has preguntado cómo dar el salto de una base de datos tradicional a un modelo de conocimiento capaz de razonar por sí mismo, estás en el lugar correcto. En esta guía práctica analizaremos qué es una ontología, cómo representarla utilizando el estándar OWL (Ontology Web Language) y cómo empezar a modelar hoy mismo utilizando Protégé, la herramienta líder del sector.
¿Qué es una Ontología en Informática?
En ciencias de la computación, una ontología es un modelo conceptual que define formalmente las relaciones entre los elementos de un dominio específico. A diferencia de un esquema de base de datos relacional (que solo define tablas y columnas), una ontología define:
- Clases (Conceptos): Las categorías de objetos en tu dominio (ej.
Persona,Organización,Medicamento). - Propiedades (Relaciones): Cómo se conectan estas clases entre sí (ej.
esEmpleadoDe,recetaPara). - Individuos (Instancias): Los datos reales que pueblan el modelo (ej.
Juan,Google,Aspirina). - Reglas y Axiomas: Las leyes lógicas que rigen el dominio (ej. «Toda persona tiene exactamente un padre biológico»).
La gran ventaja de las ontologías es que son autodescriptivas y extensibles. Permiten que diferentes sistemas compartan un vocabulario común sin perder el contexto semántico.
OWL (Ontology Web Language): El Estándar de la Web Semántica
Para que una ontología sea legible por cualquier máquina en el mundo, debe escribirse en un lenguaje estandarizado. El consorcio W3C definió para esto OWL (Ontology Web Language).
OWL se basa en la lógica de descripción y se apoya en tecnologías como RDF y XML. Una de sus mayores virtudes es que permite definir restricciones muy complejas sobre las propiedades, lo que habilita el razonamiento automático.
Características clave de las propiedades en OWL:
- Propiedades Transitivas: está relacionado con a través de la propiedad , y está relacionado con a través de , entonces el sistema infiere automáticamente que está relacionado con a través de .
- Propiedades Inversas: Si definimos que
esHijoDees la inversa deesPadreDe, al declarar que «Juan esHijoDe Pedro», el sistema deduce inmediatamente que «Pedro esPadreDe Juan». - Propiedades Simétricas: Si es cónyuge de , entonces es cónyuge de .
Estas restricciones son las que permiten realizar proyectos de inferencia masiva (como el que desarrollé para deducir la genealogía de 1 millón de personas utilizando Wikidata).
Protégé: El Entorno de Desarrollo para Ontologías
Aunque podrías escribir código OWL directamente a mano, el estándar es extremadamente denso. En el mundo profesional, la herramienta estándar de facto para diseñar ontologías de forma visual es Protégé, un software de código abierto desarrollado por la Universidad de Stanford.
Protégé proporciona una interfaz gráfica intuitiva para gestionar la jerarquía de clases, definir propiedades, aplicar restricciones lógicas y, lo más importante, ejecutar razonadores lógicos (como HermiT o Pellet) para comprobar que tu ontología no contiene contradicciones.
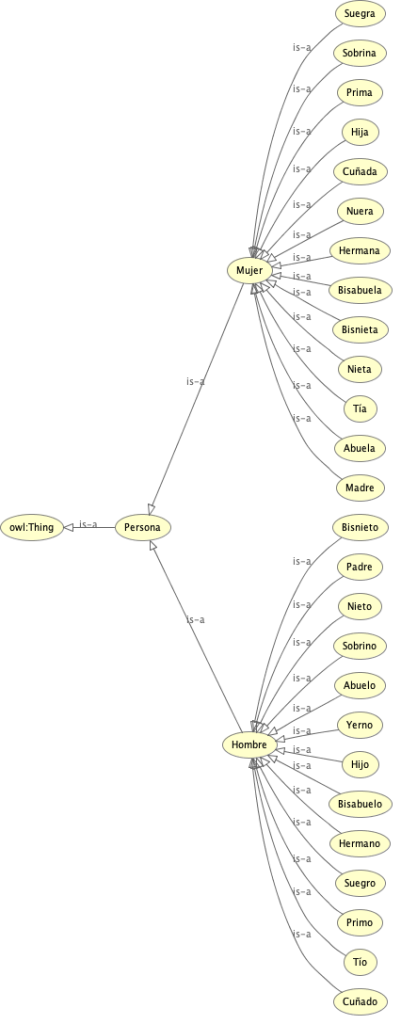
Guía Paso a Paso: Tu primera ontología en Protégé
Para ilustrar el proceso, modelaremos una versión simplificada de un sistema de relaciones familiares utilizando Protégé:
Paso 1: Definir las Clases (La taxonomía)
Al abrir Protégé, lo primero que haremos será definir nuestra jerarquía de clases en la pestaña Entities / Classes.
- Creamos la clase raíz
Persona. - Bajo
Persona, creamos dos subclases disjuntas (que no pueden solaparse):HombreyMujer.
Paso 2: Crear las Propiedades (Object Properties)
Las propiedades de objeto definen relaciones entre instancias de clases. En la pestaña Object Properties:
- Creamos la relación
tienePadre. - Definimos su Domain (Dominio):
Persona(quién puede tener padre). - Definimos su Range (Rango):
Hombre(el padre debe ser un hombre). - Creamos la propiedad inversa
esPadreDey la vinculamos como Inverse Of detienePadre.
Paso 3: Definir Características Avanzadas
Para dotar a nuestra ontología de capacidad de razonamiento:
- Creamos la propiedad
esHermanoDe. La marcamos como Symmetric (si Juan es hermano de Pedro, Pedro lo es de Juan). - Creamos la propiedad
esAncestroDey la marcamos como Transitive (si eres ancestro de tu hijo, y tu hijo de tu nieto, tú eres ancestro de tu nieto).
Paso 4: Ejecutar el Razonador (Reasoner)
Una de las herramientas más potentes de Protégé es el menú Reasoner. Al seleccionar un motor como HermiT e iniciarlo (Start Reasoner), el software analizará toda la lógica de nuestra ontología. Si hemos cometido un error de diseño (por ejemplo, decir que alguien es hombre y mujer a la vez, siendo clases disjuntas), el razonador marcará la inconsistencia en rojo para que podamos corregirla antes de llevar la ontología a producción.
Conclusión: El valor de un buen modelo semántico
La creación de ontologías con OWL y herramientas como Protégé es el primer paso crítico para cualquier proyecto de datos inteligente. Sin un modelo conceptual claro y robusto, es imposible entrenar algoritmos de IA simbólica o estructurar datos a gran escala de manera coherente.
¿Estás pensando en migrar tus datos a un grafo de conocimiento? Diseñar una ontología ineficiente puede ralentizar tus consultas o generar deducciones incorrectas. Si necesitas ayuda para modelar el dominio de tu negocio, optimizar ontologías en OWL o integrar motores de razonamiento lógico en tu infraestructura, puedes contactar conmigo para diseñar una solución semántica a tu medida.