Este proyecto no consiste en consultar genealogías existentes, sino en construir una genealogía ampliada a gran escala mediante inferencia semántica, partiendo de un conjunto mínimo de relaciones primitivas.
A partir de la propiedad P40 (hijo o hija)de Wikidata se genera, mediante reglas formales, un espacio completo de parentesco: padres, abuelos, tíos, sobrinos, primos, suegros, bisabuelos, etc.
Diseñé un sistema de inferencia genealógica capaz de expandir automáticamente el conocimiento familiar de casi un millón de personas, generando decenas de millones de nuevas relaciones semánticas de forma consistente.
El Desafío: Datos incompletos
En Wikidata hay casi un millón de entidades que son seres humanos y que además tienen hijos. A partir de la propiedad P40, hijo o hija, podemos usarla como propiedad primitiva de la que deducir todas las demás. Wikidata dice quién es hijo de quién, pero no quién es primo de quién.
Explosión Combinatoria Controlada
Lo más impresionante de este proyecto no es tener 1 millón de personas, sino calcular relaciones tan alejadas como primos terceros. La cantidad de relaciones crece exponencialmente.
El reto fue gestionar la explosión combinatoria. Calcular relaciones de primer grado es trivial. Calcular relaciones de sexto grado (primos terceros) en un grafo de 1 millón de nodos requiere una estrategia de inferencia optimizada para no colapsar la memoria.
Modelado Ontológico
El primer paso fue crear una ontología minimalista que reflejara los tipos y propiedades fundamentales que rigen las relaciones familiares y genealógicas:
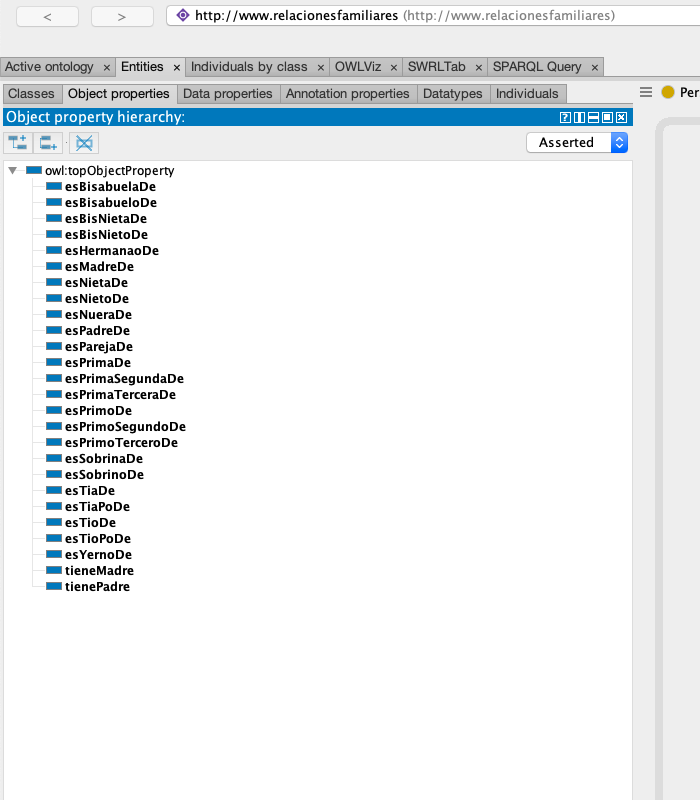
Diseñé una ontología ligera (lite ontology) para maximizar el rendimiento de las consultas, mapeando las propiedades complejas de Wikidata a un esquema simplificado pero transitivo.
Seguidamente generamos y descargamos el dump de Wikidata utilizando Wdumper, para ello se seleccionan las entidades que tienen la propiedad P40, aproximadamente un millón.
Una vez en nuestro poder, se procede a la carga en una TDB2 de Apache Jena Fuseki y comenzamos el proceso de conversión de tipos. Convertimos los tipos básicos de Wikidata a nuestra ontología:
| Q5 (Humano) | fami:Persona |
| Q6581097 (masculino) | fami:Hombre |
| Q6581072 (femenino) | fami:Mujer |
| P22 (padre) | fami:tienePadre |
| P25 (madre) | fami:tieneMadre |
| P3373 (hermano o hermana) | fami:esHermanaoDe |
| P26 (cónyuge) | fami:esParejaDe |
| P40 (hijo o hija) | fami:esPadreDe fami:esMadreDe |
Ahora ya estamos en disposición de utilizar reglas de inferencia o deducción, para a partir de estas relaciones primitivas, deducir todas las demás.
La Estrategia de Inferencia
La Lógica de Inferencia
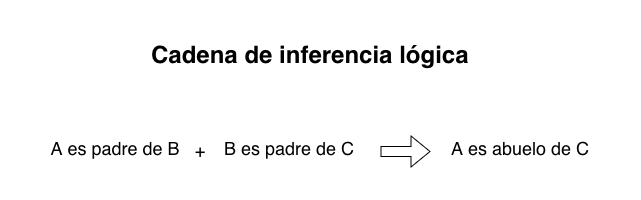
Para deducir relaciones complejas, descompusimos los vínculos familiares en reglas lógicas basadas en cláusulas de Horn. Por ejemplo, la regla para deducir a una «Tía Materna» se define conceptualmente así:
Mujer(a)∧Hermana(a,b)∧Madre(b,c)→Tía(a,c)
Traducción: Si A es mujer, y A es hermana de B, y B es madre de C; entonces A es tía de C.
Implementación
dato → modelo → conocimiento inducido
Inicialmente, implementé un motor de inferencia basado en reglas (Jena Rules) ejecutado en memoria.Tenemos a nuestra disposición, de este modo, un sistema muy completo y robusto para elaborar las inferencias que deseo:
[TíaDeHermana: (?a rdf:type fami:Mujer), (?a fami:esHermanaoDe ?b), (?b fami:esMadreDe ?c) -> (?a fami:esTiaDe ?c),(?c rdf:type fami:Tía )
]Lenguaje del código: JSON / JSON con comentarios (json)Este tipo de reglas funcionan muy bien y resulta muy interesante experimentar con ellas y observar como en cada consulta se generan los nuevos nodos para concluir la inferencia. Pero por desgracia todo ocurre en memoria y sólo resulta útil para pequeñas cantidades de datos. Sin embargo, dada la magnitud del grafo (1 millón de nodos semilla), el consumo de RAM se volvió insostenible.
Para solucionar este cuello de botella, re diseñé la arquitectura de inferencia trasladando la lógica a la base de datos mediante inserciones constructivas SPARQL en cascada. Esto permitió procesar relaciones complejas (hasta primos terceros) persistiendo los datos en disco paso a paso, garantizando la estabilidad del sistema.
La solución, por tanto, fue transformar cada regla lógica en una operación SPARQL de materialización del conocimiento, convirtiendo el razonamiento dinámico en conocimiento persistente dentro del grafo. Esta estructura permite realizar inserciones masivas en la base de datos de manera eficiente.
A continuación, el script utilizado para inferir la relación fami:esTiaDe:
# Regla de Inferencia: Tía Materna
# Objetivo: Deducir tías basándonos en la relación de hermandad y maternidad.
PREFIX rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#>
PREFIX fami: <http://www.relacionesfamiliares/>
INSERT {
# La Inferencia (Lo que el grafo aprende)
?a fami:esTiaDe ?c .
?a rdf:type fami:Tía .
}
WHERE {
# Las Condiciones (Lo que el grafo ya sabe)
?a rdf:type fami:Mujer . # 1. 'a' debe ser mujer
?a fami:esHermanaoDe ?b . # 2. 'a' es hermana de 'b'
?b fami:esMadreDe ?c . # 3. 'b' es madre de 'c' (el sobrino/a)
}Lenguaje del código: PHP (php)
Diseñé una ejecución en cascada (Batch Processing) donde las reglas se ejecutan en un orden estricto, de tal modo que las posteriores basen sus deducciones en las propiedades anteriores:
- Nivel 1: Padres e Hijos (Datos crudos).
- Nivel 2: Hermanos y Parejas (Inferidos del Nivel 1).
- Nivel 3: Tíos, Abuelos y Nietos (Inferidos del Nivel 2).
- Nivel 4: Primos y Primos Segundos (Inferidos del Nivel 3).
El sistema transforma un conjunto mínimo de hechos biográficos en una estructura de parentesco completa, haciendo explícitas relaciones que no existían en los datos originales.
El uso del sistema de reglas de Jena fue una prueba conceptual. Demostró que el modelo lógico era correcto, pero no era escalable: las inferencias se realizan en memoria y no pueden sostener un grafo de casi un millón de personas.
Esta arquitectura por capas permitió generar más de 14 millones de nuevas relaciones sin colapsar el servidor, persistiendo cada nuevo descubrimiento permanentemente en el grafo.
Resultados
La relación mas lejana que he podido procesar ha sido la de primo tercero. Aquí un listado de los tipos y propiedades inferidas, y el número de entidades y propiedades generadas:
Tipos:
| fami:Padre | 617.285 |
| fami:Madre | 327.048 |
| fami:Hermano | 48.049 |
| fami:Hermana | 18.577 |
| fami:Tío | 38.047 |
| fami:Tía | 28.027 |
| fami:Sobrino | 30.734 |
| fami:Sobrina | 20.354 |
| fami:Primo | 30.734 |
| fami:Prima | 20.354 |
| fami:Cuñado | 30.001 |
| fami:Cuñada | 27.138 |
| fami:Yerno | 151.513 |
| fami:Nuera | 158.108 |
| fami:Nieto | 259.518 |
| fami:Nieta | 135.589 |
| fami:Abuelo | 290.979 |
| fami:Abuela | 180.322 |
| fami:Bisnieto | 215.671 |
| fami:Bisnieta | 122.790 |
| fami:Bisabuelo | 290.979 |
| fami:Bisabuela | 180.322 |
Propiedades:
| fami:esPadreDe – fami:tienePadre | 1.078.808 |
| fami:esMadreDe – fami:tieneMadre | 674.446 |
| fami:esParejaDe | 521.626 |
| fami:esHermanaoDe | 243.069 |
| fami:esTioDe | 171.313 |
| fami:esTiaDe | 98.030 |
| fami:esTioPoDe | 115.830 |
| fami:esTiaPoDe | 175.045 |
| fami:esSobrinoDe | 77.295 |
| fami:esSobrinaDe | 54.058 |
| fami:esPrimoDe | 306.103 |
| fami:esPrimaDe | 220.748 |
| fami:esPrimoSegundoDe | 567.860 |
| fami:esPrimaSegundaDe | 456.780 |
| fami:esPrimoTerceroDe | 1.368.013 |
| fami:esPrimaTerceraDe | 1.131.703 |
| fami:esCuñadoDe | 83.734 |
| fami:esCuñadaDe | 76.267 |
| fami:esSuegroDe | 367.997 |
| fami:esSuegraDe | 266.293 |
| fami:esYernoDe | 271.422 |
| fami:esNueraDe | 303.845 |
| fami:esAbueloDe | 605.914 |
| fami:esAbuelaDe | 430.228 |
| fami:esNietoDe | 638.119 |
| fami:esNietaDe | 398.027 |
| fami:esBisabueloDe | 1.479.216 |
| fami:esBisabuelaDe | 1.100.983 |
| fami:esBisNietoDe | 804.848 |
| fami:esBisNietaDe | 559.830 |
A partir de menos de un millón de personas y unas pocas propiedades primitivas, el sistema generó más de 40 millones de triples, de los cuales:
- Casi 2 millones son nuevas afirmaciones de clase,
- Más de 14 millones son nuevas relaciones familiares explícitas,
- Alcanzando relaciones de hasta tercer grado de consanguinidad.
Partiendo de 1 millón de relaciones ‘padre/hijo’, el sistema generó más de 14 millones de nuevas relaciones semánticas. Por cada dato explícito, el sistema infirió 14 datos implícitos.
El resultado es un motor de genealogía semántica, capaz de:
- Expandir automáticamente redes familiares,
- Detectar parentescos complejos,
- Validar la coherencia de grupos históricos,
- Cruzar genealogía con tiempo, espacio y categorías culturales.
Propiedades de relaciones familiares presentes en la extracción de Wikidata:
| P22 (tiene padre) | 540.417 |
| P25 (tiene madre) | 335.367 |
| P3373 (hermano hermana) | 161.007 |
| P26 (esposo/a) | 468.102 |
| P40 (tiene hijo/a) | 1.770.308 |
| Total Wikidata | 3.275.201 |
| Total propiedades inferidas | 14.647.450 |
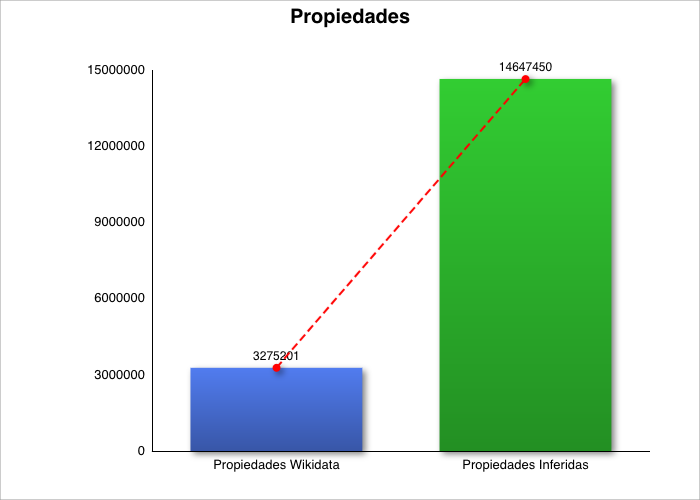
Datos Originales (Wikidata) vs Datos Enriquecidos
La aplicación web: una exploración multidimensional
Para explotar el grafo generado y mostrar sus capacidades ideo una aplicación web basada en grafo centrada en el descubrimiento semántico.
Las vistas cubren cuatro elementos o dimensiones del personaje en cuestión. En la parte superior tenemos las relaciones familiares o genealógicas propiamente dichas:
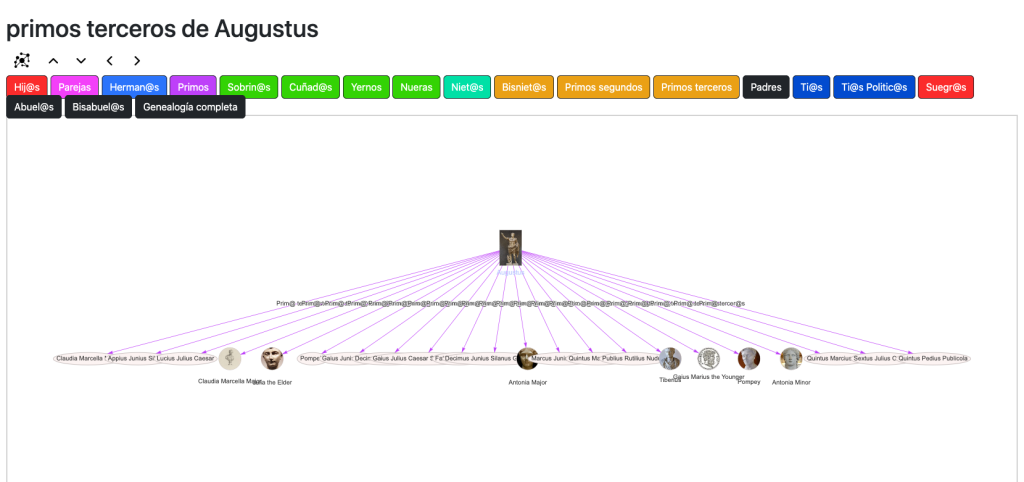
La aplicación no muestra árboles genealógicos estáticos, sino que permite explorar las relaciones familiares desde cuatro dimensiones:
- Parentesco (grafo)
- Tiempo (línea de vida)
- Espacio (mapa)
- Contexto cultural (categorías de Dbpedia)
Debajo de ella, encontramos una línea de tiempo donde se disponen las mismas personas relacionadas según su fecha de nacimiento para visualizar en la dimensión temporal las genealogías.
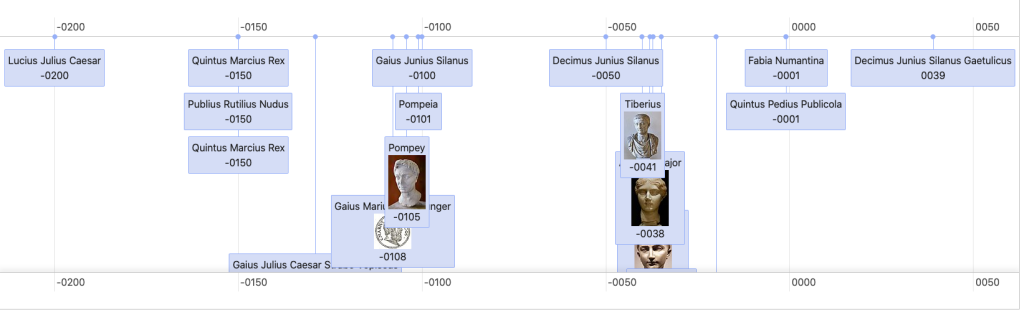
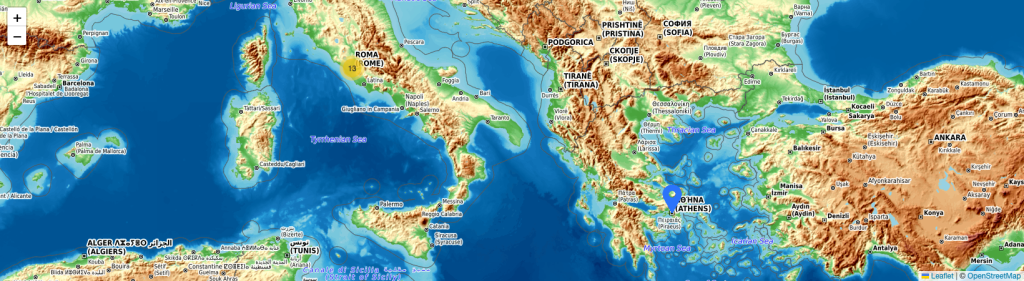
La tercera vista es la geográfica, gracias a una consulta buscamos, si existe, la ciudad de nacimiento de todos los familiares y los ubicamos en una mapa. Conseguimos así seguir las relaciones entre el parentesco y su dispersión geográfica.
Como siempre es posible rizar el rizo y puesto que resulta relativamente sencillo saltar de las entidades de Wikidata a las de Dbpedia, cargamos las categorías a las que pertenece el personaje, si es que tiene:

Categorías que nos sirven para cargar nuevas personas vinculadas a ellas y para abrir una nueva página especial para categorías. En ella se despliegan en un mapa y en una línea de tiempo las personas que pertenecen a ella:
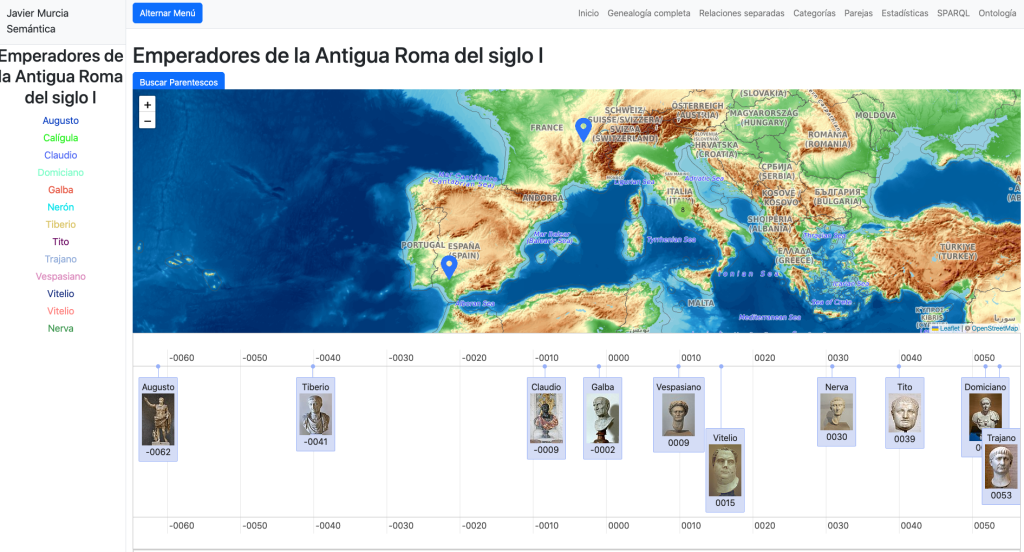
Validación del grafo a través de categorías históricas
Además, las categorías nos sirven para poner en marcha un algoritmo que pone a prueba la exactitud de las inferencias realizadas: Buscar Parentesco, que intenta buscar parentescos familiares entre los miembros de la categoría cargada.
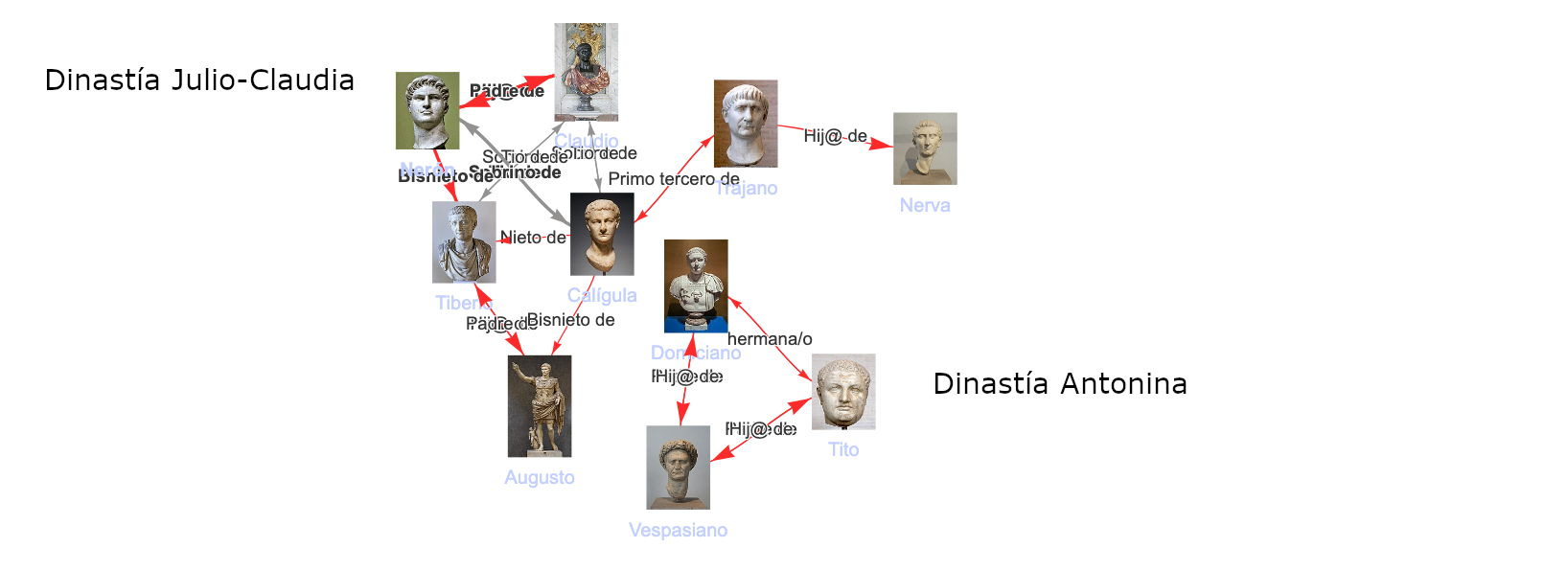
Se trata de un test lógico. El sistema demuestra su corrección cuando detecta automáticamente que los emperadores romanos del siglo I pertenecen a dos dinastías sin vínculo genealógico directo. A través de este y otros ejemplos, conseguimos un caso de validación semántica.
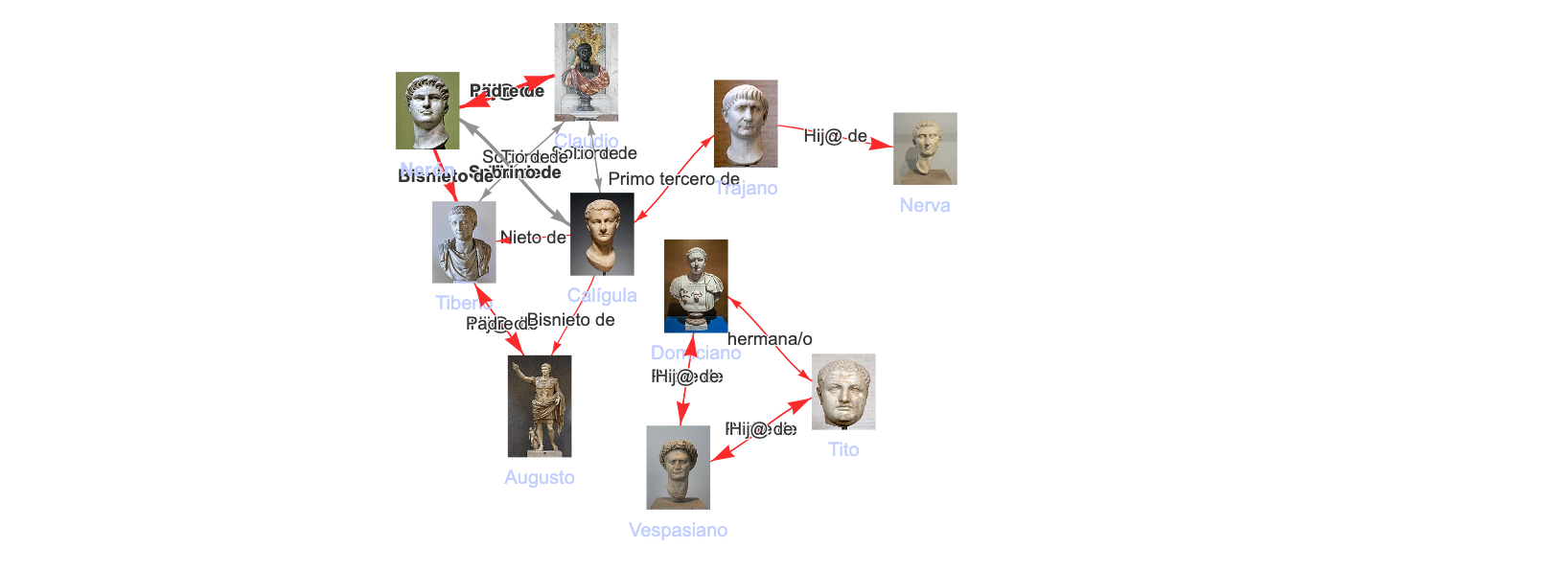
Comprobamos que las inferencias se han ejecutado correctamente puesto que los Emperadores de Roma del siglo I pertenecieron a dos dinastías o familias sin vínculos directos entre ellas, y eso es lo que refleja el algoritmo cuando busca los parentescos:
Mujeres a través de los siglos
Ante el desequilibrio existente entre hombres y mujeres en el grafo. Algo de lo que no podemos culpar a Wikidata sino a nuestra propia cultura. Decido iniciar el proceso de descubrimiento semántico con una página que permite cargar categorías de mujeres por siglos:
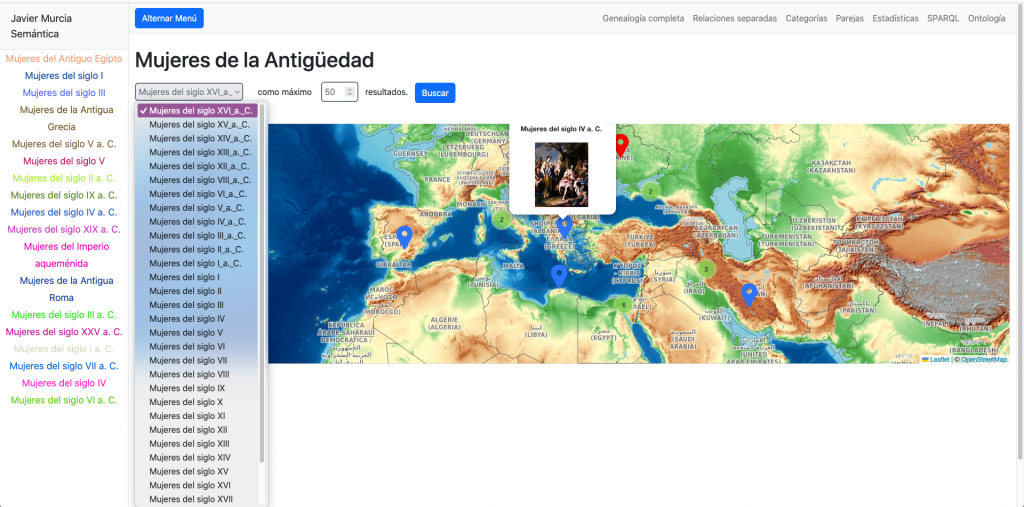
De este modo, el proyecto pone de manifiesto sesgos estructurales en los datos históricos y ofrece herramientas para explorarlos activamente, como la navegación específica por mujeres históricas por siglos.
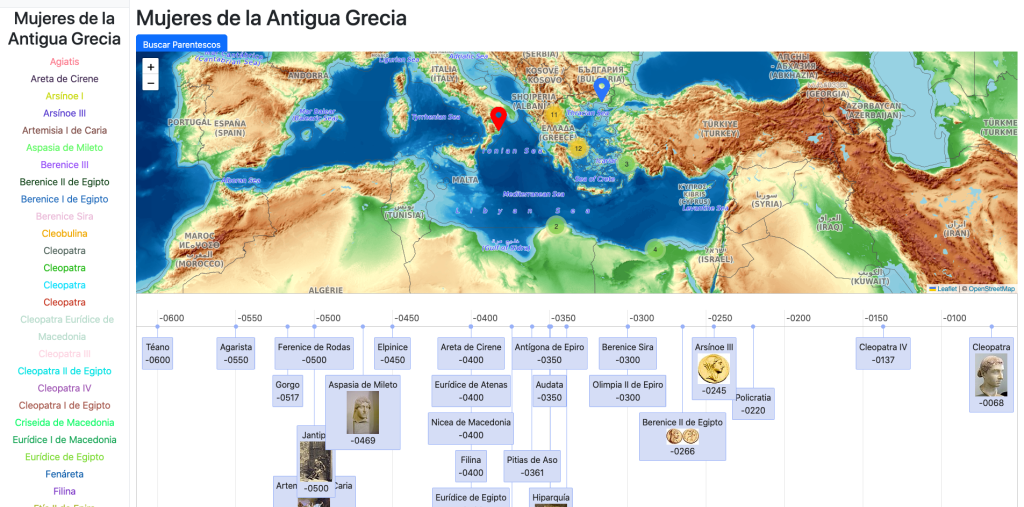
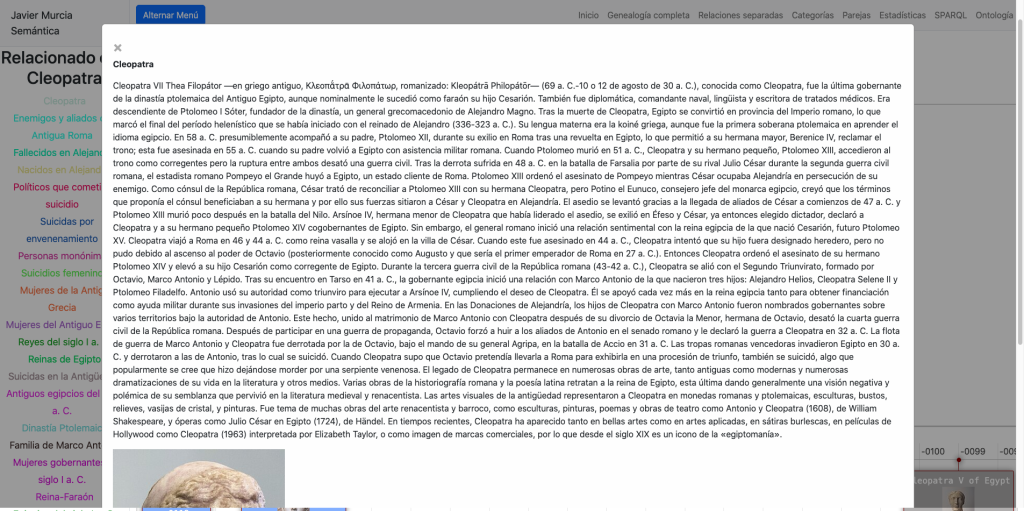
A partir de este inicio de navegación podemos cargar una categoría en concreto como por ejemplo: «Mujeres de la Antigua Grecia«:
Y seguidamente seleccionar una mujer y cargar su genealogía y relaciones familiares en detalle:
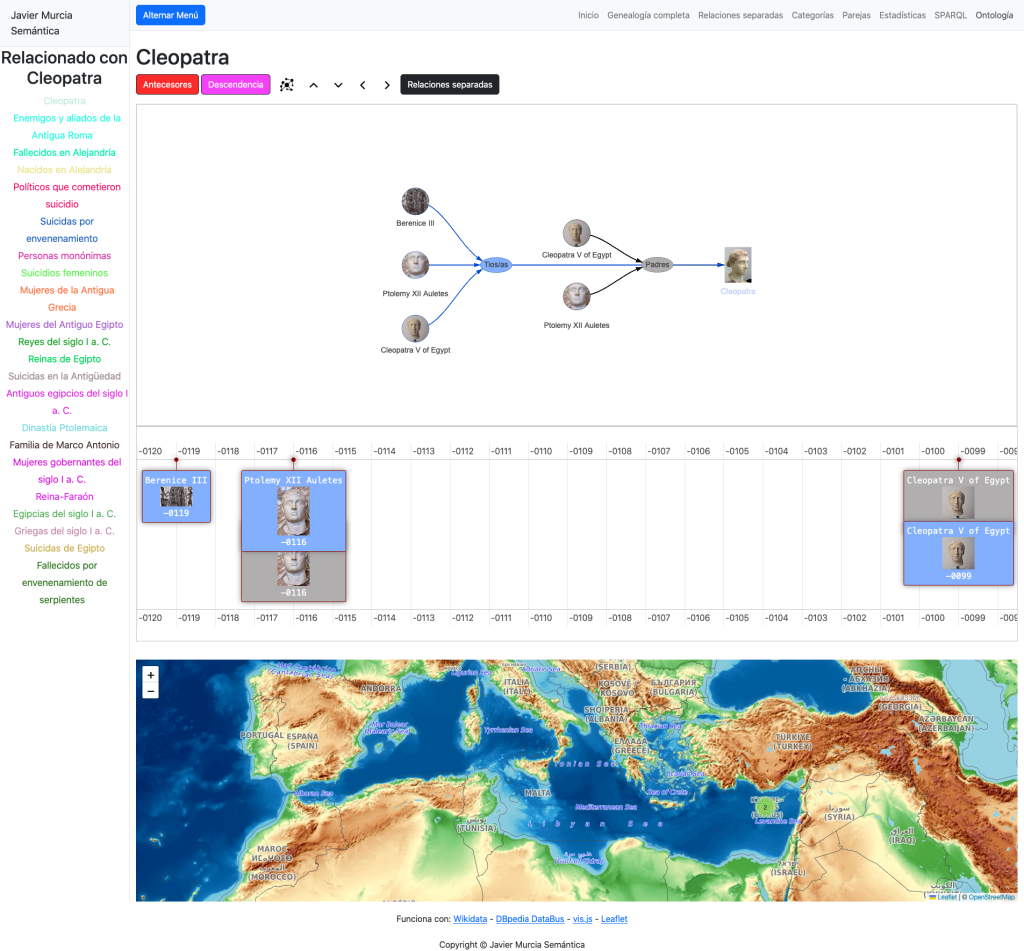
En estas vistas podemos cargar nuevas personas haciendo clic o doble clic así como cargar textos explicativos sobre cada una, extraídos de Dbpedia. De modo que podemos recorrer líneas familiares a través de la historia a golpe de clic, explorando durante horas.
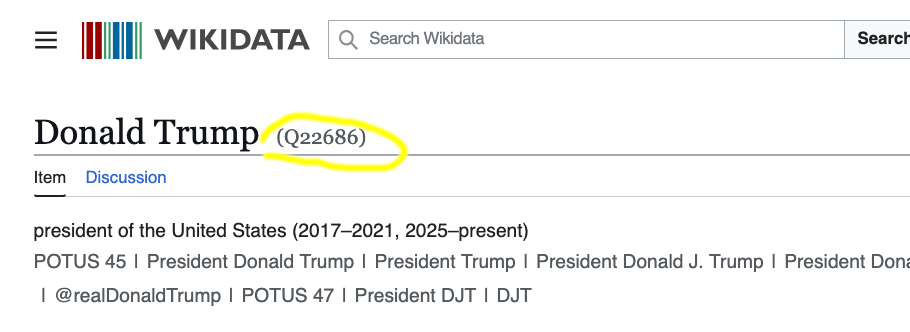
Otro detalle a tener en cuenta es que podemos incluir el Qname de Wikidata de cualquier persona en la URL, y tratar de rescatar sus relaciones familiares o genealogía:
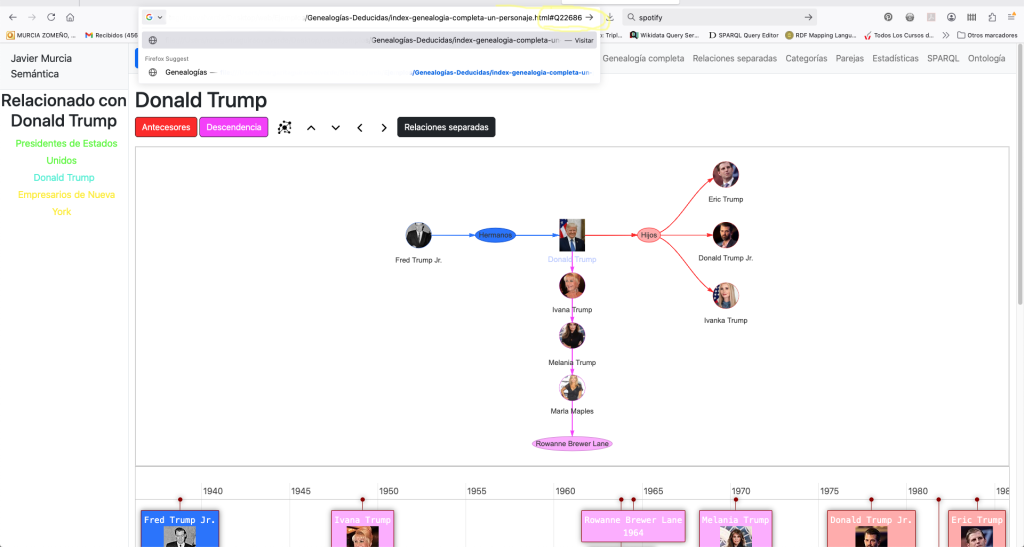
Análisis de Endogamia Histórica
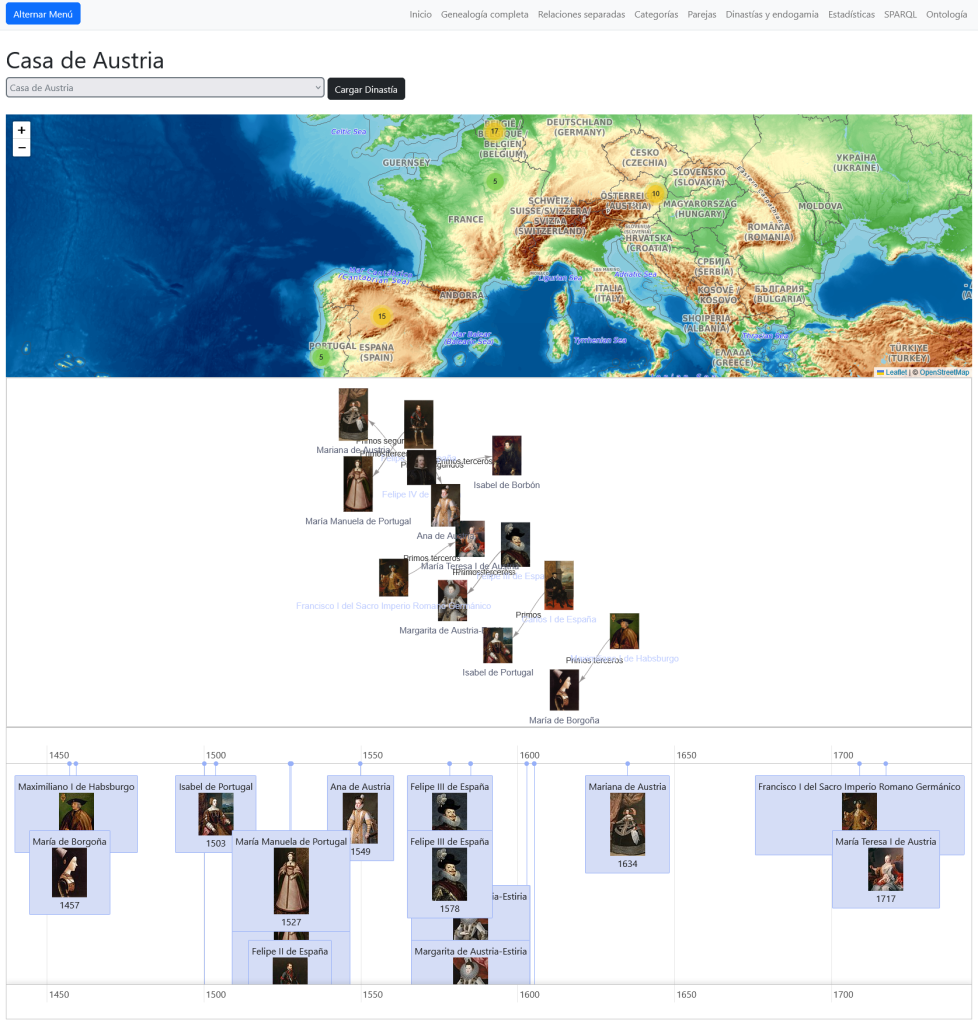
Como ejemplo de uso que puede ser ampliamente desarrollado he creado una sección donde visualizar personas que tuvieran parentesco y además fueran pareja: hermanos, primos, primos segundos…
En una sección especial, como caso de uso, analizamos los parentescos de diversas dinastías europeas para comprobar parentescos cercanos entre parejas.
Conclusión: Del Dato Genealógico a la Inteligencia de Redes
Este proyecto ilustra el potencial de la Web Semántica y los Grafos de Conocimiento para descubrir patrones ocultos en grandes volúmenes de datos (Big Data). Hemos pasado de un listado de nacimientos a una red compleja que permite analizar la dispersión geográfica de familias, detectar endogamia histórica y visualizar dinastías completas en tiempo real.
La capacidad para modelar ontologías, gestionar inferencias masivas y construir interfaces de descubrimiento es aplicable a múltiples sectores:
- Sector Legal y Administrativo: Gestión avanzada de registros civiles y sucesiones.
- Investigación Biomédica: Rastreo de antecedentes genéticos en grandes poblaciones.
- Humanidades Digitales: Análisis de redes de poder históricas.
- Estudios demográficos.
- Sistemas genealógicos profesionales.
- Bases de datos históricas.
Los grafos de conocimiento no solo almacenan información, sino que pueden razonar, expandirse y generar nuevo conocimiento estructurado.
Si deseas construir sistemas de inferencia semántica, expandir conocimiento a partir de reglas formales y la inteligencia Artificial Simbólica o transformar bases de datos relacionales en grafos de conocimiento vivos, puedo ayudarte a diseñar la ontología, el modelo de inferencia y la infraestructura técnica.
Estadísticas
| Triples totales | 40.593.509 |
| Afirmaciones de clase nuevas | 1.986.827 |
| Afirmaciones de propiedad nuevas | 14.647.450 |
| Personas | 944.334 |
Deja una respuesta