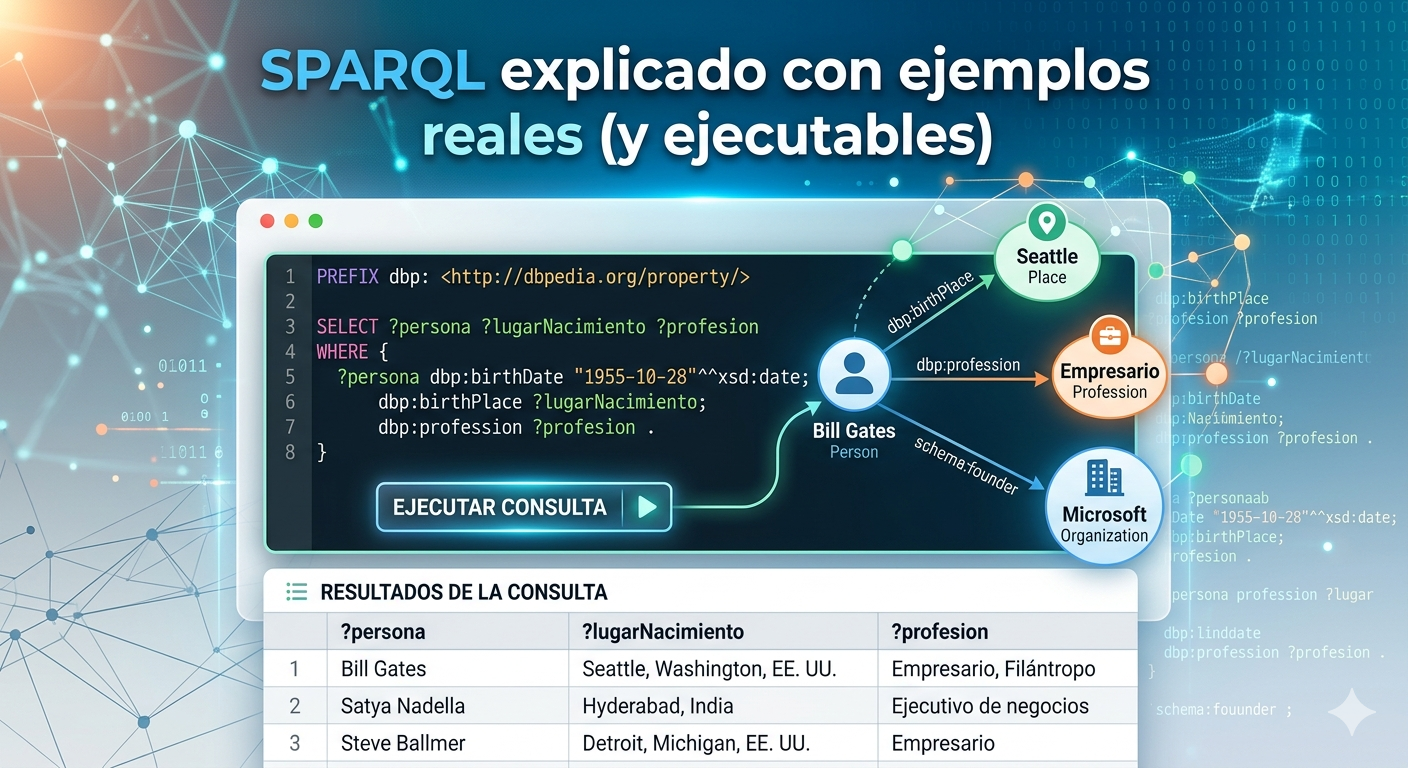
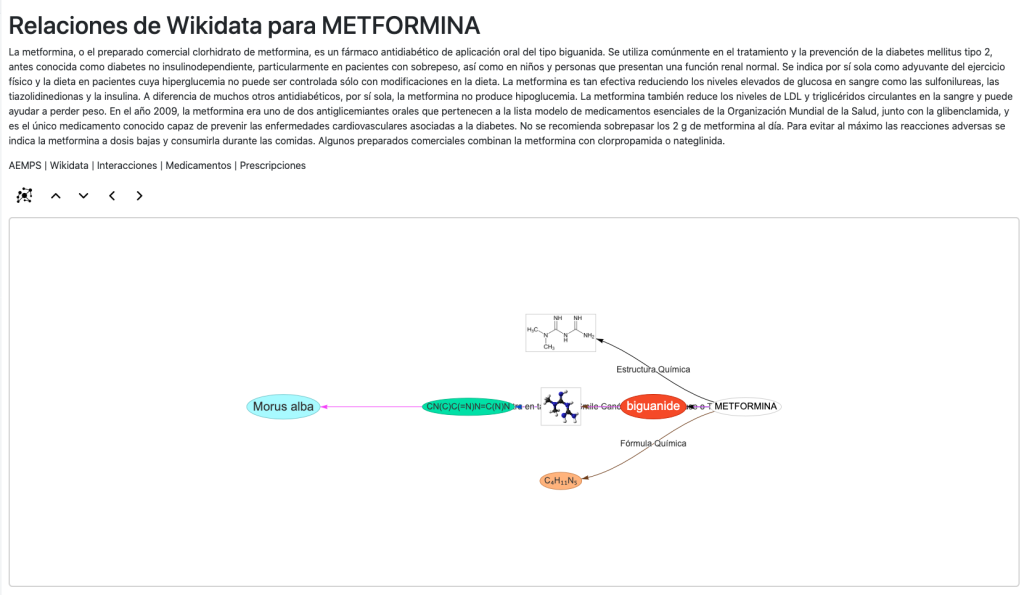
En la era de la Inteligencia Artificial y el Big Data, estructurar la información no es suficiente; necesitamos que las máquinas entiendan el significado de esa información. Aquí es donde entra en juego la creación de ontologías, la piedra angular de la Web Semántica y de los sistemas modernos de toma de decisiones.
Si alguna vez te has preguntado cómo dar el salto de una base de datos tradicional a un modelo de conocimiento capaz de razonar por sí mismo, estás en el lugar correcto. En esta guía práctica analizaremos qué es una ontología, cómo representarla utilizando el estándar OWL (Ontology Web Language) y cómo empezar a modelar hoy mismo utilizando Protégé, la herramienta líder del sector.
¿Qué es una Ontología en Informática?
En ciencias de la computación, una ontología es un modelo conceptual que define formalmente las relaciones entre los elementos de un dominio específico. A diferencia de un esquema de base de datos relacional (que solo define tablas y columnas), una ontología define:
Clases (Conceptos): Las categorías de objetos en tu dominio (ej. Persona, Organización, Medicamento).
Propiedades (Relaciones): Cómo se conectan estas clases entre sí (ej. esEmpleadoDe, recetaPara).
Individuos (Instancias): Los datos reales que pueblan el modelo (ej. Juan, Google, Aspirina).
Reglas y Axiomas: Las leyes lógicas que rigen el dominio (ej. «Toda persona tiene exactamente un padre biológico»).
La gran ventaja de las ontologías es que son autodescriptivas y extensibles. Permiten que diferentes sistemas compartan un vocabulario común sin perder el contexto semántico.
OWL (Ontology Web Language): El Estándar de la Web Semántica
Para que una ontología sea legible por cualquier máquina en el mundo, debe escribirse en un lenguaje estandarizado. El consorcio W3C definió para esto OWL (Ontology Web Language).
OWL se basa en la lógica de descripción y se apoya en tecnologías como RDF y XML. Una de sus mayores virtudes es que permite definir restricciones muy complejas sobre las propiedades, lo que habilita el razonamiento automático.
Características clave de las propiedades en OWL:
Propiedades Transitivas: está relacionado con a través de la propiedad , y está relacionado con a través de , entonces el sistema infiere automáticamente que está relacionado con a través de .
Propiedades Inversas: Si definimos que esHijoDe es la inversa de esPadreDe, al declarar que «Juan esHijoDe Pedro», el sistema deduce inmediatamente que «Pedro esPadreDe Juan».
Propiedades Simétricas: Si es cónyuge de , entonces es cónyuge de .
Aunque podrías escribir código OWL directamente a mano, el estándar es extremadamente denso. En el mundo profesional, la herramienta estándar de facto para diseñar ontologías de forma visual es Protégé, un software de código abierto desarrollado por la Universidad de Stanford.
Protégé proporciona una interfaz gráfica intuitiva para gestionar la jerarquía de clases, definir propiedades, aplicar restricciones lógicas y, lo más importante, ejecutar razonadores lógicos (como HermiT o Pellet) para comprobar que tu ontología no contiene contradicciones.
Guía Paso a Paso: Tu primera ontología en Protégé
Para ilustrar el proceso, modelaremos una versión simplificada de un sistema de relaciones familiares utilizando Protégé:
Paso 1: Definir las Clases (La taxonomía)
Al abrir Protégé, lo primero que haremos será definir nuestra jerarquía de clases en la pestaña Entities / Classes.
Creamos la clase raíz Persona.
Bajo Persona, creamos dos subclases disjuntas (que no pueden solaparse): Hombre y Mujer.
Paso 2: Crear las Propiedades (Object Properties)
Las propiedades de objeto definen relaciones entre instancias de clases. En la pestaña Object Properties:
Creamos la relación tienePadre.
Definimos su Domain (Dominio): Persona (quién puede tener padre).
Definimos su Range (Rango): Hombre (el padre debe ser un hombre).
Creamos la propiedad inversa esPadreDe y la vinculamos como Inverse Of de tienePadre.
Paso 3: Definir Características Avanzadas
Para dotar a nuestra ontología de capacidad de razonamiento:
Creamos la propiedad esHermanoDe. La marcamos como Symmetric (si Juan es hermano de Pedro, Pedro lo es de Juan).
Creamos la propiedad esAncestroDe y la marcamos como Transitive (si eres ancestro de tu hijo, y tu hijo de tu nieto, tú eres ancestro de tu nieto).
Paso 4: Ejecutar el Razonador (Reasoner)
Una de las herramientas más potentes de Protégé es el menú Reasoner. Al seleccionar un motor como HermiT e iniciarlo (Start Reasoner), el software analizará toda la lógica de nuestra ontología. Si hemos cometido un error de diseño (por ejemplo, decir que alguien es hombre y mujer a la vez, siendo clases disjuntas), el razonador marcará la inconsistencia en rojo para que podamos corregirla antes de llevar la ontología a producción.
Conclusión: El valor de un buen modelo semántico
La creación de ontologías con OWL y herramientas como Protégé es el primer paso crítico para cualquier proyecto de datos inteligente. Sin un modelo conceptual claro y robusto, es imposible entrenar algoritmos de IA simbólica o estructurar datos a gran escala de manera coherente.
¿Estás pensando en migrar tus datos a un grafo de conocimiento? Diseñar una ontología ineficiente puede ralentizar tus consultas o generar deducciones incorrectas. Si necesitas ayuda para modelar el dominio de tu negocio, optimizar ontologías en OWL o integrar motores de razonamiento lógico en tu infraestructura, puedes contactar conmigo para diseñar una solución semántica a tu medida.
Vivimos en la era del Big Data. Las empresas y organizaciones acumulan millones de registros diarios, pero tener datos guardados en una base de datos no es sinónimo de tener respuestas. Para dar el salto de la simple acumulación a la verdadera inteligencia, necesitamos aplicar el razonamiento sobre datos.
Pero, ¿qué significa exactamente este concepto y cómo puede revolucionar la forma en que extraemos valor de nuestra información?
¿Qué es el Razonamiento sobre Datos?
El razonamiento sobre datos (o inferencia semántica) es el proceso mediante el cual un sistema informático utiliza reglas lógicas y ontologías para descubrir nueva información que no estaba explícitamente guardada en la base de datos original.
En bases de datos relacionales tradicionales (SQL), si haces una consulta, solo obtienes lo que alguien escribió previamente. Con el razonamiento lógico sobre datos estructurados en grafos de conocimiento, el sistema es capaz de deducir nuevas verdades. Es decir, por cada dato que introduces, el motor de inferencia puede generar automáticamente decenas de datos implícitos.
Para entender el verdadero poder de esta tecnología, veamos un ejemplo a gran escala.
De la Teoría a la Práctica: Infiriendo 14 Millones de Relaciones
Para demostrar la capacidad del razonamiento lógico sobre datos, diseñé un proyecto de Ingeniería de Conocimiento a Gran Escala utilizando información de Wikidata.
El objetivo no era consultar un árbol genealógico existente, sino construir una genealogía ampliada partiendo de un conjunto mínimo de datos.
El Punto de Partida: Datos Explícitos
Tomé una muestra de casi un millón de personas en Wikidata. La única relación de parentesco directa que utilicé fue la propiedad básica: hijo/a de.
Un sistema tradicional se quedaría ahí. Sabría quién es el padre y quién es el hijo, pero no sabría responder a la pregunta: «¿Quiénes son primos terceros en esta base de datos?».
La Inferencia Semántica en Acción
Diseñé una ontología ligera y un motor de inferencia basado en cláusulas lógicas. A través de operaciones de materialización de conocimiento (usando inserciones SPARQL en cascada), enseñé al sistema a razonar.
La lógica subyacente es sencilla para un humano, pero procesarla a esta escala requiere una arquitectura robusta:
Si A es mujer, y A es hermana de B, y B es madre de C; entonces el sistema deduce automáticamente que A es tía de C.
Los Resultados del Razonamiento
Gestionando la explosión combinatoria para no saturar la memoria del servidor, el motor procesó ese millón de entidades iniciales. ¿El resultado?
14.647.450 de nuevas relaciones semánticas generadas.
Por cada dato explícito original, el sistema infirió 14 datos implícitos.
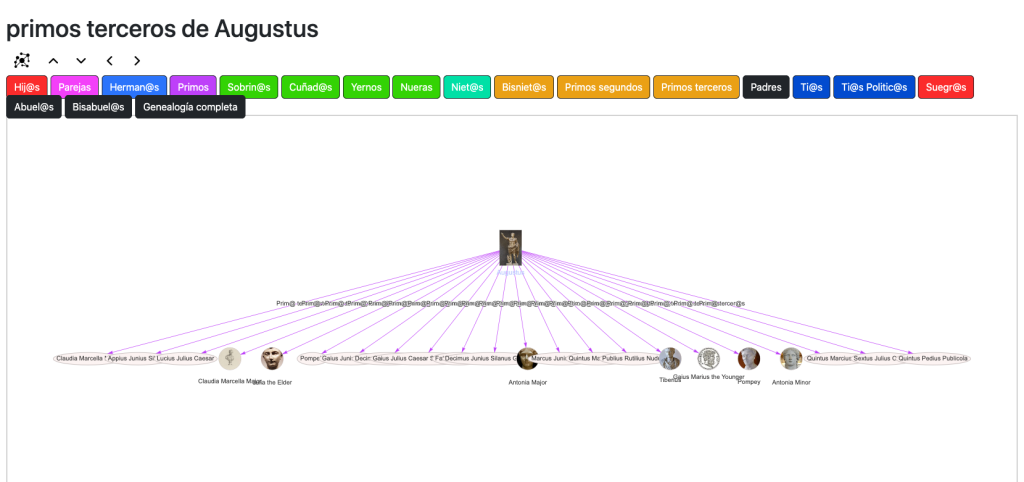
Logramos deducir relaciones lejanas de hasta tercer grado de consanguinidad (más de 1.3 millones de relaciones de «primos terceros»).
Tipo de Dato
Cantidad Original
Conocimiento Inferido
Nodos (Personas)
~ 1.000.000
–
Relaciones Explícitas
3.275.201
–
Nuevas Relaciones Deducidas
–
14.647.450
Total de Triples en el Grafo
–
> 40.500.000
Pasamos de un listado plano de nacimientos a una red semántica viva y explorable.
¿Por qué importa el Razonamiento sobre Datos en el mundo empresarial?
La capacidad de modelar ontologías y aplicar deducción lógica no es un mero ejercicio académico. Es una ventaja competitiva crítica para múltiples sectores:
Sector Legal y Financiero: Detección de conflictos de intereses corporativos, rastreo de beneficiarios reales y prevención de fraude conectando puntos que aparentemente no estaban relacionados.
Investigación Biomédica: Descubrimiento de relaciones ocultas entre genes, proteínas y enfermedades a partir de literatura médica dispersa.
Gestión de Recursos Humanos y Redes: Análisis de influencia y liderazgo dentro de grandes organizaciones corporativas.
Los grafos de conocimiento equipados con motores de razonamiento no solo almacenan información; la entienden, la expanden y generan inteligencia estructurada.
Lleva tus datos al siguiente nivel
Si tu organización maneja grandes volúmenes de información fragmentada y necesitas transformar tus bases de datos estáticas en grafos de conocimiento vivos, puedo ayudarte.
Diseño ontologías a medida, implemento modelos de inferencia escalables y desarrollo infraestructuras técnicas basadas en Inteligencia Artificial Simbólica para que tus datos empiecen a trabajar para ti.
La Inteligencia Artificial Generativa ha prometido revolucionar la forma en que las empresas interactúan con su información. Sin embargo, cuando las organizaciones conectan modelos como ChatGPT o Gemini a sus documentos corporativos, tropiezan con un muro peligroso: las alucinaciones.
Si le pides a una IA estándar que cruce la normativa legal de tu empresa con el historial de un cliente, es muy probable que invente datos, mezcle conceptos o dé respuestas plausibles pero falsas. En sectores como el legal, el farmacéutico o la administración pública, un error del 5% no es un margen de mejora; es un riesgo inasumible.
La solución a este problema no es entrenar modelos más grandes, sino cambiar la arquitectura de datos subyacente. La respuesta se llama RAG Semántico impulsado por Grafos de Conocimiento.
¿Qué es RAG y por qué el enfoque tradicional se queda corto?
RAG (Retrieval-Augmented Generation o Generación Aumentada por Recuperación) es una técnica que permite a una IA buscar información en tus bases de datos privadas antes de responder.
En el RAG tradicional, los documentos se cortan en pedazos y se guardan como «vectores» (números). Cuando el usuario hace una pregunta, el sistema busca los fragmentos de texto que más se parecen estadísticamente a la pregunta y se los da a la IA para que redacte la respuesta.
¿El problema? La similitud estadística no es comprensión lógica. Si le preguntas a un RAG tradicional: «¿Qué medicamentos de nuestro catálogo interactúan negativamente con el ibuprofeno?», el sistema buscará textos donde las palabras «ibuprofeno» e «interacción» estén cerca. Si el catálogo es complejo, omitirá relaciones indirectas o inventará conexiones, porque no entiende qué es un medicamento ni cómo funciona la química.
La solución: RAG Semántico y la IA Neuro-Simbólica
Para que una IA deje de adivinar, necesitamos darle un «cerebro lógico». Aquí es donde entran los Grafos de Conocimiento y la Web Semántica.
En un RAG Semántico (a menudo llamado GraphRAG), no cortamos los textos a ciegas. Primero, estructuramos la información de la empresa en una ontología. Modelamos las entidades (Pacientes, Contratos, Fármacos) y sus relaciones lógicas exactas.
De este modo, creamos un sistema de IA Neuro-Simbólica:
La parte Simbólica (El Grafo): Aporta lógica estricta, determinismo y hechos comprobables mediante consultas precisas (SPARQL).
La parte Neuronal (El LLM): Aporta la comprensión del lenguaje natural para interactuar con el usuario de forma fluida.
Cuando el usuario hace la misma pregunta sobre el ibuprofeno, el LLM no busca similitudes de texto; traduce la pregunta a una consulta lógica al grafo. El grafo devuelve hechos y relaciones exactas, y el LLM simplemente los traduce de vuelta a lenguaje humano. Cero alucinaciones. Trazabilidad absoluta.
Caso de Uso Práctico: Datos Farmacéuticos (HealthKG)
Un ejemplo claro de la necesidad de esta precisión es mi proyecto HealthKG, un grafo del ecosistema farmacéutico español.
En este sector, cruzar datos de la Agencia Española de Medicamentos (AEMPS) con bases de datos globales (Wikidata, DBpedia) y ontologías médicas (como ATC o DOID) es un desafío monumental si se usan bases de datos relacionales.
Al modelar este ecosistema como un Grafo de Conocimiento, un sistema RAG semántico puede navegar por las relaciones estructuradas para inferir de forma 100% precisa interacciones, duplicidades terapéuticas y vincular fármacos con biomarcadores, respondiendo a preguntas complejas con referencias exactas a las normativas vigentes. («Puedes explorar la visualización y el modelado de este ecosistema en el caso de estudio de HealthKG«).
Beneficios del RAG Semántico para tu organización
Implementar esta arquitectura supone un salto cualitativo enorme:
Trazabilidad total (Explicabilidad): Cada afirmación de la IA está vinculada a un nodo específico de tu base de datos. Si la IA afirma algo, puedes ver exactamente de qué documento y relación lógica partió.
Inferencia de nuevo conocimiento: El grafo puede deducir relaciones implícitas gracias a la lógica de su ontología (algo que los vectores simples no pueden hacer).
Actualización en tiempo real: Si cambias un dato en el grafo (ej. una ley o el precio de un producto), la IA lo asimila instantáneamente, sin necesidad de ser re-entrenada.
Conclusión
El futuro de la IA empresarial no pasa por modelos de lenguaje que actúen como enciclopedias que memorizan textos, sino como interfaces inteligentes que consultan Grafos de Conocimiento rigurosos. Modelar la realidad de tu empresa de forma lógica es el único camino hacia una automatización segura y fiable.
¿Quieres implementar un sistema de IA que entienda tus datos sin inventar respuestas? Hablemos de la arquitectura semántica de tu proyecto.
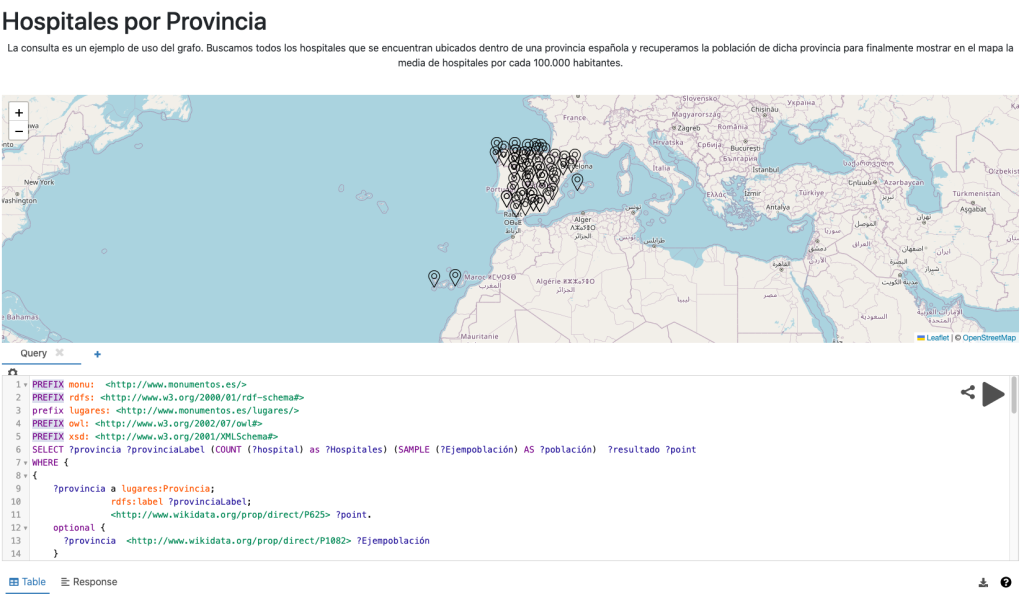
Estás consultando varios grafos a la vez y unificando resultados en una sola query. La consulta va saltando por varios grafos hasta unificar lugares, monumentos y toponimia histórica
Vivimos en una era en la que las organizaciones acumulan enormes cantidades de datos, pero tener datos no es lo mismo que tener conocimiento.
Aquí es donde entran los grafos de conocimiento: una tecnología capaz de conectar información, revelar relaciones ocultas y permitir nuevas formas de análisis.
En este artículo explico qué son, cómo funcionan y por qué se están convirtiendo en una pieza clave en inteligencia artificial, análisis de datos y sistemas empresariales. Además, mostraré un ejemplo real basado en un grafo de medicamentos desarrollado a partir de datos públicos.
¿Qué es un grafo de conocimiento?
Un grafo de conocimiento es una estructura que representa información mediante:
A diferencia de una base de datos tradicional, donde los datos se organizan en tablas, un grafo permite modelar directamente las relaciones, que es donde reside gran parte del valor.
¿En qué se diferencia de una base de datos tradicional?
Las bases de datos relacionales funcionan bien cuando:
Los datos están claramente estructurados.
Las consultas son previsibles.
Pero presentan limitaciones cuando:
Las relaciones son complejas.
Los datos provienen de múltiples fuentes.
Se necesita flexibilidad.
Los grafos de conocimiento permiten:
Integrar datos heterogéneos.
Adaptarse a nuevos requisitos.
Realizar consultas más cercanas a cómo pensamos.
¿Cómo funcionan?
Los grafos de conocimiento suelen basarse en estándares como:
RDF (Resource Description Framework)
SPARQL (lenguaje de consulta)
OWL (ontologías)
Estos estándares permiten:
Definir entidades de forma unívoca.
Establecer relaciones explícitas.
Realizar consultas complejas e inferencias.
Ejemplo real: un grafo de medicamentos
Para ilustrar estas ideas, he desarrollado un grafo de conocimiento en el ámbito sanitario a partir de datos públicos de la AEMPS.
🔧 Construcción del grafo
El proceso incluyó:
Transformación de archivos XML y CSV a RDF.
Diseño de una ontología específica del dominio.
Creación de entidades como:
medicamentos
principios activos
enfermedades
interacciones
biomarcadores
Además, se añadieron relaciones que no existían explícitamente en los datos originales, mediante consultas SPARQL e inferencias.
🔗 Enriquecimiento con datos externos
Para aumentar el valor del grafo, se realizó una vinculación con fuentes externas:
Wikidata (información biológica y médica)
DBpedia (contexto adicional)
Ontologías biomédicas como ATC o Disease Ontology.
Esto permitió conectar, por ejemplo:
un medicamento → su principio activo
el principio activo → enfermedades tratadas
las enfermedades → procesos biológicos o genes
🧠 Descubrimiento de relaciones
Uno de los puntos clave fue que muchas relaciones no estaban explícitas en los datos originales.
Mediante consultas e inferencias se pudieron construir:
Relaciones entre enfermedades y tratamientos.
Interacciones entre principios activos.
Conexiones con biomarcadores y genes.
Esto transforma un conjunto de datos estático en un sistema capaz de generar conocimiento nuevo.
📊 Resultados
El grafo resultante incluye:
Más de 25.000 medicamentos.
Más de 3.000 principios activos.
Más de 20.000 enfermedades.
Millones de triples RDF.
Y lo más importante:
Permite navegar y descubrir relaciones complejas entre todos estos elementos.
🔍 ¿Qué permite hacer este grafo?
Por ejemplo:
Identificar tratamientos relacionados con una enfermedad.
Analizar interacciones entre medicamentos.
Explorar conexiones entre fármacos y procesos biológicos.
Navegar desde un medicamento hasta genes asociados.
Este tipo de exploración sería extremadamente compleja con modelos tradicionales.
¿Por qué son importantes hoy?
1. Integración de datos
Permiten unificar múltiples fuentes en un solo modelo coherente.
2. Inteligencia Artificial y RAG
Los grafos de conocimiento son fundamentales para mejorar sistemas de IA:
Aportan contexto estructurado.
Reducen ambigüedad.
Mejoran la calidad de las respuestas.
3. Descubrimiento de conocimiento
Permiten identificar relaciones que no eran evidentes:
Patrones ocultos.
Conexiones indirectas.
Inferencias automáticas.
4. Toma de decisiones
Transforman datos en conocimiento útil para:
Análisis.
Planificación.
Estrategia.
Casos de uso
Sanidad (medicamentos, enfermedades, genética)
Cultura e historia.
Sistemas legales.
Integración de datos empresariales.
Conclusión
Los grafos de conocimiento permiten pasar de:
👉 datos aislados a 👉 conocimiento conectado
Y eso cambia completamente cómo entendemos y utilizamos la información.
Si estás explorando cómo aplicar grafos de conocimiento en tu organización —ya sea para integrar datos, mejorar sistemas de IA o descubrir nuevas relaciones— puedo ayudarte a diseñar la arquitectura, ontologías y procesos necesarios.
John Wilkins (14 de febrero de 1614-19 de noviembre de 1672) fue un religioso y naturalista inglés, además del primer secretario de la Royal Society y versátil ensayista.
Tuvo muy en mente la creación de una lengua franca. Un problema típico de la “República de las letras” donde se alternaba el uso de Latín como lengua de intercambio intelectual y las lenguas vernáculas de cada erudito.
Desarrolló así la posibilidad de construir un lenguaje mundial artificial, una lengua filosófica, aspecto en el que se insistiría hasta finales del siglo de las Luces. Como desarrollo de esta idea fue autor de la primera lengua sintética («lengua artificial filosófica de uso universal») que dio a conocer en varios de sus libros.
Y aunque su nombre no ha pasado a los primeros puestos de la historia del pensamiento si que llamó la atención de otro autor muy interesado en el lenguaje, sus juegos y sus límites: el escritor argentino Jorge Luis Borges, que dedicó un ensayo a una de sus obras.
El Emporio celestial de conocimientos benévolos
Wilkins proponía un sistema en apariencia muy simple donde dividía el universo en cuarenta categorías divisibles a su vez en especies, asignando a cada género un monosílabo de dos letras; a cada diferencia, una consonante y a cada especie, una vocal.
Y es en este contexto donde Borges ficciona su celebérrimo “El Emporio celestial de conocimientos benévolos” una cierta enciclopediachina donde los animales se clasificarían en:
(a) pertenecientes al Emperador,
(b) embalsamados,
(c) amaestrados,
(d) lechones,
(e) sirenas,
(f) fabulosos,
(g) perros sueltos,
(h) incluidos en esta clasificación,
(i) que se agitan como locos,
(j) innumerables
(k) dibujados con un pincel finísimo de pelo de camello,
(l) etcétera,
(m) que acaban de romper el jarrón,
(n) que de lejos parecen moscas.
A Borges le debió parecer que las las taxonomías poseían una naturaleza arbitraria, ya sea que formen un lenguaje o simplemente compongan una forma de entender y ordenar el mundo. Concluyendo que a su entender no podría haber una clasificación del universo que no fuese arbitraria y llena de conjeturas.
Dice Borges en dicho relato: «(…) notoriamente no hay clasificación del universo que no sea arbitraria y conjetural. La razón es muy simple: no sabemos qué cosa es el universo».
Foucault y los límites de nuestro pensamiento
No mucho tiempo después el filósofo francés Michael Foucault le dedicaría una reflexión en el prefacio de “Las palabras y las cosas”, confesando que leer ese texto de Borges le hizo reír, pero también rompió todas las familiaridades de su pensamiento.
En efecto esta lista nos hace sonreír por su aparente absurdo e incoherencia lógica desde nuestra perspectiva occidental moderna.
Pero lo que Foucault nos enseña es que toda clasificación es hija de su tiempo, su cultura y su propósito. Y no existe una forma «natural» u «objetiva» de dividir el mundo en categorías. Lo que a nosotros nos parece lógico (clasificar animales por vertebrados/invertebrados), a otra cultura (o a un sistema con otro propósito) le resultaría inútil.
El Síndrome de la «Ontología Universal»
Cuando una empresa u organización decide montar un Grafo de Conocimiento o un sistema RAG para su IA, el primer instinto del equipo técnico es intentar modelar «toda la realidad» de la empresa de forma exhaustiva y perfecta.
Las posibilidades epistemológicas y de representación que nos ofrecen nuestros datos y el mundo en su conjunto son inagotables, los equipos pueden perder meses discutiendo filosóficamente: «¿Un paciente es una ‘persona’, o es un ‘rol temporal’?», «¿Un contrato es un ‘documento’ o un ‘evento legal’?». Podemos intentar crear una taxonomía universal y acabar con un modelo inmanejable, costoso y que no resuelve nada.
Ontologías orientadas a propósito
En Ingeniería Ontológica, cuando diseño, no busco la «Verdad absoluta», sino la «Utilidad operativa». Una ontología solo debe contener los conceptos y relaciones estrictamente necesarios para responder a las preguntas de negocio que la organización necesita resolver.
Una ontología debe diseñarse teniendo en cuenta:
Los objetivos del sistema.
Los tipos de consultas que se quieren realizar.
Los procesos que debe soportar.
Las relaciones que se quieren descubrir.
Las inferencias que se esperan conseguir.
Por ejemplo, un sistema sanitario puede organizar medicamentos según:
Principios activos.
Indicaciones terapéuticas.
Regulación.
Interacciones.
Cada enfoque produce un modelo diferente.
Los grafos permiten:
Múltiples relaciones simultáneas.
Diferentes perspectivas sobre las mismas entidades
Extender el modelo sin romper la estructura.
Conclusiones
La clasificación de Borges parece absurda porque no compartimos su sistema de referencia.
Pero nos recuerda algo importante:
Toda taxonomía es una forma de ordenar el mundo según ciertos criterios.
Cuando una organización diseña una ontología o un grafo de conocimiento debería preguntarse:
Qué preguntas quiere poder responder
Qué relaciones son relevantes.
Qué decisiones necesita apoyar.
Solo entonces la clasificación deja de ser arbitraria y se convierte en una herramienta para generar conocimiento.
Y en ingeniería del conocimiento esos criterios deben ser explícitos y conscientes.
La belleza y potencia de la Web Semántica (RDF/OWL) es su flexibilidad. Permite que diferentes departamentos tengan «vistas» distintas del mismo mundo, integradas en un solo grafo.
Diseñar la arquitectura de datos de una organización requiere tanto de rigor técnico como de visión filosófica para entender el negocio. Si tu empresa está luchando por conectar sus silos de información sin perderse en el intento de cartografiar el universo entero, hablemos.
De archivos XML aislados a un ecosistema de datos sanitarios interoperables con RAG y Análisis Predictivo
Los datos de medicamentos existen, son públicos y están bien documentados… pero están fragmentados, no están enlazados y no permiten razonamiento ni exploración semántica real. Este proyecto aborda ese problema transformando el Nomenclátor oficial de la AEMPS en un grafo de conocimiento sanitario interconectado con ontologías biomédicas internacionales.
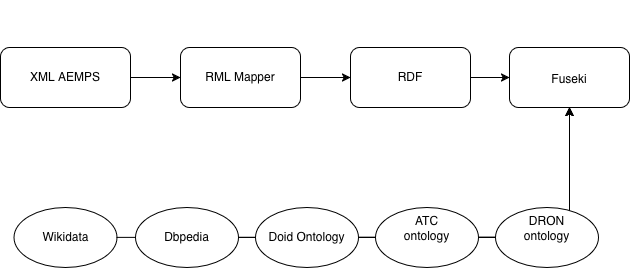
La información sanitaria pública es vasta pero fragmentada. La Agencia Española de Medicamentos (AEMPS) ofrece datos cruciales en XML y Excel; Wikidata y DBpedia poseen el contexto biológico; y las ontologías como ATC o DOID (Human Disease Ontology) estructuran el conocimiento médico. El problema es que estos mundos no se hablan entre sí.
HealthKG nace con un objetivo: romper estos silos. Es una arquitectura de conocimiento que ingesta, normaliza y vincula estas fuentes para permitir preguntas complejas como: «¿Qué principios activos aprobados en España interactúan con este gen y qué enfermedades tratan según la literatura internacional?»
Transformación de datos institucionales a Knowledge Graph
El primer desafío fue transformar los diccionarios XML de la AEMPS (Nomenclátor) y varios archivos en .xls de facturación y medicamentos en tripletas RDF estandarizadas.
Según define la propia AEMPS:
«El Nomenclátor de prescripción es una base de datos de medicamentos diseñada para proporcionar información básica de prescripción a los sistemas de información asistenciales.»
y
«El Nomenclátor de prescripción incluye para todos los medicamentos autorizados y comercializados, financiados y no financiados, los datos relativos a su identificación e información técnica (a título informativo contiene también información de medicamentos suspendidos, revocados o que han dejado de estar comercializados desde mayo de 2013).»
El Nomenclátor no modela explícitamente relaciones semánticas entre medicamentos, principios activos y efectos. Este proyecto convierte relaciones implícitas en entidades y propiedades explícitas, habilitando razonamiento y navegación.
Stack Tecnológico:
RML (RDF Mapping Language): Para mapear estructuras XML complejas (prescripciones) a nuestra ontología.
Tarql: Para la conversión ágil de archivos Excel/CSV.
Apache Jena Fuseki: Como Triple Store para orquestar el grafo.
Diseño Ontológico y Modelado
Partiendo de los diccionarios ya creados por el Ministerio y de las propias necesidades del futuro grafo creo las clases y propiedades en Protégé:
Diseño una ontología central (med:) capaz de actuar como «pegamento» entre las distintas fuentes. Creamos clases que no existían explícitamente en los datos originales, como med:Interacción o med:Biomarcador, transformando simples notas de texto en entidades conectadas.
Se añaden varias clases no existentes en los diccionarios:
med:Medicamento vinculada con prescripciones, principios activos y laboratorios.
med:Enfermedad vinculada con principios activos.
med:Interacción vincula pares de códigos ATC, y principios activos.
med:Duplicidad vincula pares de códigos ATC, y principios activos.
med:Biomarcador vincula principios activos y genes.
Un grafo de contexto de 169M de triples
Con el objetivo de poseer un grafo de «contexto» para los medicamentos realizo una extracción controlada de Wikidata. El punto de unión básico proyectado van a ser los principios activos. Sustancias químicas, naturales o artificiales utilizadas para la fabricación de medicamentos y que producen un efecto terapéutico. El grafo de «contexto» extraído posee tipos de entidades como: Entidad química, molecular function, biological process, class of disease, gene, taxon, chromosome, y un largo etcétera.
En sí mismo compone un grafo biológico muy completo. Conteniendo 169.374.083 millones de triples. De esta manera conseguimos un subgrafo temático que utilizo como contexto semántico local y que permite razonamiento cruzado.
Entity linking multi-grafo
Un grafo aislado no aporta valor. La potencia de HealthKG reside en su conectividad con la nube de datos abiertos enlazados (LOD):
Reconciliación Química: Vinculamos más de 2.200 principios activos de la AEMPS con Wikidata y DBpedia. Esto nos permitió importar propiedades moleculares y genéticas que la AEMPS no posee.
Jerarquización ATC: Los códigos ATC planos se vincularon a la ATC Ontology, permitiendo consultas jerárquicas (ej: «Dame todos los antiinflamatorios», no solo el Ibuprofeno).
Enfermedades y Tratamientos: Mediante técnicas de procesamiento de texto y coincidencia de etiquetas, inferimos la relación enfermedadTieneTratamiento cruzando datos de Dbpedia y Wikidata con nuestros principios activos.
Vinculamos datos de:
Wikidata
Dbpedia (es)
ATC ontology
DOID
DRON
Estrategias de emparejamiento de entidades en grafos heterogéneos
Principios activos
El primer emparejamiento de entidades que realizamos es entre los principios activos de nuestro grafo de medicamentos y las sustancias químicas presentes en el grafo de contexto y en Dbpedia en español para aumentar la conectividad y el acceso a información.
Este será el puente principal por el que unificar las distintas fuentes que tenemos entre manos y comenzar a lograr que los datos AEMPS dejen de estar aislados. De este modo podremos saltar desde un medicamento a su principio activo y de este a la enfermedad que trata, función que regula, gen, etc o seguir otros caminos en estas relaciones…
med:PrincipioActivo
3.167
Dbpedia (emparejados)
1.153
Wikidata (emparejados)
1.184
med:esVariacionDePrincipioActivo
1.115
Teniendo en cuenta que 1.115 principios activos son variaciones de otros ya emparejados hemos conseguido emparejar unos 2.200 principios activos, mas de dos tercios del total.
Consulta para construir los principios que son med:esVariacionDePrincipioActivo:
PREFIX rdfs: <http://www.w3.org/2000/01/rdf-schema#>
PREFIX rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#>
PREFIX med: <http://www.medicamentos.es/>
construct {
?principioactivo2 med:esVariacionDePrincipioActivo ?principioactivo1; #El principio activo 2 será una variación del 1
}
WHERE {
?principioactivo1 a med:PrincipioActivo;
rdfs:label ?principioactivo1label .
?principioactivo2 a med:PrincipioActivo;
rdfs:label ?principioactivo2label ;
# El nombre del principio 2 comienza igual que el nombre del prinicipo 1
FILTER (strStarts(?principioactivo2label, ?principioactivo1label)).
filter (?principioactivo2 != ?principioactivo1 )
}Lenguaje del código:PHP(php)
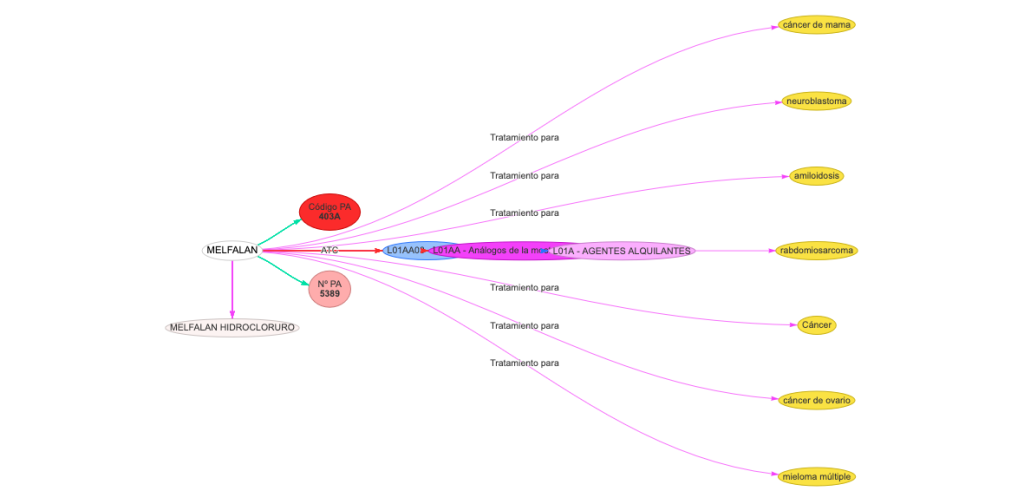
Los principios activos son un paso necesario para vincular enfermedades tratadas por los medicamentos. Para generar y vincular enfermedades utilizaremos nuestra clase med:Enfermedad. En nuestro grafo de contexto extraído de Wikidata tenemos un tipo enfermedad (Q112193867) y una propiedad (P2176)que la vincula al principio activo como tratamiento.
Primero construimos nuestras entidades med:Enfermedad a partir del tipo Q112193867.
Luego generamos la propiedad med:enfermedadTieneTratamiento.
También quería extraer y vincular enfermedades de Dbpedia. Esta posee la clase Disease, con la que construir la nuestra. Sin embargo, Dbpedia no posee una propiedad que vincule un enfermedad y un tratamiento, para ello desarrollo un método plausible que nos permite crear dicha propiedad.
Rescatamos los Wikilinks (enlaces dentro de los artículos de Wikipedia) de cada entidad de tipo med:Enfermedad y los comparamos con nuestros principios activos, previamente vinculados con owl:sameAs. Es altamente probable que los artículos sobre una enfermedad contengan referencias a las sustancias que se usan en su tratamiento.
Construir la relación enfermedad tiene tratamiento Dbpedia:
PREFIX med: <http://www.medicamentos.es/>
PREFIX owl: <http://www.w3.org/2002/07/owl#>
PREFIX rdfs: <http://www.w3.org/2000/01/rdf-schema#>
prefix prinactiv: <http://www.medicamentos.es/PrincipioActivo/>
construct {
?enfermedad med:enfermedadTieneTratamiento ?principioActivo.
}
WHERE {
?enfermedad a <http://dbpedia.org/ontology/Disease>.
?enfermedad <http://dbpedia.org/ontology/wikiPageWikiLink> ?WikiLink.
service <https://javiermurcia.tech/lab/Medicamentos> {
?principioActivo a med:PrincipioActivo;
owl:sameAs ?WikiLink.
}
}Lenguaje del código:HTML, XML(xml)
Esta consulta construye relaciones tratamiento–enfermedad en Dbpedia, donde dicha propiedad no existe explícitamente, usando enlaces internos de Wikipedia como señal semántica.
Como vemos en la imagen para la enfermedad «Reflujo gastroesofágico» la coincidencia entre tratamientos de la parte superior Dbpedia y la parte inferior grafo de contexto extraído de Wikidata, es altamente significativa.
Aprovechando que Dbpedia posee categorías construyo una taxonomía de las enfermedades con tratamientos farmacológicos. Lo que resultará muy útil para la navegación posterior. Partiendo de Categoría:Enfermedades_por_especialidad_médica, construimos las demás.
Códigos ATC
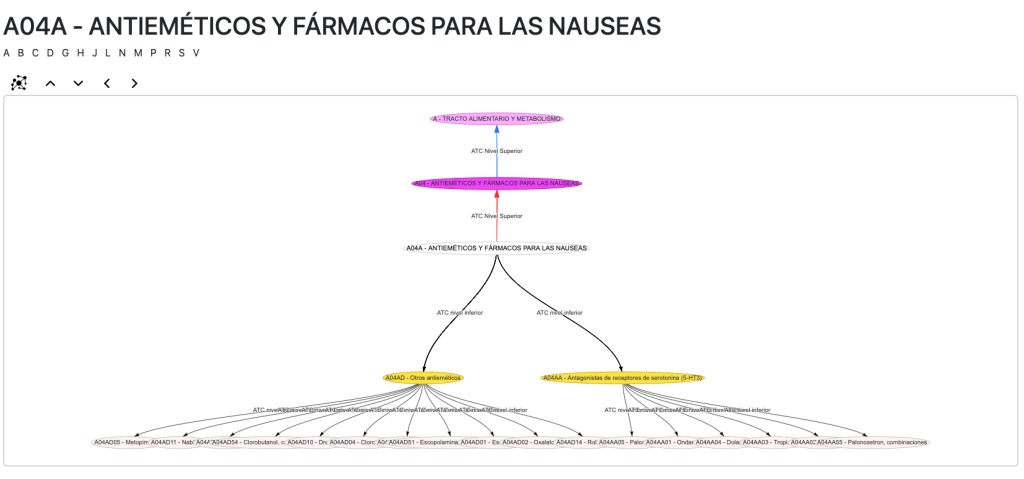
La AEMPS incluye un diccionario de códigos ATC. El código ATC o Sistema de Clasificación Anatómica, Terapéutica y Química, es un índice de sustancias farmacológicas y medicamentos, organizados según grupos terapéuticos.
Sin embargo, tal cual se encuentra no compone ni siquiera un árbol jerárquico por el que poder navegar. La solución: vincular mis entidades a la ATC ontology, que posee una organización en subclases que mejorará nuestras consultas, razonamientos y navegación.
Creando los Biomarcadores como clase e entidades
La base datos de Prescripciones incluye biomarcadores farmacogenómicos con aquellos principios activos con los que se ha establecido una conexión. Pero estos, no existen como entidades independientes, primero construyo a partir de las prescripciones en las que aparecen, junto a sus principios activos y los vinculo a los genes a los que hacen referencia en el grafo de contexto biológico.
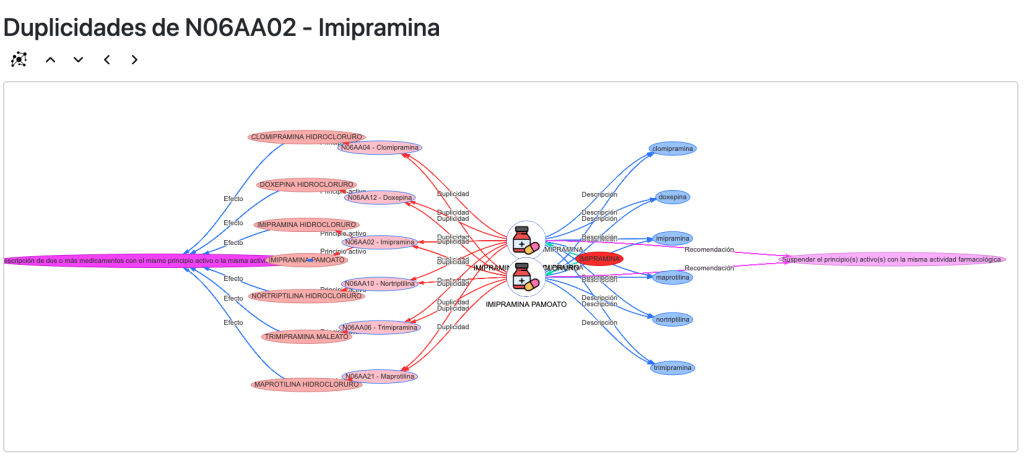
Interacciones y Duplicidades
De igual modo ocurre con las interacciones y las duplicidades que no existen como entidades sino solamente como relaciones. Lo que hago es relacionar los códigos ATC que interaccionan. Las prescripciones simplemente apuntan a un código ATC con el que interacciona, yo relaciono los códigos ATC y los principios activos:
Construyendo las interacciones:
PREFIX med: <http://www.medicamentos.es/>
PREFIX rdfs: <http://www.w3.org/2000/01/rdf-schema#>
construct {
?interaccion a med:Interacción;
med:interaccionaCon ?ATCinteraccion;
rdfs:label ?rdfslabel2;
med:seRefiereATC ?ATC;
med:efectoInteraccion ?efectoInteraccion;
med:recomendacionInteraccion ?recomendacionInteraccion;
med:tienePrincipioActivo ?PrincipioActivo;
med:principioActivoInteraccion ?PrincipioActivo2;
}
WHERE {
?a a med:Prescripción.
?a med:codigoATC ?codigoATC.
BIND(URI(CONCAT( "http://www.medicamentos.es/Interacción/" ,?codigoATC) ) AS ?label ) .
?a med:tieneComposicionPa ?tieneComposicionPa.
?a med:atcInteraccion ?atcInteraccion.
?a med:efectoInteraccion ?efectoInteraccion;
med:recomendacionInteraccion ?recomendacionInteraccion.
?b a med:Prescripción;
med:codigoATC ?atcInteraccion;
med:tieneComposicionPa ?tieneComposicionPa2;
med:atcInteraccion ?codigoATC;
med:efectoInteraccion ?efectoInteraccion;
med:recomendacionInteraccion ?recomendacionInteraccion.
?ATC a med:ATC;
med:codigoATC ?codigoATC.
?ATCinteraccion a med:ATC;
med:codigoATC ?atcInteraccion;
BIND(URI(CONCAT( STR(?label) ,"+") ) AS ?label2 ) .
BIND(URI(CONCAT( STR(?label2) , ?atcInteraccion) ) AS ?interaccion) .
BIND(CONCAT( STR(?codigoATC) , "+") AS ?rdfslabel) .
BIND(CONCAT( STR( ?rdfslabel) , ?atcInteraccion) AS ?rdfslabel2) .
?PrincipioActivo a med:PrincipioActivo;
med:nroPrincipioActivo ?tieneComposicionPa.
?PrincipioActivo2 a med:PrincipioActivo;
med:nroPrincipioActivo ?tieneComposicionPa2;
}Lenguaje del código:PHP(php)
Doid.owl y The Drug Ontology
Vinculamos con la ontología doid.owl. La Human Disease Ontology, compone una clasificación integral de enfermedades humanas organizadas por etiología. Lo que hago es emparejar las enfermedades que ya poseo con una ontología profesional para aumentar la conectividad y la base de verificabilidad del grafo.
Finalmente vinculo también nuestros principios activos con la ontología dron (The Drug Ontology). Yendo de nuestros principios a los extraídos de Wikidata, usamos sus labels en inglés y de ellos hacia la dron.
Navegación por descubrimiento semántico
Para hacer el grafo accesible, desarrollé una interfaz de Navegación por Descubrimiento. A diferencia de un buscador tradicional, aquí el usuario «surfea» las relaciones:
De un Laboratorio en el mapa -> a sus Medicamentos en una línea de tiempo.
De un Medicamento -> a su Principio Activo -> a las Enfermedades que trata.
Visualización de Interacciones y Duplicidades no como listas de alerta, sino como grafos de red.
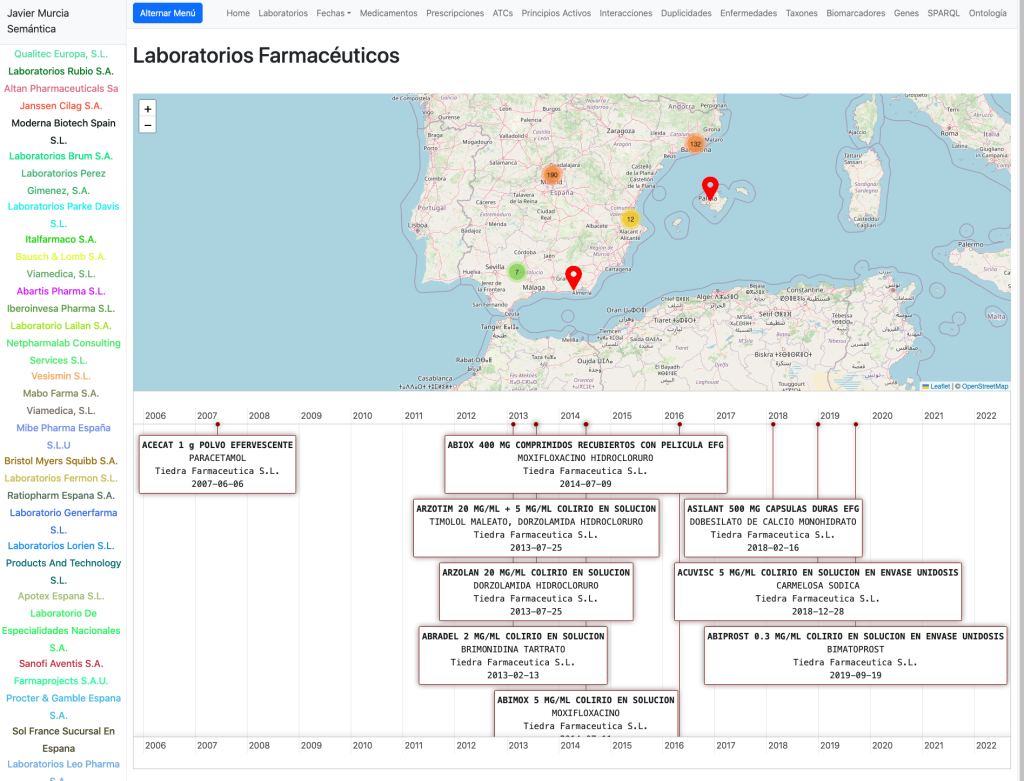
En la Home comenzamos con un listado de Laboratorios farmacéuticos que tienen una sede en España desplegados en un mapa. Podemos seleccionarlos y cargar los medicamentos que les corresponden en una línea de tiempo.
Podemos cargar un laboratorio seleccionándolo y cargarlo en una página especial:
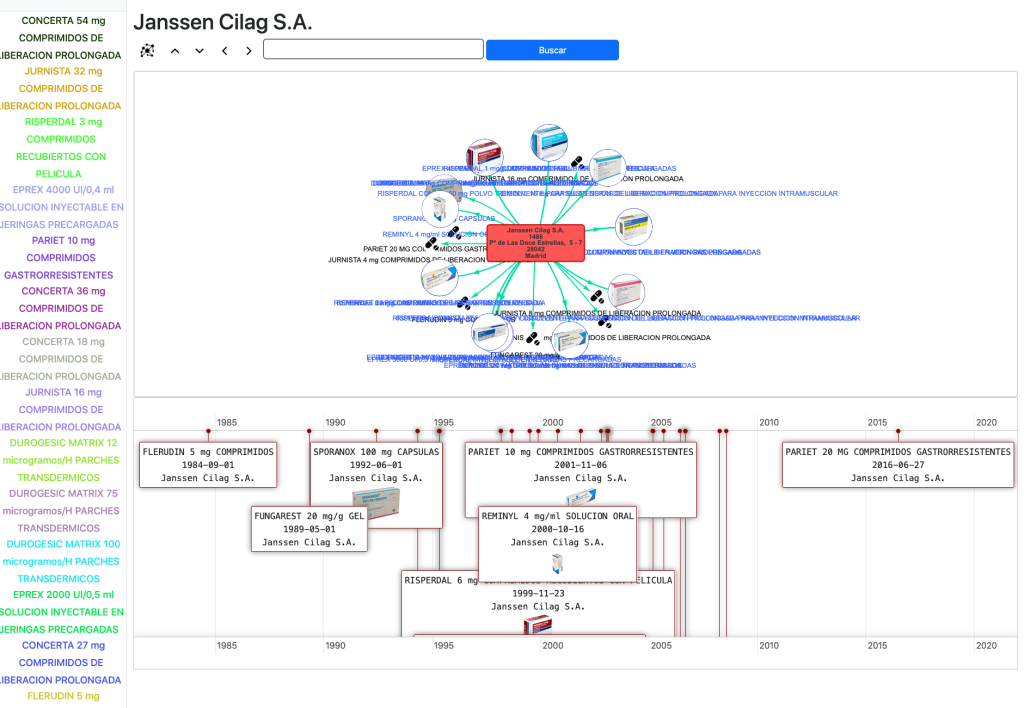
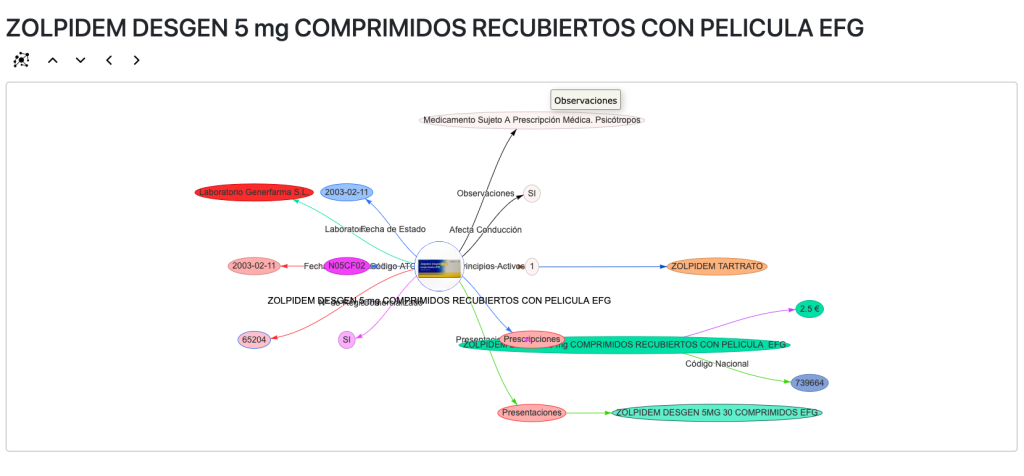
Si seleccionamos cualquier medicamento en la línea de tiempo abrimos una página especial para medicamentos:
En esta y en las siguientes vistas usamos la librería vis.js para visualizar las entidades y relaciones del grafo y navegamos a través del propio grafo haciendo clic en ellas. Podemos cargar los principios activos del medicamento, las prescripciones, los códigos ATC, etc.
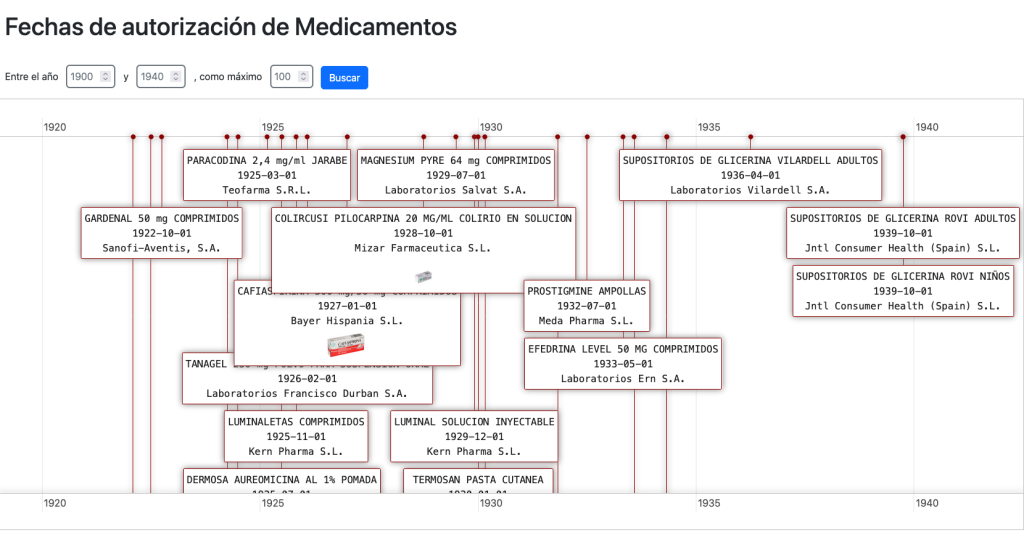
Tenemos una vista donde desplegar medicamentos en una linea de tiempo por fecha de autorización:
…una forma de visualizar la historia de la farmacología.
En la vista Prescripciones se pueden visualizar todas las propiedades de la base de datos Nomenclátor de Prescripciones, y por supuesto muchos de sus nodos son navegables y abren otras vistas:
La vista ATC es particularmente interesante pues podemos navegar por sus jerarquías de códigos a los que se añaden los principios activos y los medicamentos cuando están vinculados:
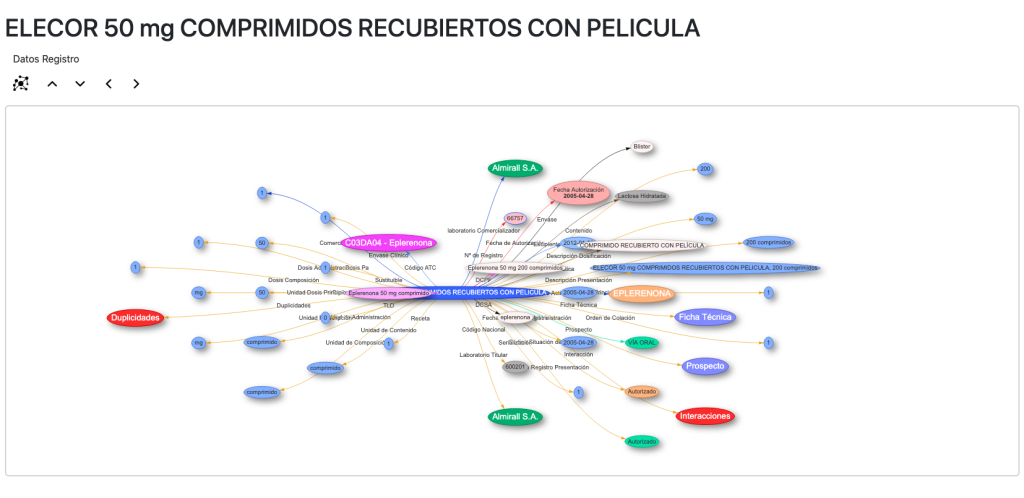
La vista para los principios activos es muy completa. En ella tenemos una descripción, si está disponible y navegación a través de los nodos a a los códigos ATC, clases de sustancia a la que pertenece y enfermedades para las que sirve como tratamiento.
Tenemos también acceso a las posibles interacciones, medicamentos y prescripciones para ese principio activo. Igualmente podemos acceder a nuestro grafo de contexto para ese principio activo (Wikidata):
Además contamos con una vista propia para las interacciones:
Y otra para duplicidades:
Contamos con una vista para las enfermedades, con doble visualización de datos: tanto de Dbpedia como de Wikidata y tenemos navegación por categorías de enfermedades en el panel lateral.
Poseemos vistas para Taxones, Biomarcadores y Genes que aparecen con asiduidad en las relaciones de enfermedades, principios activos…
Verificación
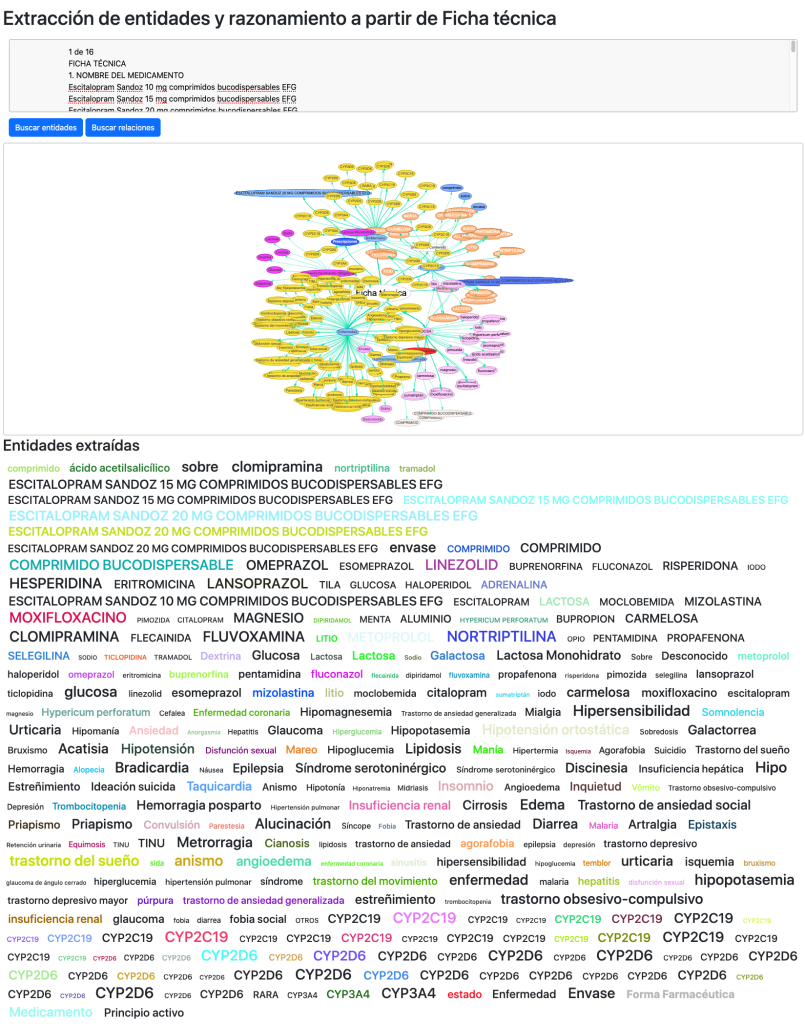
Una prueba de verificación de que las deducciones realizadas han sido acertadas es la comparación entre la ficha técnica de un medicamento y la propiedad «tratamiento para» de su principio activo. Siendo el resultado altamente satisfactorio.
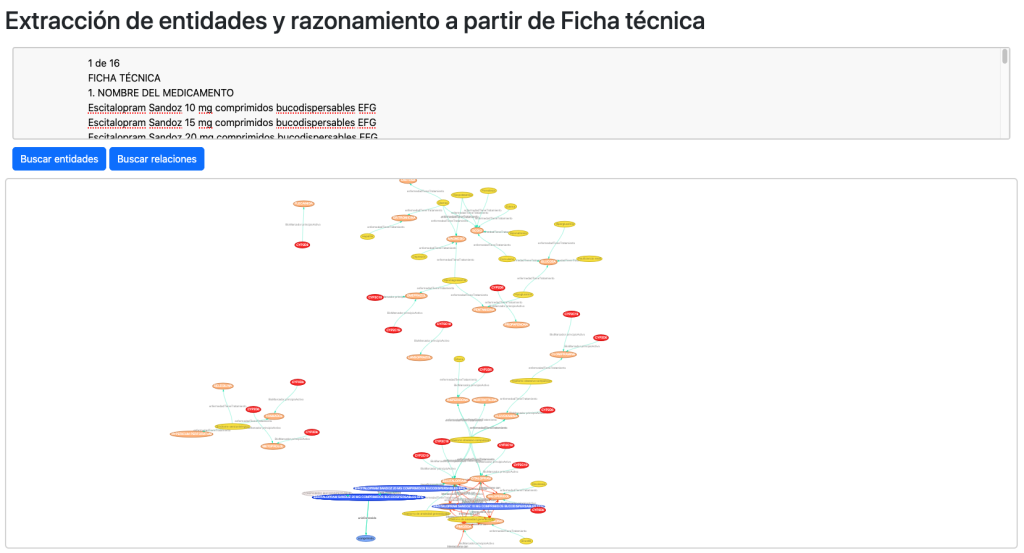
Otro de los test que realizo para comprobar la completitud y capacidad del grafo se muestra en la sección extracción de entidades y razonamiento, donde a partir de una ficha técnica oficial de un medicamento, reconocemos y extraemos entidades gracias al grafo o bien extraemos entidades y las confrontamos entre sí para buscar relaciones entre ellas.
Reconocimiento de entidades:
Extracción de entidades, propiedades y relaciones:
Los resultados son positivos, reconociendo de una única ficha técnica 380 entidades y 131 relaciones relevantes.
Validación con IA Generativa (RAG)
(Knowledge Graph como capa de razonamiento para LLMs)
Realicé un experimento de Retrieval-Augmented Generation (RAG) con el grafo.
Presento una ficha técnica plana a un LLM (Gemini/ChatGPT).
Después Presenté la misma ficha enriquecida con las entidades y relaciones extraídas a partir de mi grafo (CSV estructurado).
Les paso el resultado en csv de la consulta al grafo de medicamentos que extrae entidades y relaciones de la misma ficha técnica que antes les presenté, explicando de que se trata el csv, su estructura y pidiendo que lo usen junto a la ficha para explicar y extraer nuevas conclusiones.
Resultado: Los modelos fueron capaces de explicar contraindicaciones y mecanismos de acción con mucha mayor precisión y contexto biológico al disponer de los datos estructurados del grafo. Esto valida el uso de HealthKG como base de conocimiento para asistentes clínicos inteligentes.
Este proyecto no consiste en consultar genealogías existentes, sino en construir una genealogía ampliada a gran escala mediante inferencia semántica, partiendo de un conjunto mínimo de relaciones primitivas.
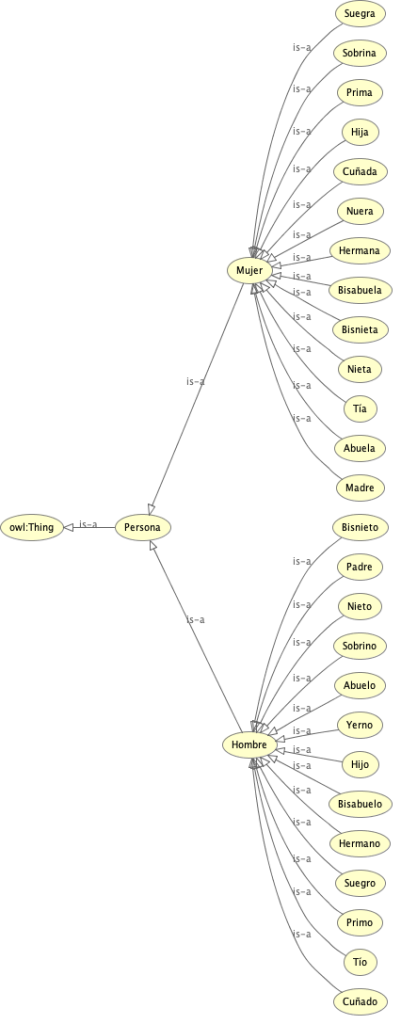
A partir de la propiedad P40 (hijo o hija)de Wikidata se genera, mediante reglas formales, un espacio completo de parentesco: padres, abuelos, tíos, sobrinos, primos, suegros, bisabuelos, etc.
Diseñé un sistema de inferencia genealógica capaz de expandir automáticamente el conocimiento familiar de casi un millón de personas, generando decenas de millones de nuevas relaciones semánticas de forma consistente.
El Desafío:Datos incompletos
En Wikidata hay casi un millón de entidades que son seres humanos y que además tienen hijos. A partir de la propiedad P40, hijo o hija, podemos usarla como propiedad primitiva de la que deducir todas las demás. Wikidata dice quién es hijo de quién, pero no quién es primo de quién.
Explosión Combinatoria Controlada
Lo más impresionante de este proyecto no es tener 1 millón de personas, sino calcular relaciones tan alejadas como primos terceros. La cantidad de relaciones crece exponencialmente.
El reto fue gestionar la explosión combinatoria. Calcular relaciones de primer grado es trivial. Calcular relaciones de sexto grado (primos terceros) en un grafo de 1 millón de nodos requiere una estrategia de inferencia optimizada para no colapsar la memoria.
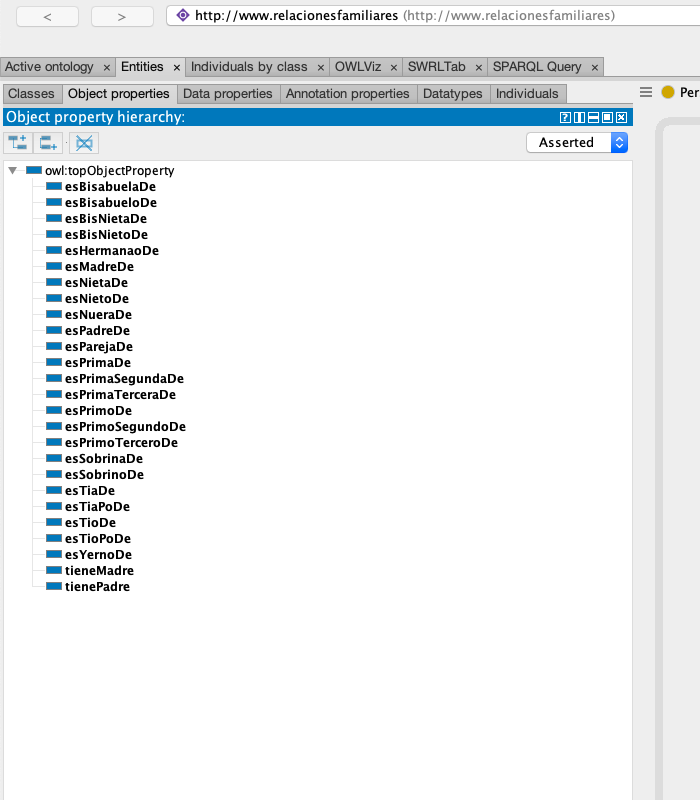
Modelado Ontológico
El primer paso fue crear una ontología minimalista que reflejara los tipos y propiedades fundamentales que rigen las relaciones familiares y genealógicas:
Diseñé una ontología ligera (lite ontology) para maximizar el rendimiento de las consultas, mapeando las propiedades complejas de Wikidata a un esquema simplificado pero transitivo.
Seguidamente generamos y descargamos el dump de Wikidata utilizando Wdumper, para ello se seleccionan las entidades que tienen la propiedad P40, aproximadamente un millón.
Una vez en nuestro poder, se procede a la carga en una TDB2 de Apache Jena Fuseki y comenzamos el proceso de conversión de tipos. Convertimos los tipos básicos de Wikidata a nuestra ontología:
Q5 (Humano)
fami:Persona
Q6581097 (masculino)
fami:Hombre
Q6581072 (femenino)
fami:Mujer
P22 (padre)
fami:tienePadre
P25 (madre)
fami:tieneMadre
P3373 (hermano o hermana)
fami:esHermanaoDe
P26 (cónyuge)
fami:esParejaDe
P40 (hijo o hija)
fami:esPadreDe fami:esMadreDe
Ahora ya estamos en disposición de utilizar reglas de inferencia o deducción, para a partir de estas relaciones primitivas, deducir todas las demás.
La Estrategia de Inferencia
La Lógica de Inferencia
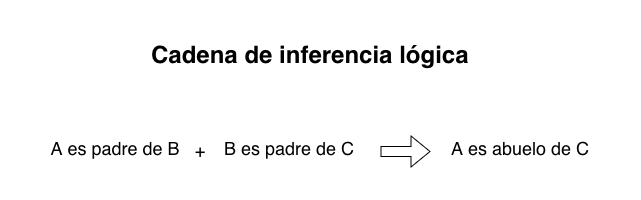
Para deducir relaciones complejas, descompusimos los vínculos familiares en reglas lógicas basadas en cláusulas de Horn. Por ejemplo, la regla para deducir a una «Tía Materna» se define conceptualmente así:
Mujer(a)∧Hermana(a,b)∧Madre(b,c)→Tía(a,c)
Traducción: Si A es mujer, y A es hermana de B, y B es madre de C; entonces A es tía de C.
Implementación
dato → modelo → conocimiento inducido
Inicialmente, implementé un motor de inferencia basado en reglas (Jena Rules) ejecutado en memoria.Tenemos a nuestra disposición, de este modo, un sistema muy completo y robusto para elaborar las inferencias que deseo:
Este tipo de reglas funcionan muy bien y resulta muy interesante experimentar con ellas y observar como en cada consulta se generan los nuevos nodos para concluir la inferencia. Pero por desgracia todo ocurre en memoria y sólo resulta útil para pequeñas cantidades de datos. Sin embargo, dada la magnitud del grafo (1 millón de nodos semilla), el consumo de RAM se volvió insostenible.
Para solucionar este cuello de botella, re diseñé la arquitectura de inferencia trasladando la lógica a la base de datos mediante inserciones constructivas SPARQL en cascada. Esto permitió procesar relaciones complejas (hasta primos terceros) persistiendo los datos en disco paso a paso, garantizando la estabilidad del sistema.
La solución, por tanto, fue transformar cada regla lógica en una operación SPARQL de materialización del conocimiento, convirtiendo el razonamiento dinámico en conocimiento persistente dentro del grafo. Esta estructura permite realizar inserciones masivas en la base de datos de manera eficiente.
A continuación, el script utilizado para inferir la relación fami:esTiaDe:
# Regla de Inferencia: Tía Materna# Objetivo: Deducir tías basándonos en la relación de hermandad y maternidad.
PREFIX rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#>
PREFIX fami: <http://www.relacionesfamiliares/>
INSERT {
# La Inferencia (Lo que el grafo aprende)
?a fami:esTiaDe ?c .
?a rdf:type fami:Tía .
}
WHERE {
# Las Condiciones (Lo que el grafo ya sabe)
?a rdf:type fami:Mujer . # 1. 'a' debe ser mujer
?a fami:esHermanaoDe ?b . # 2. 'a' es hermana de 'b'
?b fami:esMadreDe ?c . # 3. 'b' es madre de 'c' (el sobrino/a)
}Lenguaje del código:PHP(php)
Diseñé una ejecución en cascada (Batch Processing) donde las reglas se ejecutan en un orden estricto, de tal modo que las posteriores basen sus deducciones en las propiedades anteriores:
Nivel 1: Padres e Hijos (Datos crudos).
Nivel 2: Hermanos y Parejas (Inferidos del Nivel 1).
Nivel 3: Tíos, Abuelos y Nietos (Inferidos del Nivel 2).
Nivel 4: Primos y Primos Segundos (Inferidos del Nivel 3).
El sistema transforma un conjunto mínimo de hechos biográficos en una estructura de parentesco completa, haciendo explícitas relaciones que no existían en los datos originales.
El uso del sistema de reglas de Jena fue una prueba conceptual. Demostró que el modelo lógico era correcto, pero no era escalable: las inferencias se realizan en memoria y no pueden sostener un grafo de casi un millón de personas.
Esta arquitectura por capas permitió generar más de 14 millones de nuevas relaciones sin colapsar el servidor, persistiendo cada nuevo descubrimiento permanentemente en el grafo.
La relación mas lejana que he podido procesar ha sido la de primo tercero. Aquí un listado de los tipos y propiedades inferidas, y el número de entidades y propiedades generadas:
Tipos:
fami:Padre
617.285
fami:Madre
327.048
fami:Hermano
48.049
fami:Hermana
18.577
fami:Tío
38.047
fami:Tía
28.027
fami:Sobrino
30.734
fami:Sobrina
20.354
fami:Primo
30.734
fami:Prima
20.354
fami:Cuñado
30.001
fami:Cuñada
27.138
fami:Yerno
151.513
fami:Nuera
158.108
fami:Nieto
259.518
fami:Nieta
135.589
fami:Abuelo
290.979
fami:Abuela
180.322
fami:Bisnieto
215.671
fami:Bisnieta
122.790
fami:Bisabuelo
290.979
fami:Bisabuela
180.322
Propiedades:
fami:esPadreDe – fami:tienePadre
1.078.808
fami:esMadreDe – fami:tieneMadre
674.446
fami:esParejaDe
521.626
fami:esHermanaoDe
243.069
fami:esTioDe
171.313
fami:esTiaDe
98.030
fami:esTioPoDe
115.830
fami:esTiaPoDe
175.045
fami:esSobrinoDe
77.295
fami:esSobrinaDe
54.058
fami:esPrimoDe
306.103
fami:esPrimaDe
220.748
fami:esPrimoSegundoDe
567.860
fami:esPrimaSegundaDe
456.780
fami:esPrimoTerceroDe
1.368.013
fami:esPrimaTerceraDe
1.131.703
fami:esCuñadoDe
83.734
fami:esCuñadaDe
76.267
fami:esSuegroDe
367.997
fami:esSuegraDe
266.293
fami:esYernoDe
271.422
fami:esNueraDe
303.845
fami:esAbueloDe
605.914
fami:esAbuelaDe
430.228
fami:esNietoDe
638.119
fami:esNietaDe
398.027
fami:esBisabueloDe
1.479.216
fami:esBisabuelaDe
1.100.983
fami:esBisNietoDe
804.848
fami:esBisNietaDe
559.830
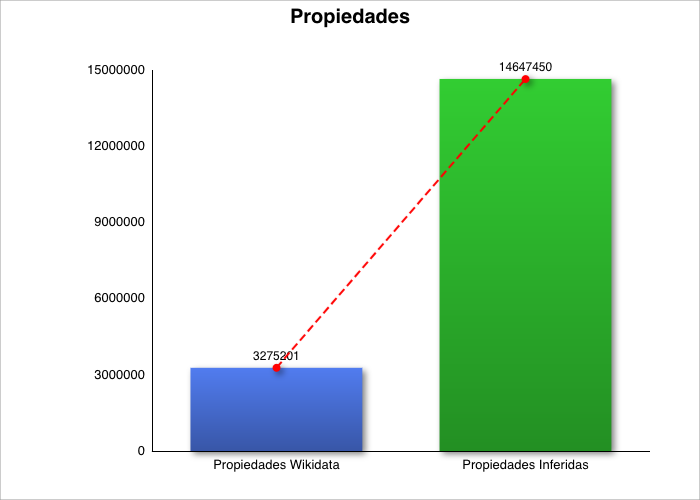
A partir de menos de un millón de personas y unas pocas propiedades primitivas, el sistema generó más de 40 millones de triples, de los cuales:
Casi 2 millones son nuevas afirmaciones de clase,
Más de 14 millones son nuevas relaciones familiares explícitas,
Alcanzando relaciones de hasta tercer grado de consanguinidad.
Partiendo de 1 millón de relaciones ‘padre/hijo’, el sistema generó más de 14 millones de nuevas relaciones semánticas. Por cada dato explícito, el sistema infirió 14 datos implícitos.
El resultado es un motor de genealogía semántica, capaz de:
Expandir automáticamente redes familiares,
Detectar parentescos complejos,
Validar la coherencia de grupos históricos,
Cruzar genealogía con tiempo, espacio y categorías culturales.
Propiedades de relaciones familiares presentes en la extracción de Wikidata:
P22 (tiene padre)
540.417
P25 (tiene madre)
335.367
P3373 (hermano hermana)
161.007
P26 (esposo/a)
468.102
P40 (tiene hijo/a)
1.770.308
Total Wikidata
3.275.201
Total propiedades inferidas
14.647.450
Datos Originales (Wikidata) vs Datos Enriquecidos
La aplicación web: una exploración multidimensional
Para explotar el grafo generado y mostrar sus capacidades ideo una aplicación web basada en grafo centrada en el descubrimiento semántico.
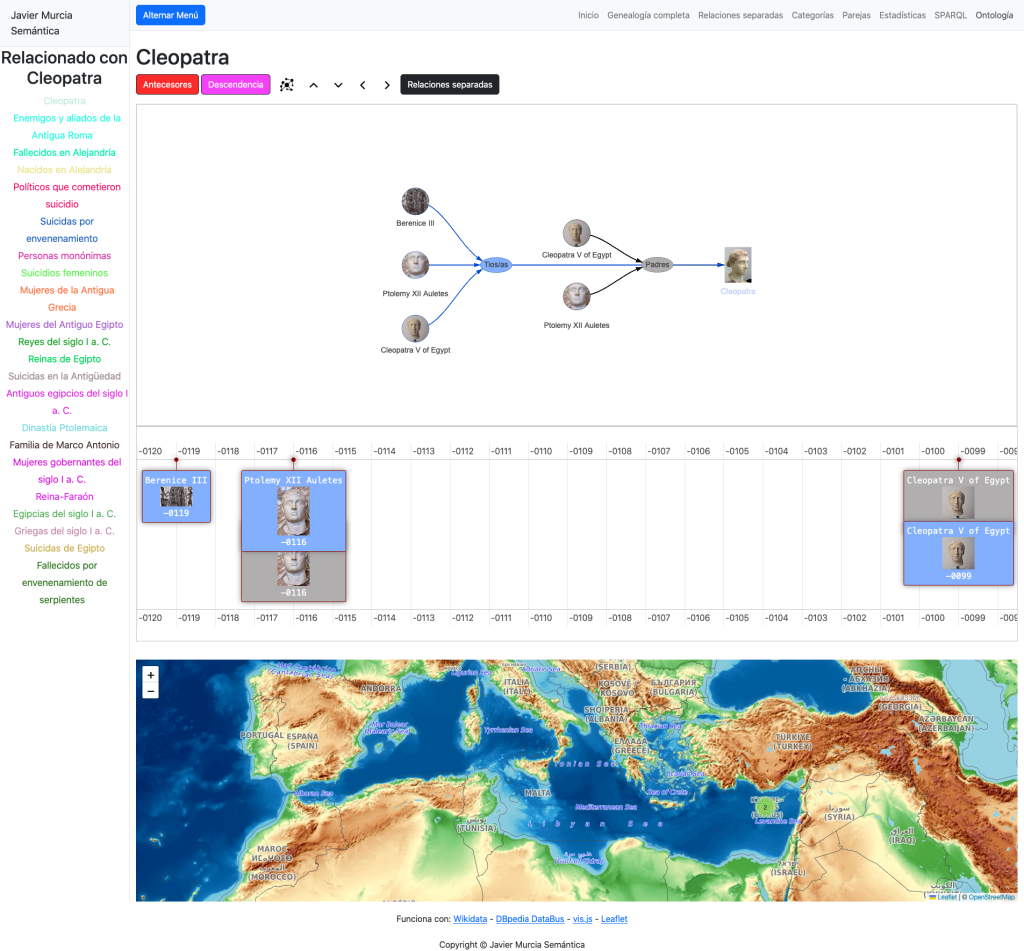
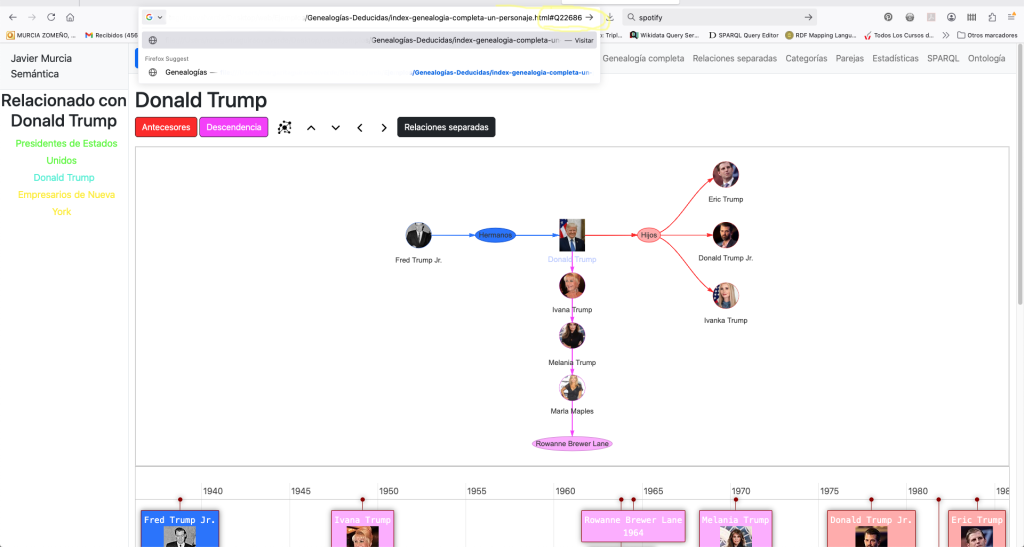
Las vistas cubren cuatro elementos o dimensiones del personaje en cuestión. En la parte superior tenemos las relaciones familiares o genealógicas propiamente dichas:
La aplicación no muestra árboles genealógicos estáticos, sino que permite explorar las relaciones familiares desde cuatro dimensiones:
Parentesco (grafo)
Tiempo (línea de vida)
Espacio (mapa)
Contexto cultural (categorías de Dbpedia)
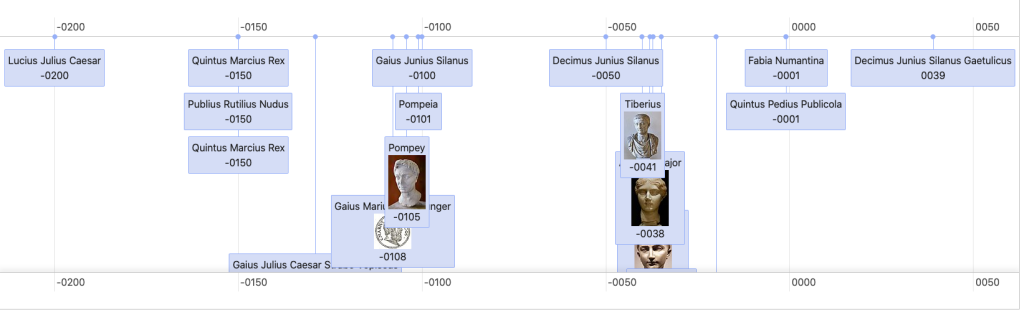
Debajo de ella, encontramos una línea de tiempo donde se disponen las mismas personas relacionadas según su fecha de nacimiento para visualizar en la dimensión temporal las genealogías.
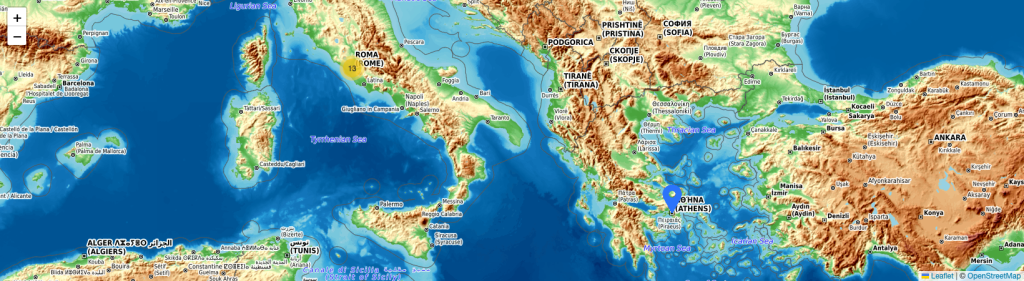
La tercera vista es la geográfica, gracias a una consulta buscamos, si existe, la ciudad de nacimiento de todos los familiares y los ubicamos en una mapa. Conseguimos así seguir las relaciones entre el parentesco y su dispersión geográfica.
Como siempre es posible rizar el rizo y puesto que resulta relativamente sencillo saltar de las entidades de Wikidata a las de Dbpedia, cargamos las categorías a las que pertenece el personaje, si es que tiene:
Categorías que nos sirven para cargar nuevas personas vinculadas a ellas y para abrir una nueva página especial para categorías. En ella se despliegan en un mapa y en una línea de tiempo las personas que pertenecen a ella:
Validación del grafo a través de categorías históricas
Además, las categorías nos sirven para poner en marcha un algoritmo que pone a prueba la exactitud de las inferencias realizadas: Buscar Parentesco, que intenta buscar parentescos familiares entre los miembros de la categoría cargada.
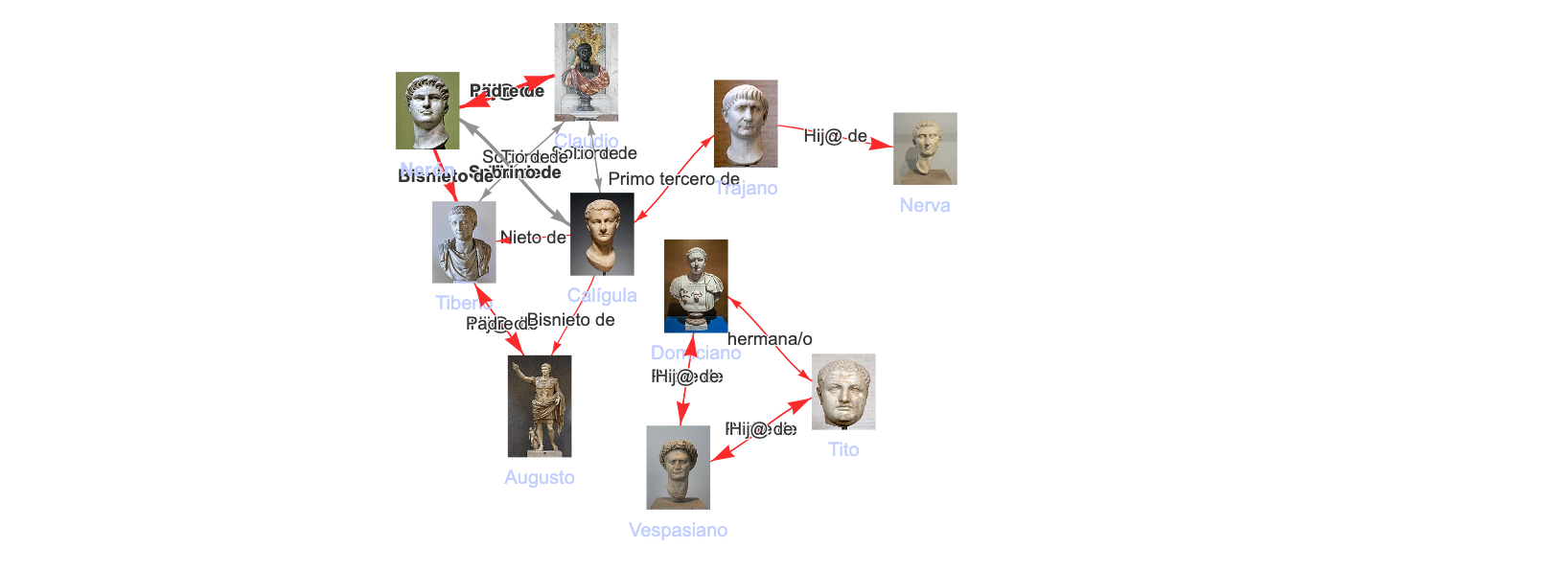
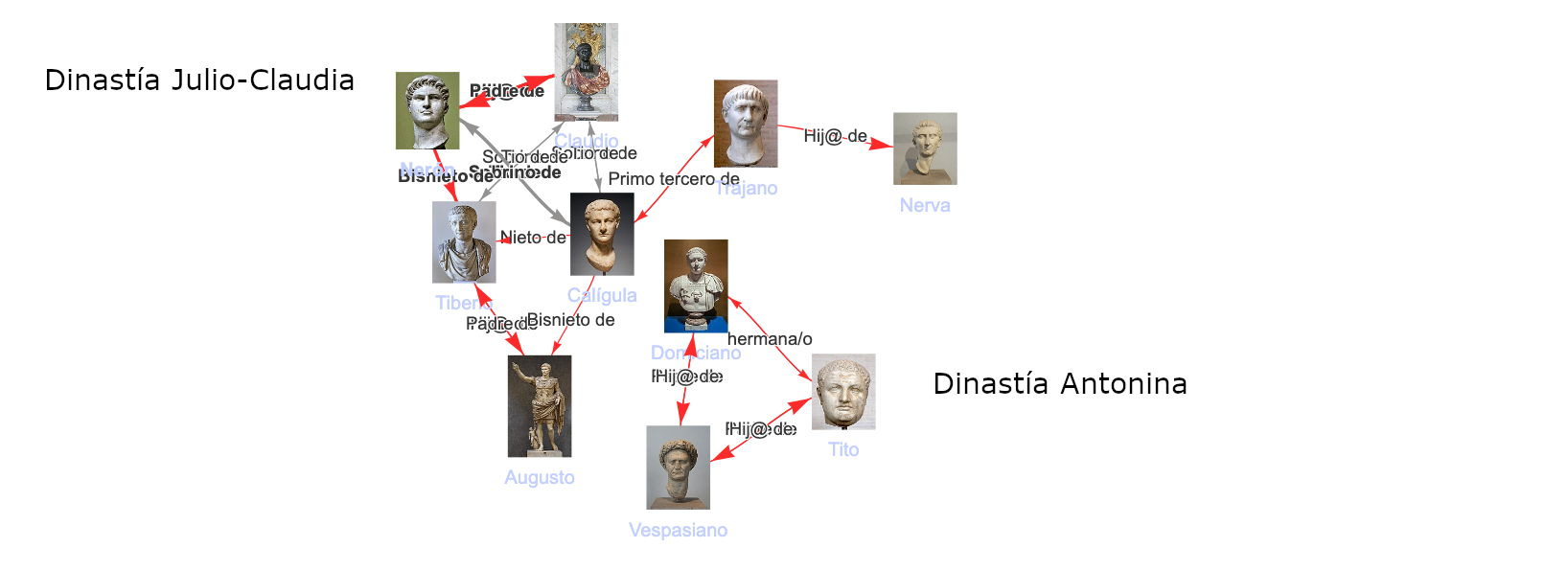
Se trata de un test lógico. El sistema demuestra su corrección cuando detecta automáticamente que los emperadores romanos del siglo I pertenecen a dos dinastías sin vínculo genealógico directo. A través de este y otros ejemplos, conseguimos un caso de validación semántica.
Comprobamos que las inferencias se han ejecutado correctamente puesto que los Emperadores de Roma del siglo I pertenecieron a dos dinastías o familias sin vínculos directos entre ellas, y eso es lo que refleja el algoritmo cuando busca los parentescos:
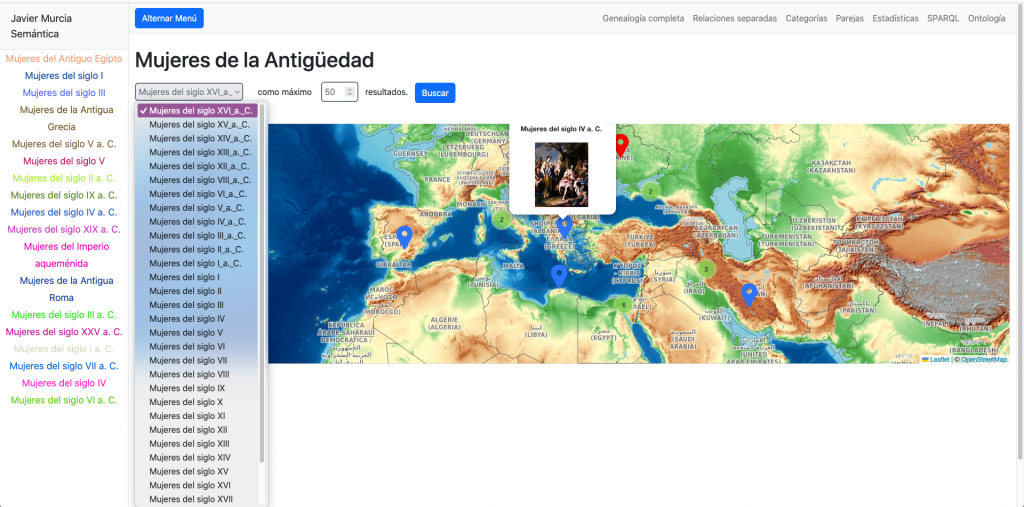
Ante el desequilibrio existente entre hombres y mujeres en el grafo. Algo de lo que no podemos culpar a Wikidata sino a nuestra propia cultura. Decido iniciar el proceso de descubrimiento semántico con una página que permite cargar categorías de mujeres por siglos:
De este modo, el proyecto pone de manifiesto sesgos estructurales en los datos históricos y ofrece herramientas para explorarlos activamente, como la navegación específica por mujeres históricas por siglos.
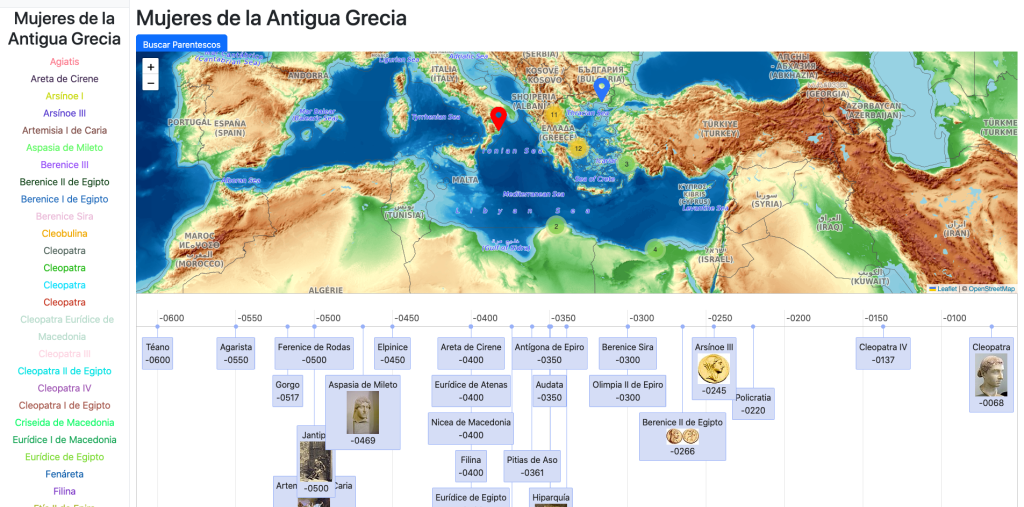
A partir de este inicio de navegación podemos cargar una categoría en concreto como por ejemplo: «Mujeres de la Antigua Grecia«:
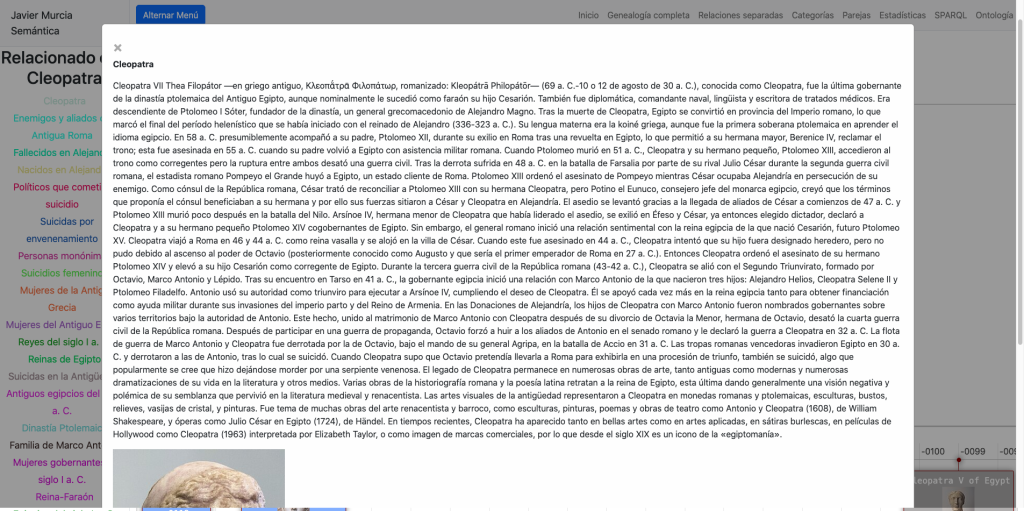
Y seguidamente seleccionar una mujer y cargar su genealogía y relaciones familiares en detalle:
En estas vistas podemos cargar nuevas personas haciendo clic o doble clic así como cargar textos explicativos sobre cada una, extraídos de Dbpedia. De modo que podemos recorrer líneas familiares a través de la historia a golpe de clic, explorando durante horas.
Otro detalle a tener en cuenta es que podemos incluir el Qname de Wikidata de cualquier persona en la URL, y tratar de rescatar sus relaciones familiares o genealogía:
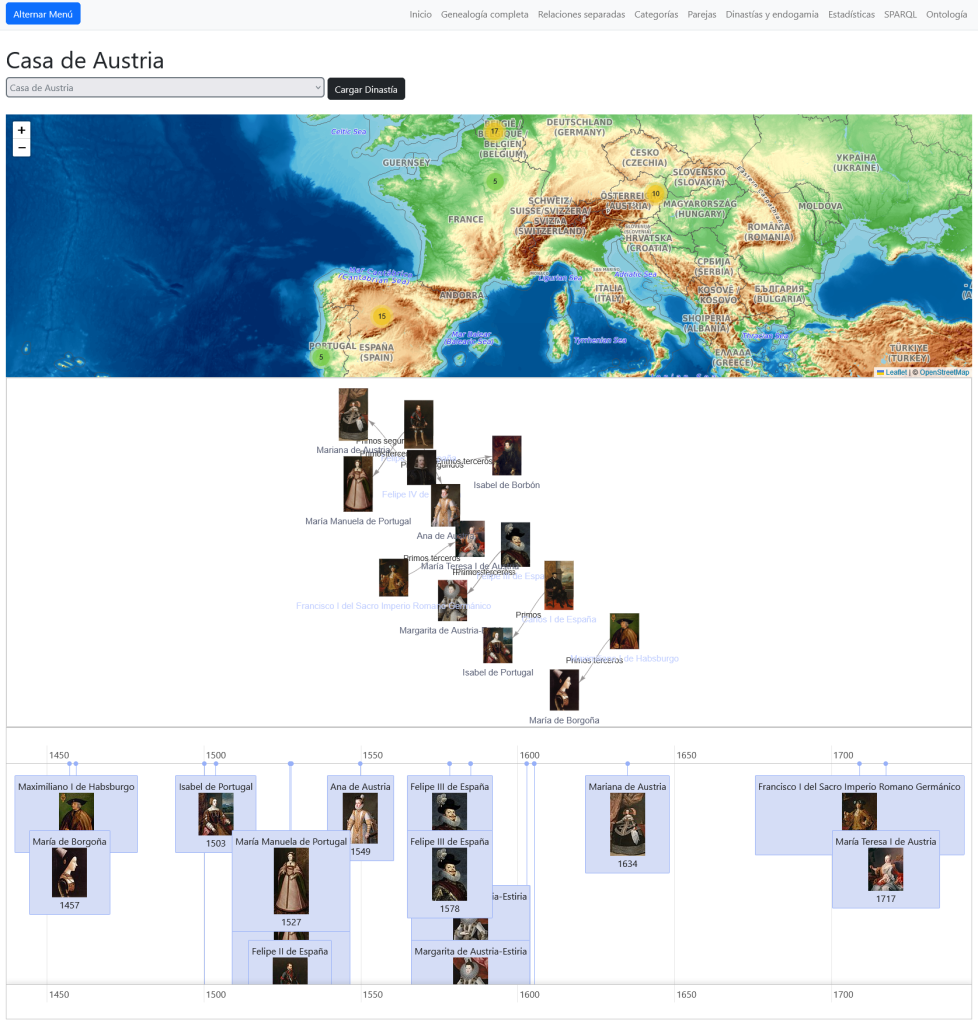
Análisis de Endogamia Histórica
Como ejemplo de uso que puede ser ampliamente desarrollado he creado una sección donde visualizar personas que tuvieran parentesco y además fueran pareja: hermanos, primos, primos segundos…
En una sección especial, como caso de uso, analizamos los parentescos de diversas dinastías europeas para comprobar parentescos cercanos entre parejas.
Conclusión: Del Dato Genealógico a la Inteligencia de Redes
Este proyecto ilustra el potencial de la Web Semántica y los Grafos de Conocimiento para descubrir patrones ocultos en grandes volúmenes de datos (Big Data). Hemos pasado de un listado de nacimientos a una red compleja que permite analizar la dispersión geográfica de familias, detectar endogamia histórica y visualizar dinastías completas en tiempo real.
La capacidad para modelar ontologías, gestionar inferencias masivas y construir interfaces de descubrimiento es aplicable a múltiples sectores:
Sector Legal y Administrativo: Gestión avanzada de registros civiles y sucesiones.
Investigación Biomédica: Rastreo de antecedentes genéticos en grandes poblaciones.
Humanidades Digitales: Análisis de redes de poder históricas.
Estudios demográficos.
Sistemas genealógicos profesionales.
Bases de datos históricas.
Los grafos de conocimiento no solo almacenan información, sino que pueden razonar, expandirse y generar nuevo conocimiento estructurado.
Si deseas construir sistemas de inferencia semántica, expandir conocimiento a partir de reglas formales y la inteligencia Artificial Simbólica o transformar bases de datos relacionales en grafos de conocimiento vivos, puedo ayudarte a diseñar la ontología, el modelo de inferencia y la infraestructura técnica.
Las bases de datos relacionales fallan al intentar conectar la multidimensionalidad del arte (patrimonio histórico) (autor, estilo, lugar, tiempo, contexto). Mi objetivo: crear un modelo unificado que permita navegar el patrimonio no por listas, sino por contextos.
El patrimonio cultural español está disperso en múltiples fuentes heterogéneas, con modelos de datos poco interoperables y sin una estructura semántica que permita razonamientos complejos o exploración avanzada.
Este proyecto demuestra cómo construir un grafo de conocimiento unificado de monumentos de España, basado en una ontología propia, integrando Wikidata, Dbpedia y vocabularios institucionales, y explotarlo mediante un front-end semántico.
El objetivo no es solo mostrar datos, sino demostrar un flujo completo de ingeniería semántica: modelado ontológico, extracción masiva de entidades, normalización, enlazado, inducción de conocimiento y publicación web basada en grafos. Es, en definitiva, un proyecto de arquitectura del conocimiento.
La Ontología (El Cimiento)
La ontología parte de un estudio sistemático y se fundamenta en sus definiciones en el Tesauro de Bienes Culturales, Tesauro de Contextos Culturales y en las clases de Wikidata y Dbpedia. Lo que garantiza interoperabilidad.
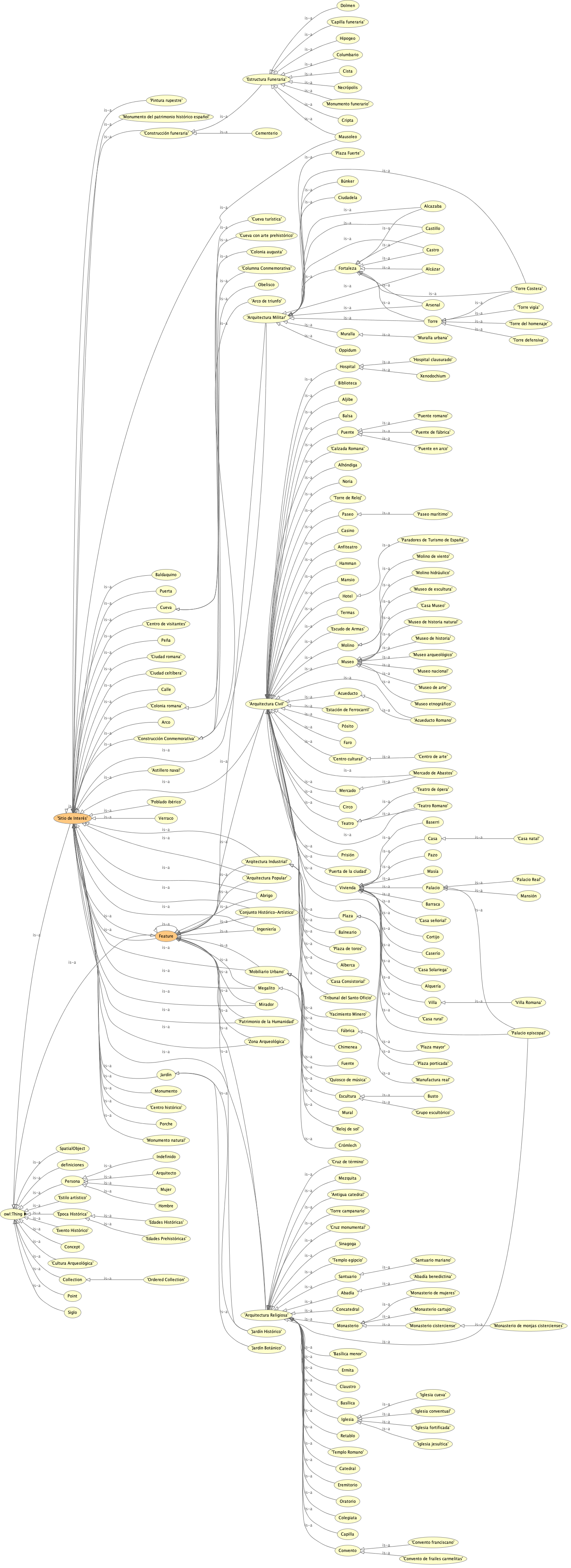
Alrededor de la clase padre Sitio_de_Interés, se organiza la ontología. Esta expresa cualquier tipología ubicable y definible de monumento, resto, etc. Encontramos clases genéricas como Arquitectura Civil, Militar, Religiosa, etc. que subsumen una plétora de clases que definen tipos más concretos como Castillo o Catedral.
La ontología actúa, así, como una “columna vertebral semántica” que permite armonizar datos abiertos, datos colaborativos y vocabularios institucionales.
La dimensión temporal queda cubierta con las clases Siglo y Época Histórica, que nos permiten tratar con divisiones de periodos temporales que estudia la Historia y subsumir así las entidades.
Las clases Estilo Artístico y Cultura Arqueológica aportan divisiones y dimensiones culturales y antropológicas a las entidades.
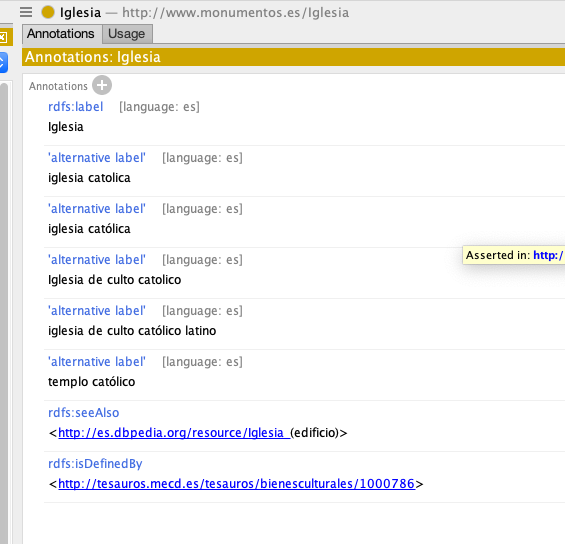
Cada clase y entidad posee, en lo posible, vínculos a sus definiciones en colecciones exteriores (rdfs:isDefinedByrdfs:seeAlso) además de etiquetas alternativas (skos:altLabel) para facilitar búsquedas por palabra en la propia ontología. Esto nos garantiza que las ontología esté interconectada, respaldada por definiciones aceptas ampliamente y con mayor acceso a información.
En resumen la ontología de monumentos:
No es una ontología cerrada.
Es una ontología de integración.
Está alineada con:
Tesauro de Bienes Culturales.
Tesauro de Contextos Culturales.
Clases de DBpedia.
Clases de Wikidata.
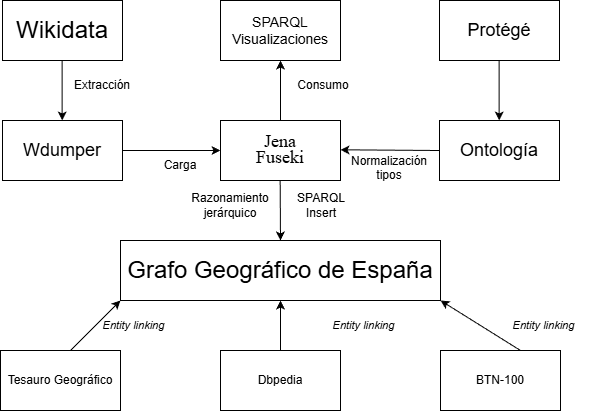
Ingeniería de Datos: Estrategia de Ingesta
Wikidata posee gran cantidad de datos, pero sus clases resultan a menudo caóticas. Para extraer solo la «señal» y descartar el «ruido», optimizando costes computacionales, implementé una estrategia de slicing semántico usando Wdumper.
La extracción es dirigida por ontología y a la vez esta se completa gracias a la extracción. Filtrando solo tipologías de entidades relevantes para monumentos de España.
Esta estrategia permite trabajar con volúmenes masivos de datos manteniendo control semántico y eficiencia computacional, algo imprescindible en proyectos reales de Web Semántica.
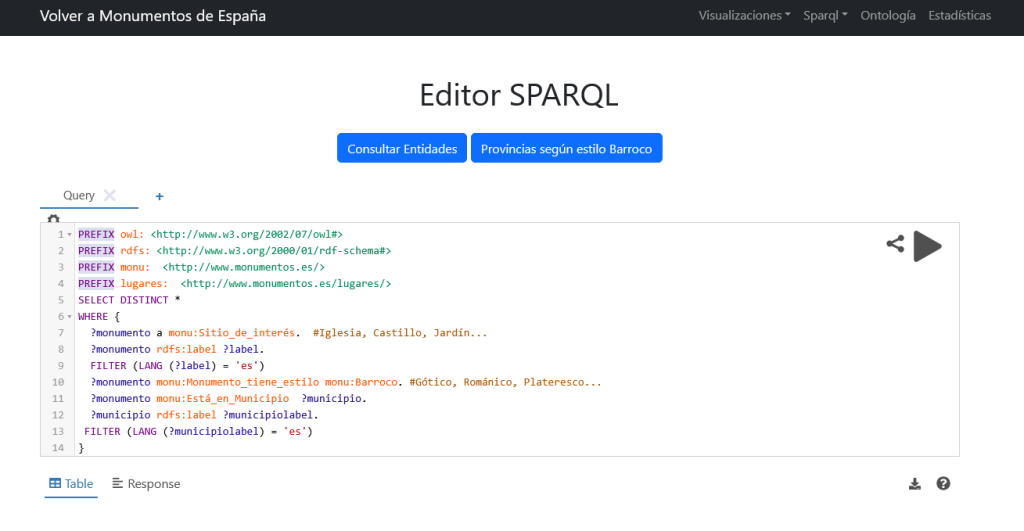
Las extracciones son montadas en una TDB2 de Apache Jena Fuseki, y mediante consultas Insert de SPARQL los tipos y propiedades son mapeados a la ontología, obteniendo la estructura lógica deseada.
El Corazón del Sistema: Enriquecimiento y Normalización
Normalización Geográfica: Gracias a mi grafo geográfico de Lugares de España, corregí la anarquía de la propiedad P131 de Wikidata, ubicando cada monumento en su jerarquía administrativa correcta (Provincia/Municipio).
La vinculación de entidades con Dbpedia en español se realiza del mismo modo que el grafo de lugares de España: Por ID/Estructura:Wikidata ↔ Wikipedia ↔ DBpedia (Mapeo directo). (con método robusto basado en schema:about).
Creación de un grafo de apoyo con los Wikilinks de Wikipedia/Dbpedia, que a través de la relación skos:related se relacionan con los Sitios de interés. Los Wikilinks son enlaces que se encuentran en los artículos de Wikipedia que dirigen a otros artículos, o entidades de Dbpedia, en nuestro caso.
Generación de contexto Histórico (Wikilinks): No solo importé el monumento, sino su ecosistema. Al traer los Wikilinks y categorizarlos, el grafo sabe qué ‘Sucesos Históricos‘ ocurrieron en el ‘Castillo X‘ y las personas relacionadas con el lugar.
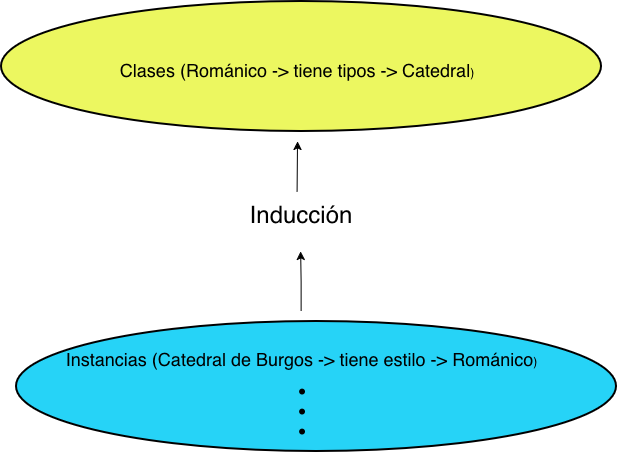
Inducción semántica de conocimiento ontológico
Con lo que tenemos ahora mismo en el grafo y en la ontología somos capaces de hacer consultas como: «¿En qué lugares hay Palacios de estilo Barroco y cuales son sus arquitectos? O mejor aún ¿Qué tipos de monumentos existentes tienen estilo Barroco?
Sin embargo, estas consultas necesitan recuperar primero las propiedades de cada entidad, lo que yo pretendo es inducirlas, es decir, elevar las propiedades de las entidades a las propias clases:
monu:Barrocomonu:tieneTipomonu:Casa_Solariega , monu:Cruz_monumental , monu:Retablo , monu:Plaza_porticada …Lenguaje del código:CSS(css)
Este proceso inductivo eleva propiedades directamente a las clases desde la entidades, generando nuevas relaciones, basadas, en los «datos» y relacionando todas las clases entre si:
tipos con estilos
estilos con siglos
siglos con tipos
tipos con culturas
culturas con siglos
tipos con lugares
…
De este modo construimos un Motor de Recomendación Semántica, transformando datos implícitos en conocimiento explícito.
Antes sabíamos que «La Catedral de Burgos tiene estilo Gótico«. Ahora el grafo sabe que «El Gótico se caracteriza por la presencia de Catedrales«.
Esto permite al frontend sugerir «Tipos de monumentos probables» cuando el usuario filtra por un estilo, sin que un humano haya programado esa regla.
Esto dota al sistema de «sentido común» arquitectónico. El frontend no necesita reglas hardcodeadas; «sabe» qué esperar de un monumento barroco basándose en la evidencia de los datos acumulados, permitiendo filtros predictivos y navegación por descubrimiento.
Obtenemos una ontología que posee mayor conocimiento de la realidad directamente desde sus propias clases.
Las clases dejan de ser solo contenedores.
Se convierten en nodos activos de conocimiento.
Se enriquecen automáticamente desde los datos.
Aparece una ontología viva, no estática.
Uso del grafo como motor de inferencias
Gracias al grafo de monumentos pude realizar el experimento que menciono en Toponimia Histórica (ver en acción) en el que logré situar con plausibilidad 2.594 posibles emparejamientos, en los lugares históricos donde originalmente fueron creados o erigidos los monumento oSitios de interés.
Prueba de que el grafo no solo describe, sino que permite formular hipótesis históricas., y nos permite:
Razonamiento histórico.
Reubicación semántica.
Hipótesis plausibles.
Uso del grafo como motor de inferencias.
Explorador semántico: Visualizando la Inteligencia
Construido para poner a prueba algunas de las capacidades del grafo. La filosofía de la interfaz es la de partir de un Tipo, Siglo, Estilo, Cultura o Edad Histórica y a través de una cadena de consultas SPARQL y gracias a las propiedades inducidas, obtener a parte de los propios Sitios de interés, siglos, estilos, culturas, provincias, arquitectos, personas, eventos históricos, vinculados a esa clase inicial. Estas nuevas clases relacionadas sirven para filtrar la clase principal.
El usuario construye consultas semánticas complejas sin escribir SPARQL. Lo que nos permite una auténtica navegación por grafo de conocimiento.
Se utilizan consultas SPARQL en cadena para cargar todas las relaciones semánticas de la clase y las entidades. Y constituye una interfaz de consulta ontológica de pleno derecho.
Cada nueva clase o lugar fruto de la inducción puede usarse como filtro dentro del resultado principal:
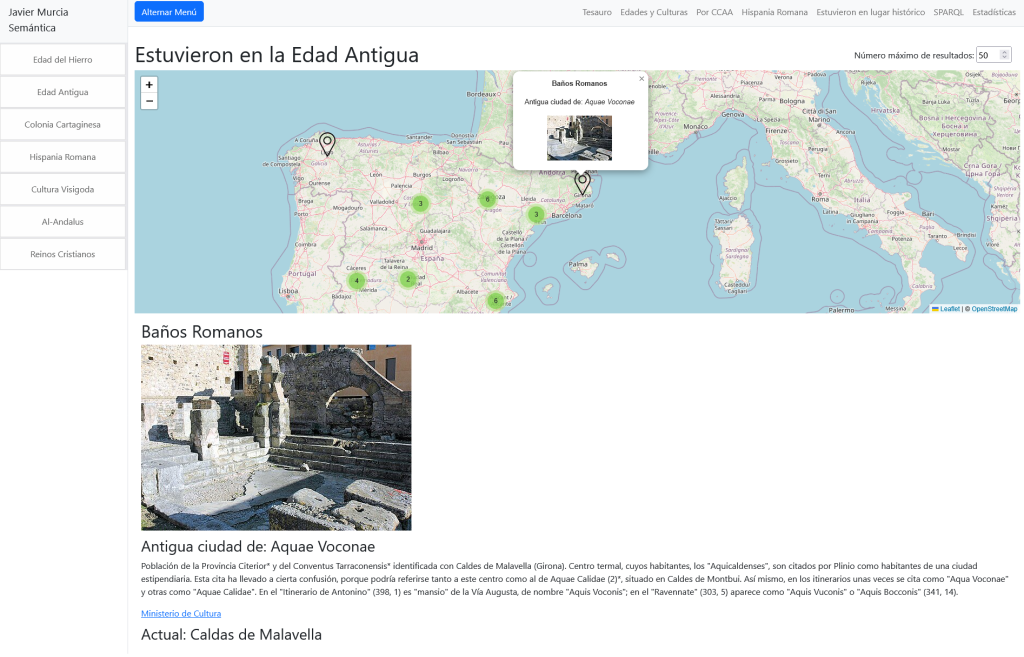
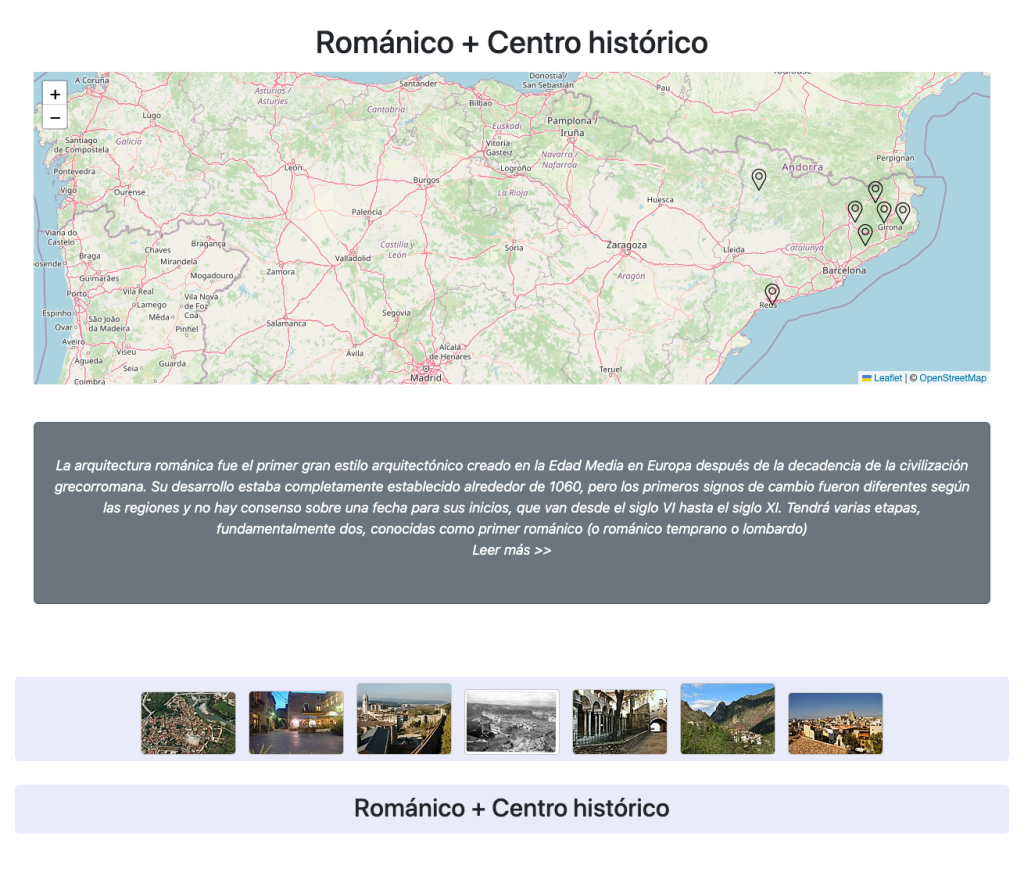
Románico + Centro Histórico
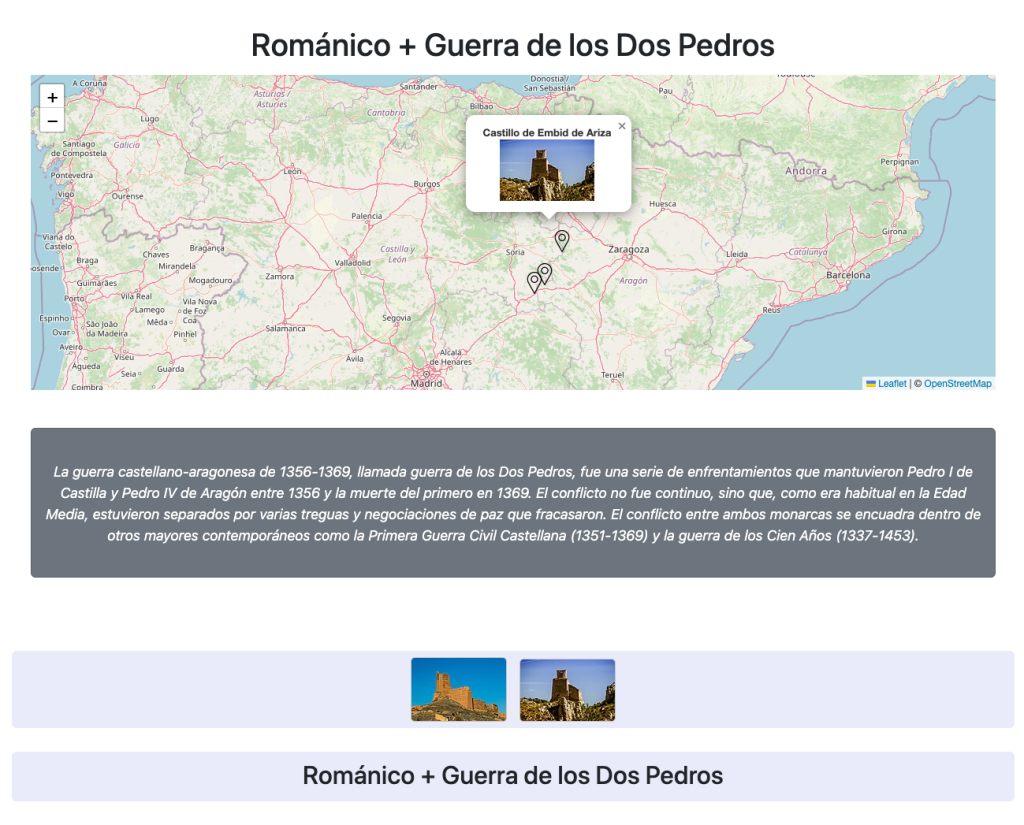
Románico + Guerra de los Dos Pedros
Existe una vista de detalle de cada Sitio de interés haciendo clic o doble clic en él:
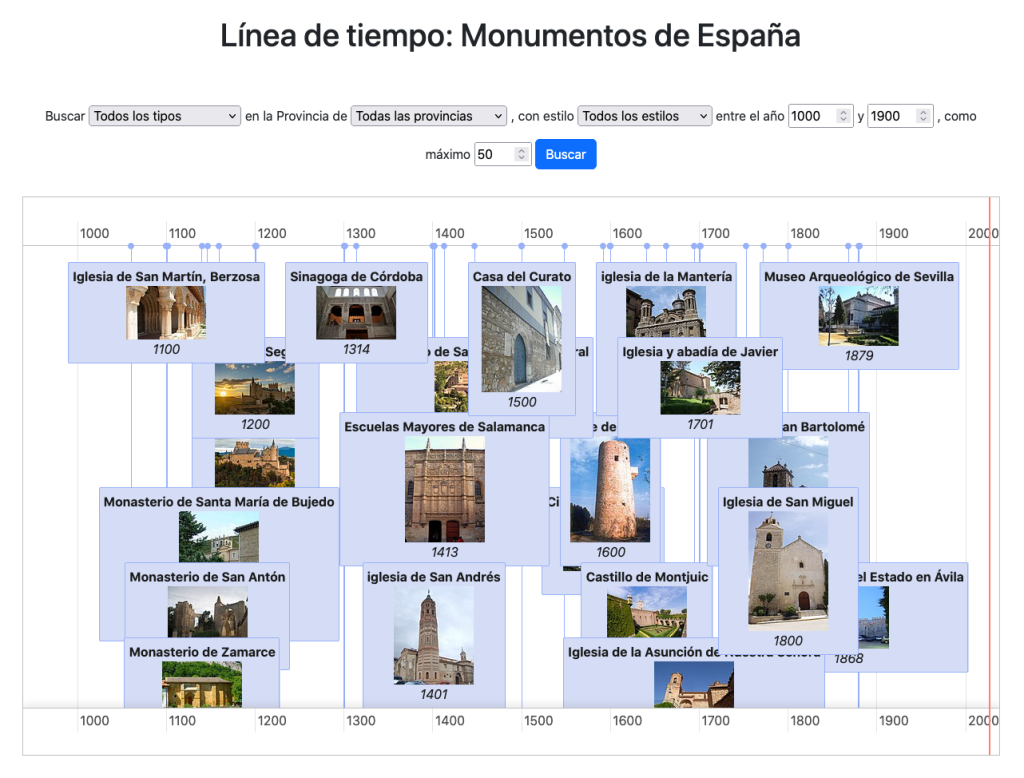
Una línea de tiempo nos permite desplegar los monumentos por fechas y filtrar por tipos, provincias y estilos:
También un editor SPARQL donde realizar consultas y explorar el grafo de monumentos de España:
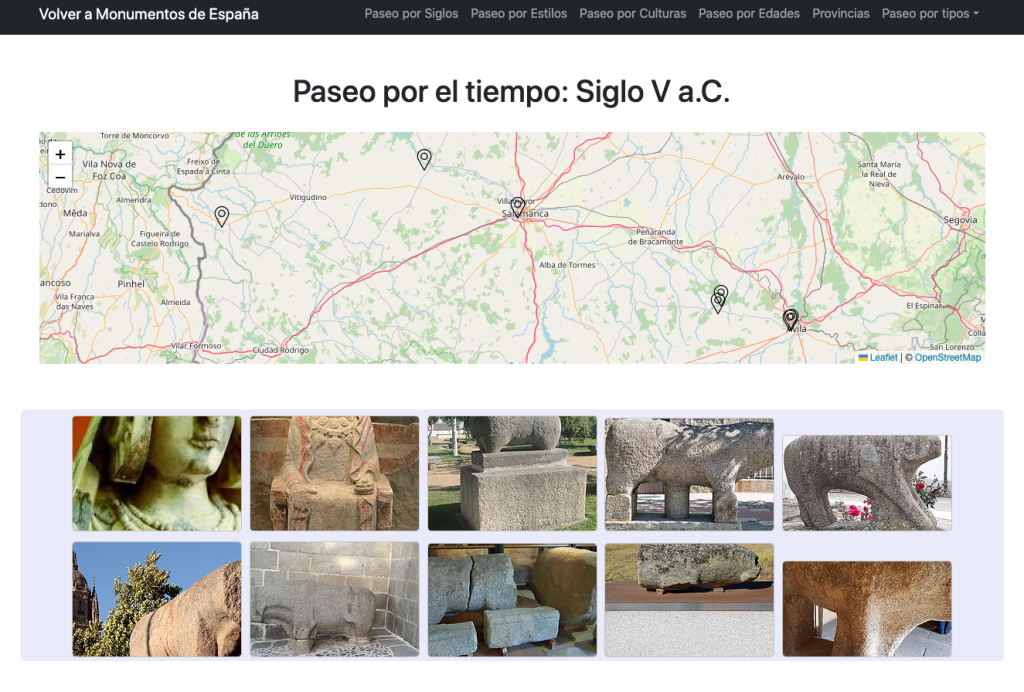
En la sección Paseo por el tiempo uso un bucle de consultas sparql para cargar de forma automática y secuencial monumentos por siglos, estilos, culturas, provincias…generando una experiencia de sucesión temporal gracias al grafo y demostrando su consistencia temporal.
Recomendaciones para una mejora y ampliación del grafo:
Sería posible y deseable transformar, mapear e incluir los datos de monumentos y lugares que poseen las Comunidades Autónomas, e incluso los Ayuntamientos para aumentar y mejorar su alcance.
Añadir elementos arquitectónicos y cualidades artísticas (bóveda de cañón…)
Extracción de entidades de las descripciones para aumentar la densidad del grafo.
La construcción del Grafo de Monumentos de España demuestra que la Web Semántica es mucho más que una tecnología de archivo; es un motor de descubrimiento capaz de transformar datos aislados en activos inteligentes. Al procesar más de 12 millones de tripletas y aplicar razonamiento inductivo, hemos convertido un listado plano en un ecosistema navegable que «entiende» contextos históricos y geográficos.
Estas mismas metodologías de Ingeniería del Conocimiento, normalización de datos heterogéneos y enriquecimiento semántico son directamente aplicables a otros sectores, desde la gestión de catálogos complejos en e-commerce hasta la integración de datos corporativos o sistemas de recomendación inteligente.
Si tu organización necesita romper silos de información, diseñar ontologías a medida o transformar grandes volúmenes de datos en un Knowledge Graph explotable, hablemos. Ofrezco servicios profesionales de consultoría e implementación técnica para llevar tus datos al siguiente nivel de inteligencia.
Los sistemas de información geográfica tienen enormes capacidades, pero no contamos con un grafo que nos proporcione una arquitectura conceptual que nos permita hacer consultas de alta complejidad sobre datos y estructuras geográficas de España.
A pesar de ser abundante, los datos geográficos sobre España están dispersos (IGN, Wikidata, DBpedia), son incoherentes jerárquicamente y difíciles de consultar en su conjunto. Y sobre todo no tienen una base semántica con la que razonar.
Por eso me propuse crear un Grafo de Conocimiento unificado y normalizado. La ontología más el grafo consiguen que tengamos a nuestra disposición razonamiento semántico geográfico para la totalidad del país.
Un grafo geográfico de este tipo debe permitirnos hacer razonamientos del tipo: Una entidad está ubicada en un lugar, ese lugar tiene un tipo (municipio, localidad) y este último está contenido en otras entidades mayores como una provincia. De ese modo obtenemos mayor contexto geográfico y semántico sobre la primera.
Existen grafos semánticos con mucha información geográfica sobre España pero esta se encuentra inconexa y vagamente jerarquizada:
Wikidata: Muy rica fuente de datos, pero las relaciones de dependencia territorial resultan a menudo caóticas.
DBpedia: rica en categorías y descripciones, pero sin información geográfica exacta.
Tesaruo Geográfico del Ministerio de Cultura: fuente normalizada y oficial, pero sin información geográfica exacta.
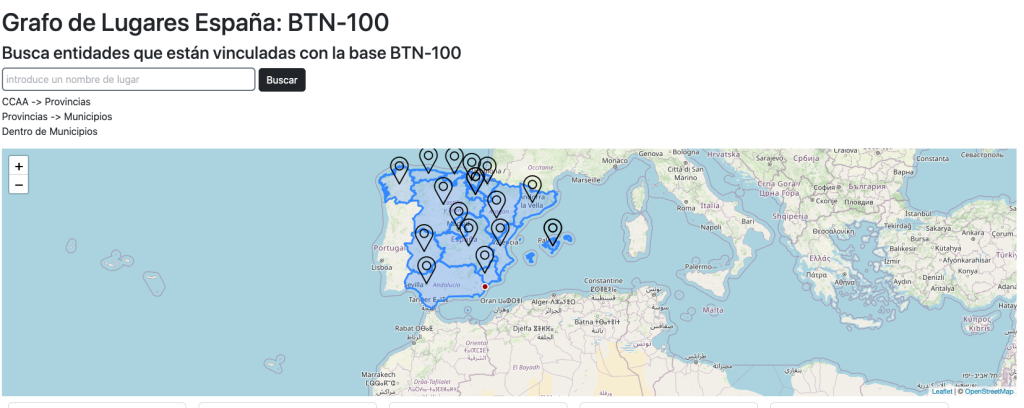
BTN100: tras su transformación a rdf contiene una gran cantidad de información geográfica exacta, pero sus tipos y clases están aisladas del resto de grafos.
Objetivos del proyecto
Construir un grafo homogéneo.
Crear una ontología clara y reutilizable.
Unificar datos de Wikidata, BTN100, DBpedia y Tesauro MEC.
Permitir inferencias geográficas robustas.
Arquitectura y diseño del grafo
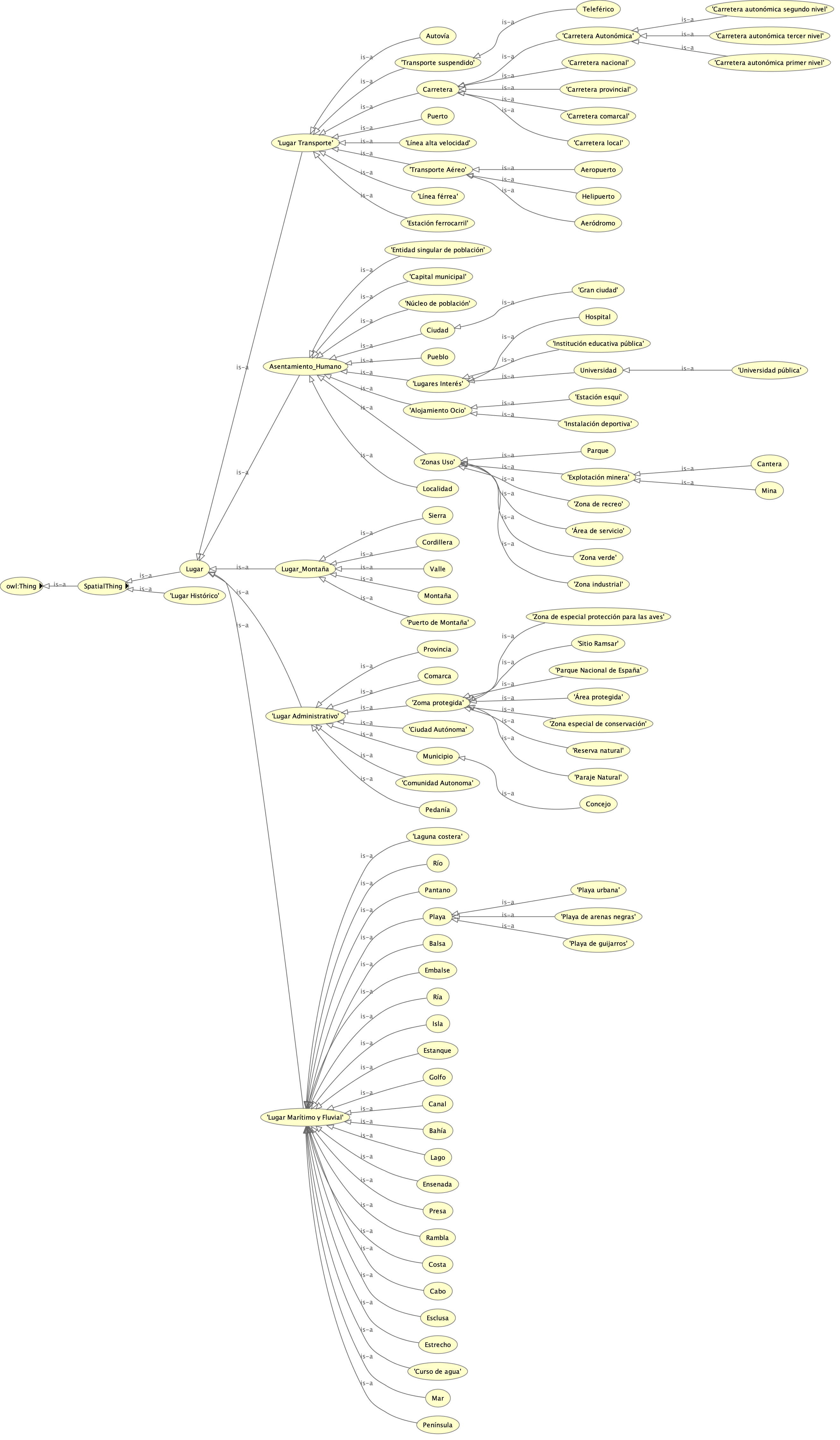
Articulación de las clases
La ontología se fundamenta en la superclase Lugar, que unifica cualquier tipo de entidad que podamos ubicar en el espacio geográfico. De ella dependen varias subclases que agrupan conceptualmente las entidades:
Asentamiento humano.
Lugar Administrativo.
Lugar Marítimo y Fluvial.
Lugar Transporte.
Lugar Montaña.
Las propiedades se mantienen al mínimo que permite la expresividad de relaciones de “contención” entre entidades y sus propiedades inversas.
Decisiones clave de modelado
Como la intención es la creación de un grafo lo más completo posible, creo un modelo híbrido:
De este modo conseguimos un modelo donde podemos preguntar, por ejemplo, por ríos o accidentes geográficos ubicados o contenidos en entidades administrativas, uniendo dos dominios que suelen estar separados en bases de datos relacionales.
Extracción (Wdumper)
Para evitar el coste computacional de procesar el dump completo de Wikidata, implementé una estrategia de slicing semántico usando Wdumper, filtrando solo el subgrafo relevante para la geografía española.
SPARQL avanzado: inserciones masivas y razonamiento jerárquico
Una vez que tenemos los tipos y propiedades gracias a la ontología podemos asignar primero los tipos y después construir las propiedades con eficacia.
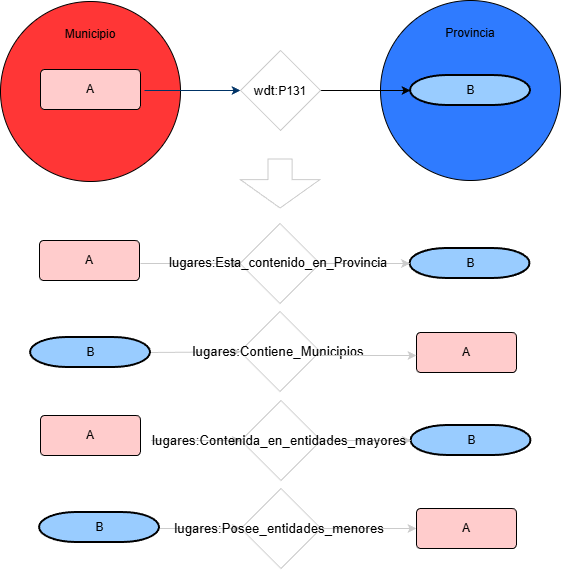
El problema de la Jerarquía (P131)
Uno de los mayores retos de Wikidata es la inconsistencia en la propiedad P131 (located in). Para normalizar la jerarquía administrativa española y permitir inferencias transitivas correctas, diseñé una serie de consultas SPARQL de actualización (INSERT/DELETE) que reordenan la cadena de dependencias:
Algoritmo en forma de SPARQL:
SidosentidadestienenlarelaciónP131: A <P131> B, entonces:
Alugares:Contenida_en_entidades_mayoresBysuinversaBlugares:Posee_entidades_menoresBLenguaje del código:CSS(css)
SidosentidadestienenlarelaciónP131: A <P131> ByBperteneceaunaclaseconunapropiedadquerelacionaalasentidadesdelaclasealaquepertenececonlasentidadesdelaclaseA, entonces,
porejemplo:
SiA <P131> BArdf:typeLugares:MunicipioBrdf:typeLugares:ProvinciaEntoncesAlugares:Esta_contenido_en_ProvinciaBysuinversaBlugares:Contiene_MunicipiosALenguaje del código:CSS(css)
Interconectar entidades entre grafos es la mejor forma de garantizar que nuestros datos sean fiables, completos, interoperables y de tener a nuestra disposición la mayor cantidad de información posible.
Se han usado diversas estrategias de reconciliación:
Por ID/Estructura:Wikidata ↔ Wikipedia ↔ DBpedia (Mapeo directo). (con método robusto basado en schema:about).
Por Texto (Fuzzy): Etiquetas coincidentes con el Tesauro MEC.
Wikidata ↔ BTN100 con normalización lingüística.
Geosparql (Futuro/Intento): la coincidencia por coordenadas es el siguiente paso lógico para desambiguar lugares con el mismo nombre (ej. «Santa María»).
Tarql : Se utiliza como una herramienta de Rapid Prototyping para convertir CSVs «legacy» a RDF limpio.
Propagación inductiva de propiedades a partir de categorías DBpedia
Dado que Dbpedia incluye como skos:Concept las Categorías de Wikipedia, como medio alternativo a los tipos y clases para subsumir entidades. Vinculé dichas categorías a las entidades el grafo como prueba experimental. Aportando así una capa adicional de relaciones al grafo.
El objetivo es añadir más propiedades a cada categoría. Basadas estas en las entidades que contienen, a través de en un proceso “inductivo” para posteriormente rescatar mayor cantidad de entidades de las que posee la categoría originalmente.
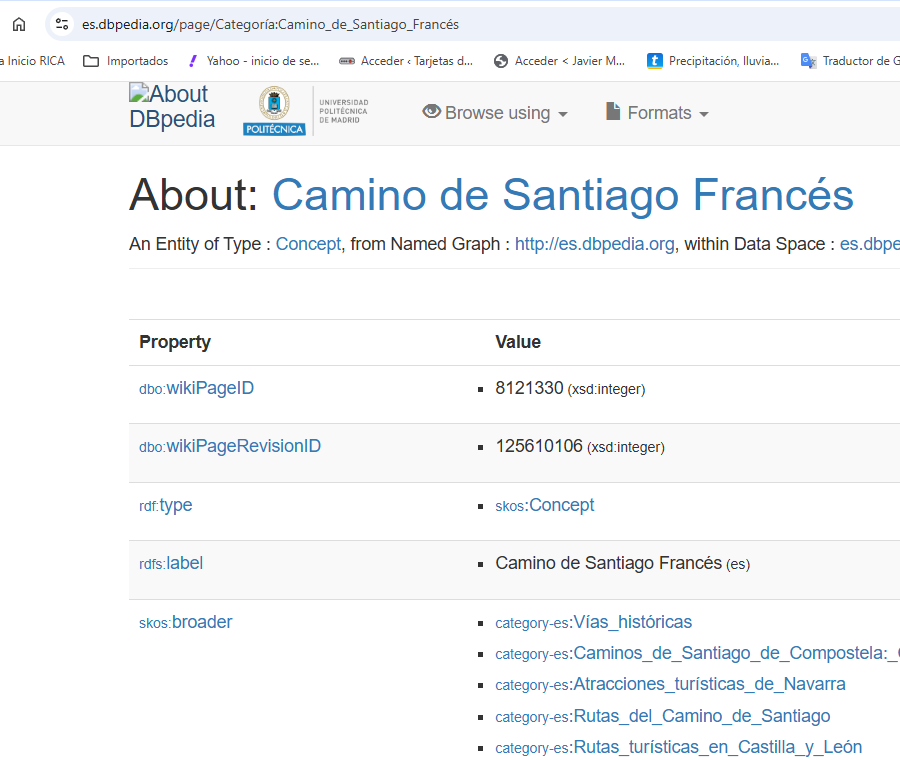
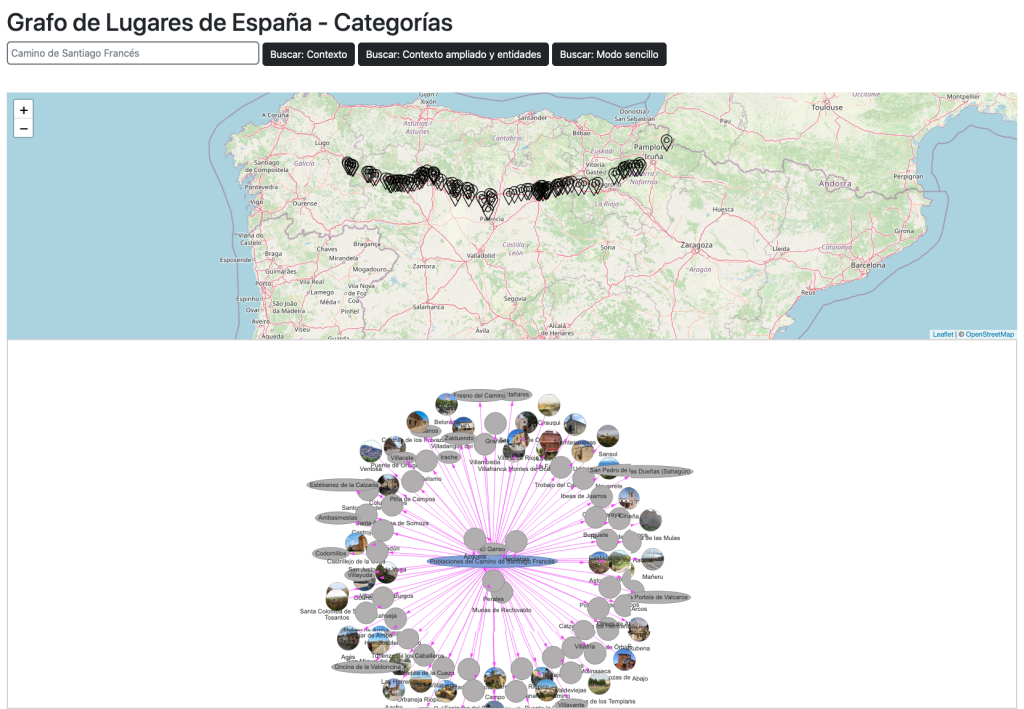
Con la búsqueda de texto: “Camino de Santiago Francés”, accedemos a entidades del grafo que han quedado vinculadas a dicha categoría, en este caso localidades por las que cruza.
Resultados del proyecto
120.000 lugares integrados y armonizados.
100 clases ontológicas.
17 propiedades de objeto consolidadas.
Jerarquías corregidas y unificadas.
Implementación Web
Se implementa una aplicación web donde visualizar los datos y relaciones del grafo. Utiliza las librerías leaftlet.js para mapas, Wicket.js (una biblioteca ligera de Javascript que lee y escribe cadenas de texto bien conocido (WKT)) Vis.js para visualizaciones y Yasgui para implementar un punto SPARQL donde realizar consultas.
Inferencias semánticas que ahora son posibles
Buscar playas dentro de municipios costeros.
Encontrar lugares protegidos dentro de zonas Natura 2000.
Determinar todos los lugares que están dentro de un valle o comarca.
Para ofrecer las mejores experiencias, utilizamos tecnologías como las cookies para almacenar y/o acceder a la información del dispositivo. El consentimiento de estas tecnologías nos permitirá procesar datos como el comportamiento de navegación o las identificaciones únicas en este sitio. No consentir o retirar el consentimiento, puede afectar negativamente a ciertas características y funciones.
Funcional
Siempre activo
El almacenamiento o acceso técnico es estrictamente necesario para el propósito legítimo de permitir el uso de un servicio específico explícitamente solicitado por el abonado o usuario, o con el único propósito de llevar a cabo la transmisión de una comunicación a través de una red de comunicaciones electrónicas.
Preferencias
El almacenamiento o acceso técnico es necesario para la finalidad legítima de almacenar preferencias no solicitadas por el abonado o usuario.
Estadísticas
El almacenamiento o acceso técnico que es utilizado exclusivamente con fines estadísticos.El almacenamiento o acceso técnico que se utiliza exclusivamente con fines estadísticos anónimos. Sin un requerimiento, el cumplimiento voluntario por parte de tu proveedor de servicios de Internet, o los registros adicionales de un tercero, la información almacenada o recuperada sólo para este propósito no se puede utilizar para identificarte.
Marketing
El almacenamiento o acceso técnico es necesario para crear perfiles de usuario para enviar publicidad, o para rastrear al usuario en una web o en varias web con fines de marketing similares.