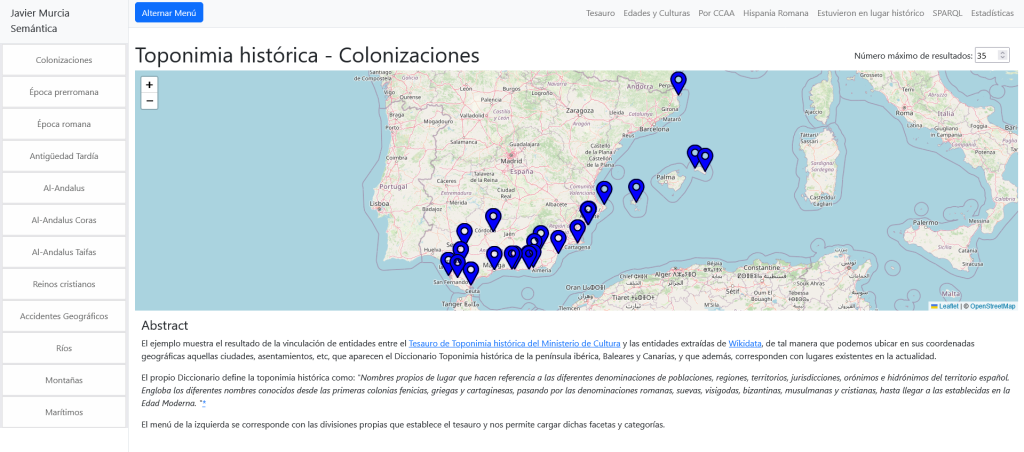
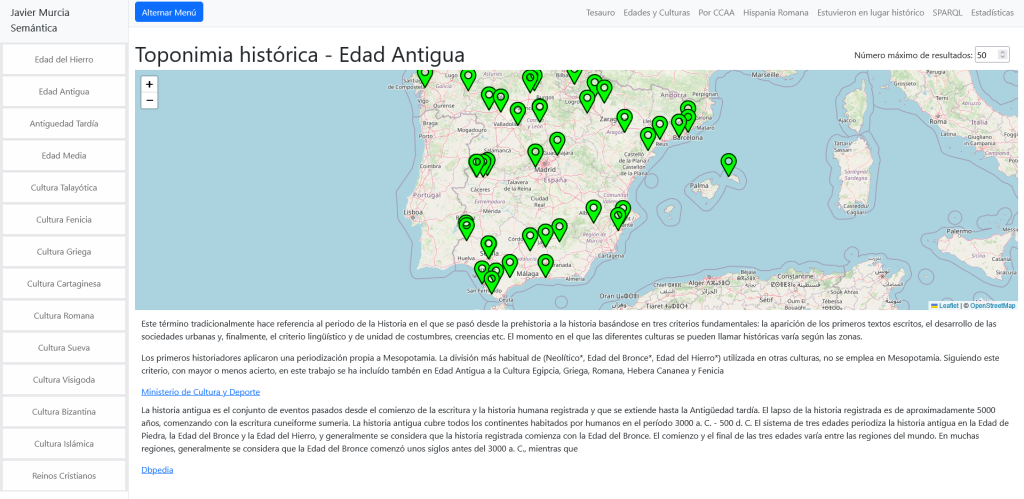
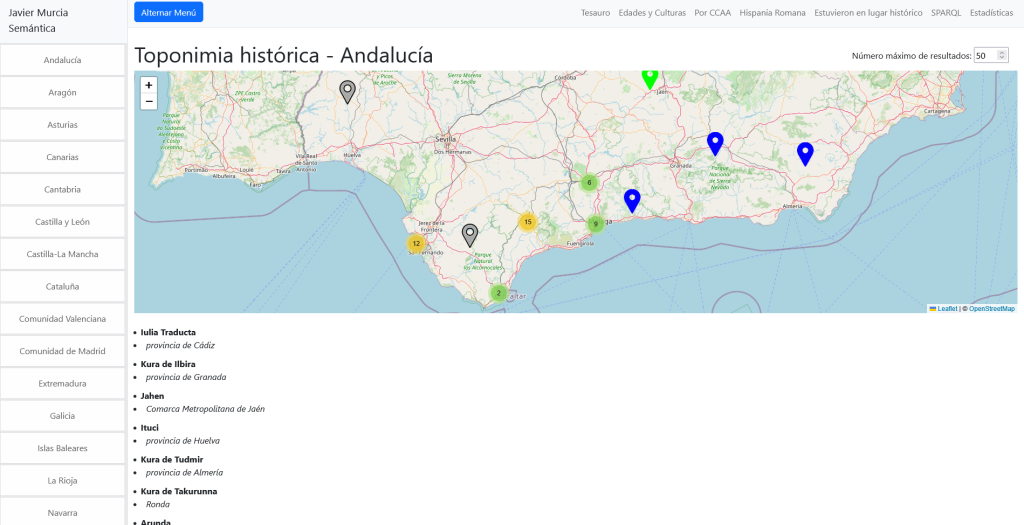
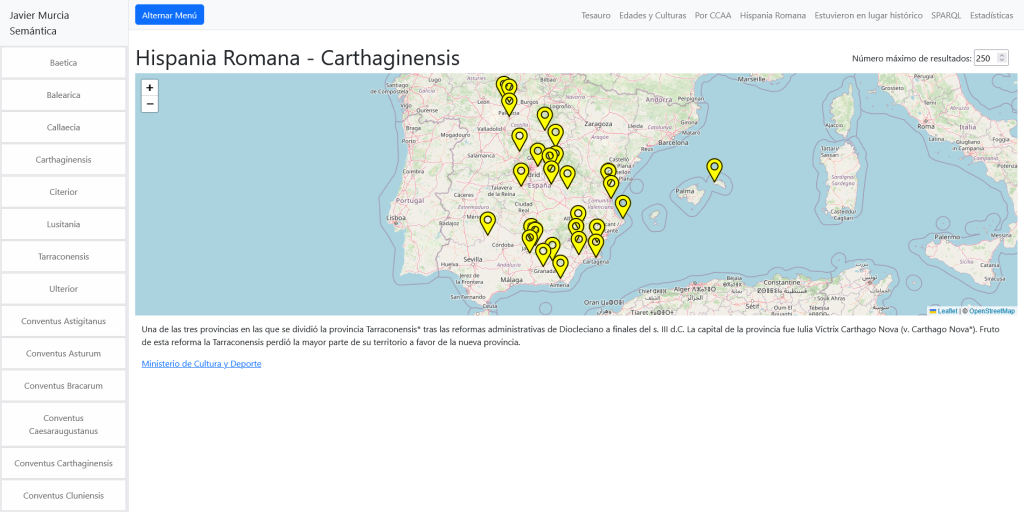
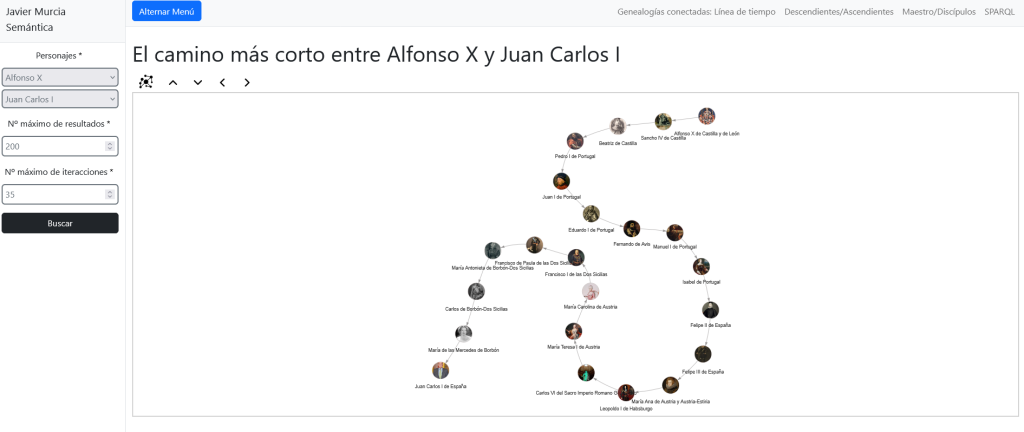
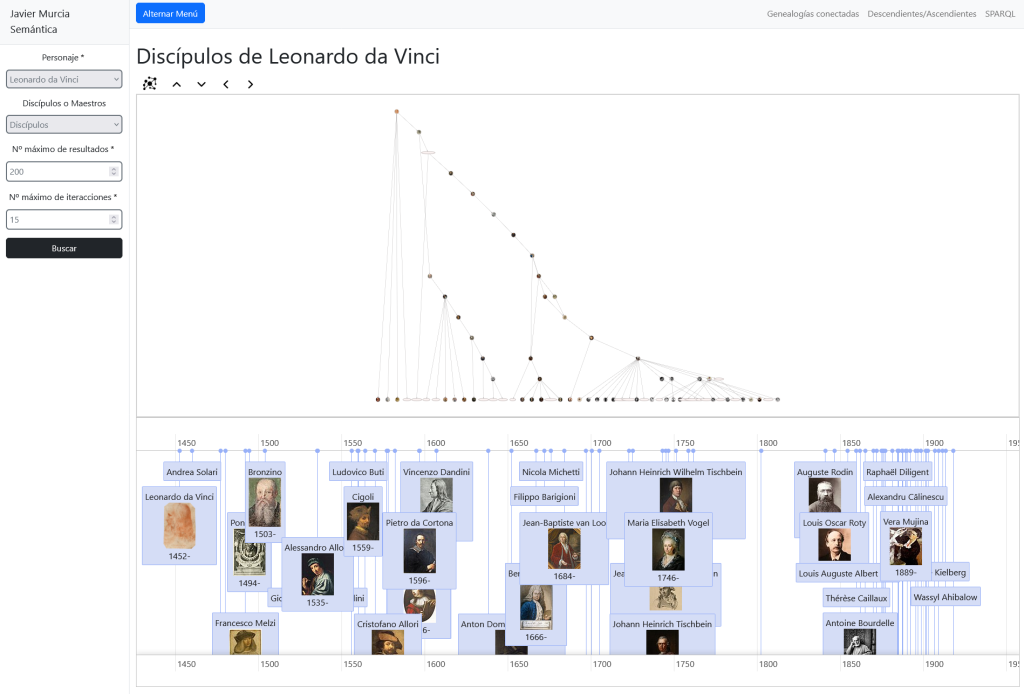
Gran parte de los datos culturales publicados por administraciones públicas se distribuyen en formatos cerrados o semi-estructurados, difíciles de integrar, reutilizar o cruzar con otras fuentes.
Este proyecto aborda ese problema mediante técnicas de Web Semántica, transformando datos institucionales en un grafo de conocimiento interoperable.
Objetivos del proyecto
El objetivo no era solo publicar una web, sino demostrar un flujo completo de transformación, modelado, enriquecimiento semántico y explotación de datos culturales.
Es decir la conversión de datos a rdf y su normalización con una ontología owl, que permita integrar esos datos a otras fuentes y grafos.
Transformar descripciones estáticas en un grafo de conocimiento navegable al tiempo que convertimos datos aislados y sin contexto temporal ni relacional en LOD.
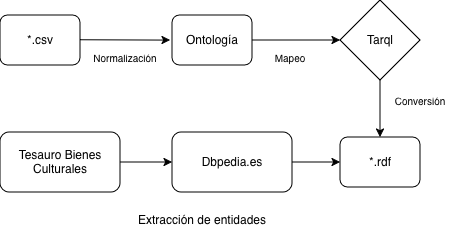
Transformación y normalización de datos
Partimos de la conversión del archivo Lugares de interés de la Región de Murcia. Puesto a disposición por la Comunidad Autónoma de la Región de Murcia, y que contiene información sobre lugares destacados por su interés turístico y cultural.
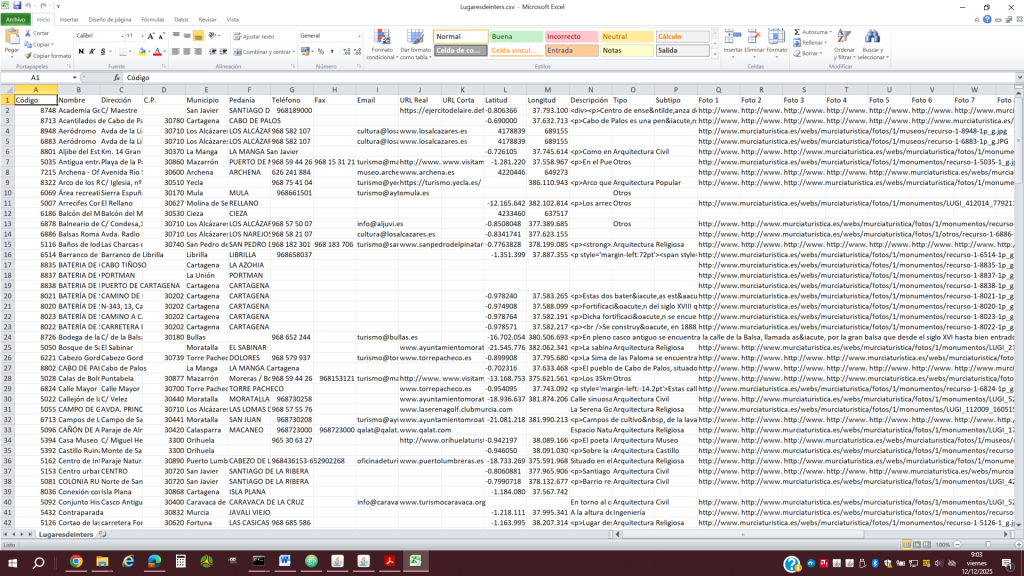
Comenzando con el archivo en formato XML, lo transformé a formato CSV con objeto de utilizar la librería Tarql, que es una herramienta de línea de comandos que convierte archivos CSV a RDF utilizando la sintaxis SPARQL 1.1.
Tarql nos permite mapear cada campo del archivo CSV a las clases y propiedades previamente elaboradas en una ontología, así como asignar el tipo de dato adecuado. Como por ejemplo, coordenadas espaciales o fechas.
Script de Tarql:
PREFIX monu: <http://www.monumentos.es/>
PREFIX xsd: <http://www.w3.org/2001/XMLSchema#>
PREFIX lugares: <http://www.monumentos.es/lugares/>
PREFIX rdfs: <http://www.w3.org/2000/01/rdf-schema#>
PREFIX owl: <http://www.w3.org/2002/07/owl#>
PREFIX geo: <http://www.w3.org/2003/01/geo/wgs84_pos#>
PREFIX geosparql: <http://www.opengis.net/ont/geosparql#>
PREFIX rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#>
CONSTRUCT {
?URI a monu:Sitio_de_interés;
rdf:type ?Tipo_;
rdf:type ?Subtipo_;
rdfs:label ?Nombre_;
rdfs:comment ?Descripción_;
monu:Está_en_Provincia lugares:Provincia_de_Murcia;
monu:Está_en_Municipio ?Municipio_;
monu:Está_en_localidad ?Pedanía;
monu:CP ?CP_;
monu:Dirección ?Dirección_;
monu:TLF ?Teléfono_;
monu:FAX ?FAX_;
monu:Email ?Email_;
monu:Web ?URL_Real;
monu:Web ?URL_Corta;
geo:lat ?lat_;
geo:lon ?lon_;
monu:Imagen1 ?Foto_1;
}
FROM <file:/-/Monumentos-Región-de-Murcia-comas.csv>
WHERE {
BIND (URI(CONCAT('http://www.monumentos.es/', ENCODE_FOR_URI(?Nombre))) AS ?URI)
BIND (IRI(CONCAT('http://www.monumentos.es/lugares/', ENCODE_FOR_URI(?Municipio))) AS ?Municipio_)
BIND (URI(CONCAT('monu:', ENCODE_FOR_URI(?Subtipo))) AS ?Subtipo_)
BIND (URI(CONCAT('http://www.monumentos.es/', ENCODE_FOR_URI(?Tipo))) AS ?Tipo_)
BIND (STRLANG(?dirección, "es") as ?Dirección_)
BIND (xsd:string(?FAX) AS ?Fax)
BIND (STRDT(?Teléfono,xsd:string) as ?Teléfono_)
BIND (STRDT(?Email,xsd:string) as ?Email_)
BIND (STRDT(?CodigoPostal,xsd:string) as ?CP_)
BIND (STRDT(?Latitud,xsd:float) as ?lat_)
BIND (STRDT(?Longitud,xsd:float) as ?lon_)
BIND (STRLANG(?Nombre, "es") as ?Nombre_)
BIND (STRLANG(?Descripción, "es") as ?Descripción_)
BIND (STRDT(?Fax,xsd:string) as ?FAX_)
}Lenguaje del código: PHP (php)
Este proceso con Tarql no es solo conversión entre formatos, sino mapping semántico:
- Asignación de clases OWL.
- Tipado de literales (fechas, coordenadas).
- Creación de URIs persistentes.
- Normalización del modelo de datos.
Y demuestra cómo transformar datos tabulares en un grafo semántico reutilizable, alineado con una ontología propia y preparado para su integración con otras fuentes RDF.
Ontología
El mapeo se fundamentó en las clases, tipos y propiedades de una ontología OWL sobre patrimonio monumental, de elaboración propia, que tiene por objetivo su uso en el ámbito de todo el país.
La motivación de la ontología de monumentos:
- Para este y futuros proyectos necesitaba una ontología para monumentos que fuera completa y coherente.
- DBpedia o Wikidata no ofrecen la coherencia lógica y semántica que buscaba.
- Posee clases y tipos que se adaptan a España y a Europa Occidental en general, aunque puede ser ampliada fácilmente.
La ontología, por tanto, no se limita a replicar categorías existentes, sino que proporciona una estructura conceptual coherente para describir bienes culturales de forma homogénea en todo el territorio nacional.
Enriquecimiento Manual
El csv de Lugares de interés de la Región de Murcia no contenía datos tales como fechas de creación, estilos, siglos, etc. Importantes para completar el grafo y por ello decido enriquecer “manualmente” los datos.
La calidad de un Grafo de Conocimiento depende de la integridad de sus datos. Detecté carencias críticas en la fuente original (fechas, estilos) e implementé una fase de curación de datos, combinando scripts de normalización en Tarql con validación manual para asegurar la consistencia histórica.
Extracción de Entidades
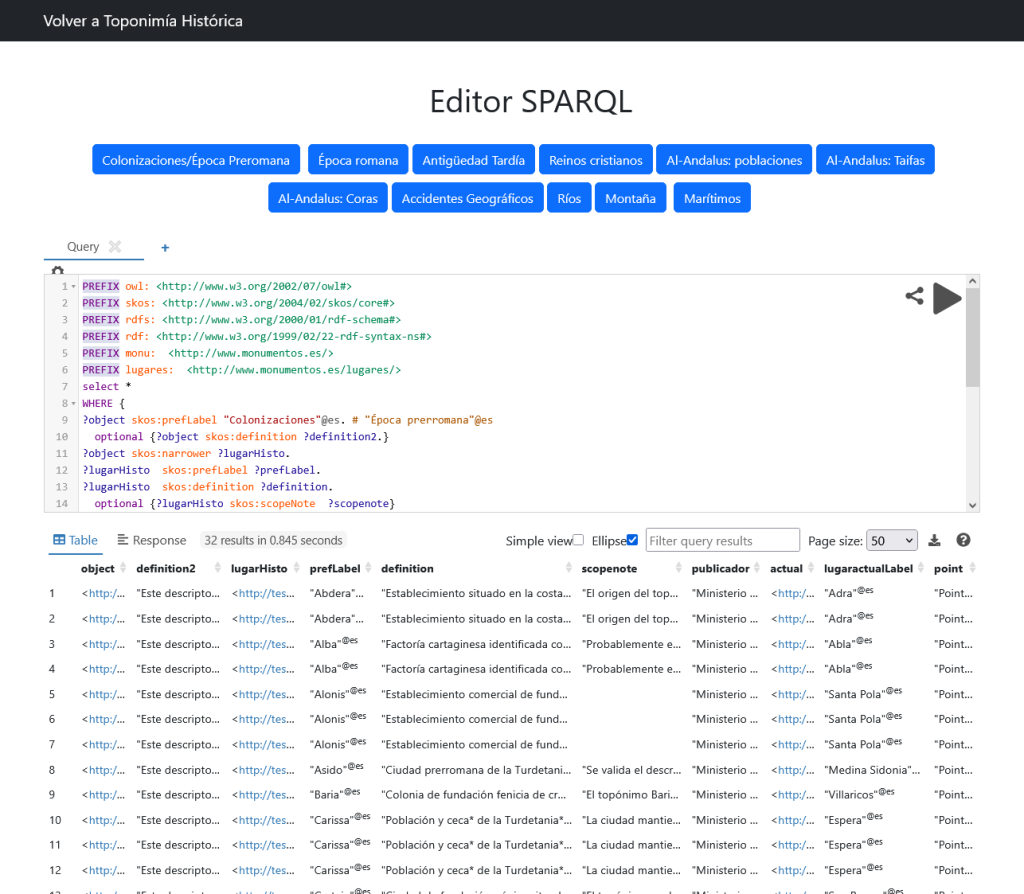
Realizamos un reconocimiento de entidades a partir de los textos de descripción de cada lugar de interés o monumento, utilizando Dbpedia como grafo “generalista” y el Tesauro de bienes culturales del Ministerio de Cultura como diccionario especializado en el tema que tratamos.
- Se trata de entity linking semántico.
- Uso combinado de:
- DBpedia (grafo generalista).
- Tesauro MEC (vocabulario especializado).
- Creación de relaciones semánticas reutilizables (skos:related).
Este proceso transforma texto libre en conocimiento estructurado, permitiendo búsquedas y razonamientos imposibles en un enfoque tradicional.
Cada monumento pasa así de ser una ficha descriptiva a convertirse en un nodo densamente conectado dentro de un grafo cultural. Con una rica red de relaciones semánticas que van más allá de la propia ontología.
Como ejemplo del resultado podemos ver la entidad “Acueducto de los Arcos” y su texto descriptivo, del cual se lograron reconocer y extraer las entidades subrayadas, que luego son vinculadas mediante la propiedad skos:related:
monu:Acueducto_de_los_Arcos a monu:Sitio_de_interés , monu:Arquitectura_Civil , monu:Acueducto , owl:NamedIndividual ;
rdfs:comment «El Acueducto de los Arcos Fue declarado Monumento Histórico Artístico Nacional por Real Decreto 1757/1982 de 18 de junio. Conocido como el Acueducto de la Cequeta conduce el agua elevada por la Rueda de Alcantarilla desde la acequia de la Alquibla o Barreras, cruzando por la cañá en dirección hacia la BozNegra, por debajo del casco urbano. La Noria, solicitada por la Diócesis de Cartagena en 1451 al Concejo de Murcia y construida en 1457 ha sido susituida en varias ocaciones como muestran las diferentes reconstrucciones de la canal. La primera noria debió de cumplir su función hasta 1549, cuando fue construida tras la riada de 1545, que asoló la Villa de Alcantarilla. Tras varias renovaciones a lo largo de su historia, llegamos a 1956, fecha en la que la Sociedad Metalúrgica y Terrestre de Alicante instala la actual noria. Con la construcción de la variante de la N-340 se demolieron varios arcos, quedando dividido a ambos lados de la carretera. Las excavaciones arqueológicas que se están llevando a cabo en el entorno del acueducto muestran la existencia de restos romanos anteriores (estructuras arquitectónicas y material cerámicos de los siglos I al III d.c). El Acueducto esta formado por un conjunto de arcos de medio punto cuya función es sostener el cajal de ladrillo. El acueducto cuenta con un total de 22 arcadas desde la Rueda.»@es;
Entidades extraídas:
monu:Acueducto_de_los_Arcos skos:related
<http://es.dbpedia.org/resource/N-340> ,
<http://es.dbpedia.org/resource/Diócesis_de_Cartagena> ,
<http://es.dbpedia.org/resource/1549> ,
<http://es.dbpedia.org/resource/Monumento_Histórico_Artístico_Nacional> ,
<http://es.dbpedia.org/resource/Alquibla> ,
<http://es.dbpedia.org/resource/1545> ,
<http://es.dbpedia.org/resource/Monumento_Histórico> ,
<http://es.dbpedia.org/resource/1457> ,
<http://es.dbpedia.org/resource/Rueda_de_Alcantarilla> ,
<http://es.dbpedia.org/resource/1982> ,
<http://tesauros.mecd.es/tesauros/bienesculturales/1008125> ,
<http://tesauros.mecd.es/tesauros/bienesculturales/1196792> ,
<http://es.dbpedia.org/resource/1956> ,
<http://es.dbpedia.org/resource/Real_Decreto> ,
<http://es.dbpedia.org/resource/Monumento_Histórico_Artístico> ,
<http://es.dbpedia.org/resource/1451> ,
<http://es.dbpedia.org/resource/Acueducto> ,
<http://es.dbpedia.org/resource/Alcantarilla> .Lenguaje del código: HTML, XML (xml)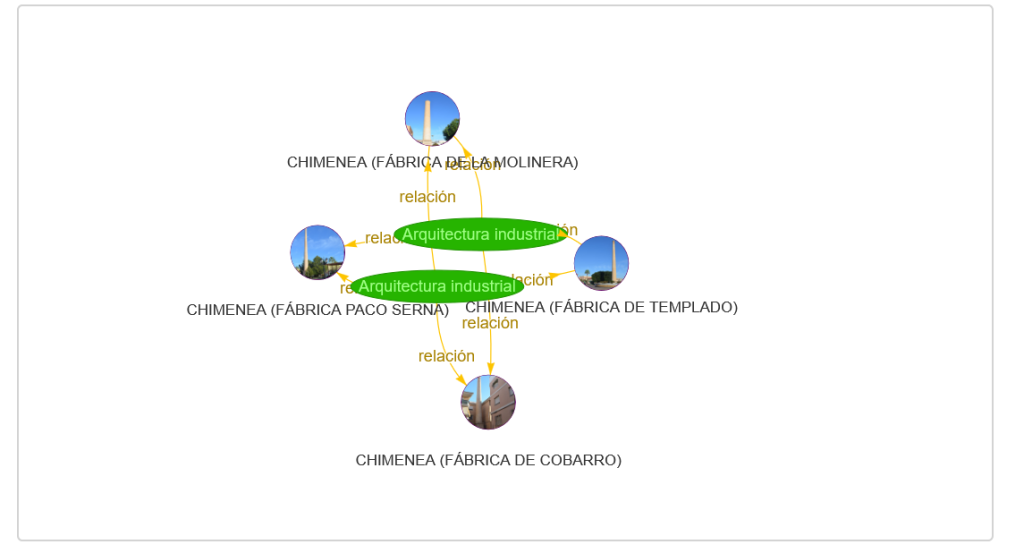
Tanto de Dbpedia como del Tesauro de Bienes Culturales
conseguimos 8357 relaciones skos:related.
En un ecomerce, diario, servicio virtual… el procedimiento para la construcción de un sistema de recomendación de productos o contenido comenzaría del mismo modo.
La Categorización Inductiva
Puesto que tanto los conceptos del Tesauro como las entidades de Dbpedia tienen una relación de pertenencia a Categorías que las engloban, me pareció buena idea dotar de esa capa de abstracción lógica y semántica a cada lugar de interés o monumento.
Las categorías funcionan como una ontología ‘inducida’, permitiendo agrupar entidades heterogéneas bajo conceptos compartidos sin necesidad de definirlos explícitamente en la ontología original.
Por ejemplo. gracias a conectar nuestros monumentos con Dbpedia, el sistema ‘aprendió’ automáticamente que el «Mármol de Macael«‘ y el «Ladrillo» son «Materiales de Construcción«, permitiendo crear un filtro de búsqueda por materiales sin haber etiquetado manualmente ni un solo monumento. Esto nos permite un comportamiento semántico avanzado.
Aquí podemos ver como diversas entidades extraídas quedan subsumidas bajo una categoría común, en este caso “Materiales de construcción”:
<http://es.dbpedia.org/resource/Categoría:Materiales_de_construcción>:
<http://es.dbpedia.org/resource/Teja_árabe>
<http://es.dbpedia.org/resource/Puerta_del_Perdón>
<http://es.dbpedia.org/resource/Acero>
<http://es.dbpedia.org/resource/Mármol_de_Macael>
<http://es.dbpedia.org/resource/Acero_corten>
<http://es.dbpedia.org/resource/Hebilla>
<http://es.dbpedia.org/resource/Ladrillo>
<http://es.dbpedia.org/resource/Vidrio>
<http://es.dbpedia.org/resource/Mármol_de_Carrara>
<http://es.dbpedia.org/resource/Acero_inoxidable>
<http://es.dbpedia.org/resource/Verja>
<http://es.dbpedia.org/resource/Mármol>
<http://es.dbpedia.org/resource/Cristal>
<http://es.dbpedia.org/resource/Tapial>
<http://es.dbpedia.org/resource/Puerta>Lenguaje del código: HTML, XML (xml)
De igual modo para las vinculaciones hechas con el Tesauro de Bienes Culturales:
<https://tesauros.cultura.gob.es/tesauros/bienesculturales/1001184> Elemento arquitectónico:
<http://tesauros.mecd.es/tesauros/bienesculturales/1008524> Suelo
<http://tesauros.mecd.es/tesauros/bienesculturales/1001323> Bóveda
<https://tesauros.cultura.gob.es/tesauros/bienesculturales/1005161> Pavimento
<https://tesauros.cultura.gob.es/tesauros/bienesculturales/1007537> Moldura
<https://tesauros.cultura.gob.es/tesauros/bienesculturales/1001096> LadrilloLenguaje del código: HTML, XML (xml)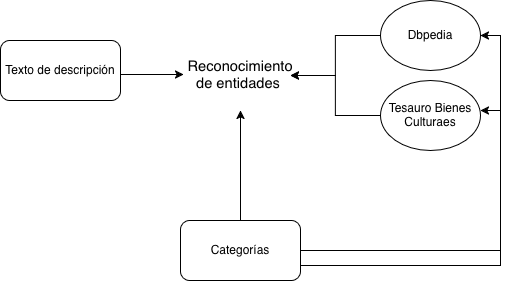
Frontend impulsado por Backend Semántico
Uno de los objetivos era llevar esta estructura de grafo a una página web. Es decir, crear una web basada en grafo de conocimiento que utilizara las clases, tipos y propiedades para construir la arquitectura de contenido:
- Una web generada desde un grafo.
- Arquitectura de contenidos basada en clases y propiedades.
- Navegación semántica.
- Recomendaciones por tipología, estilo, ubicación.
- Filtros basados en relaciones inferidas.
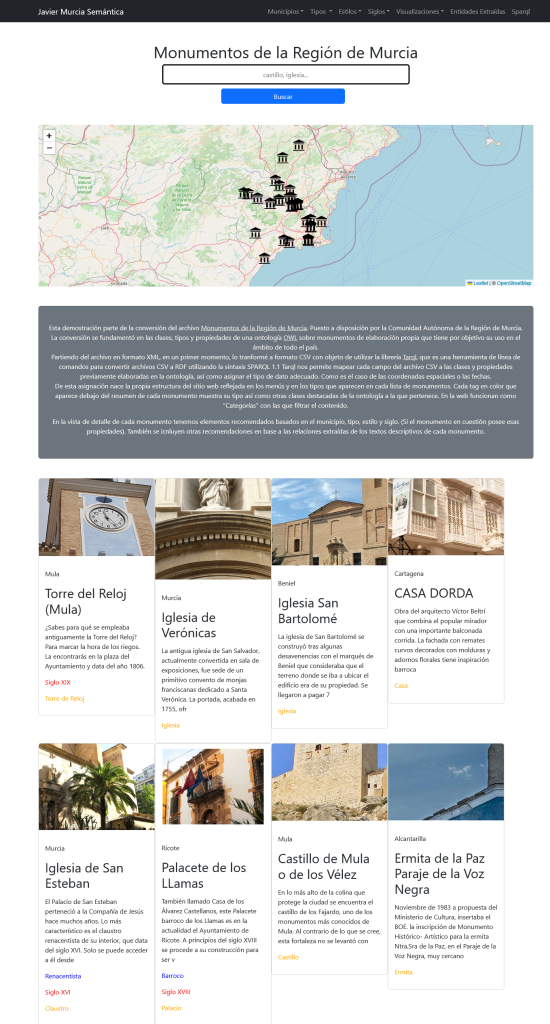
Los menús reflejan las clases y propiedades principales de la ontología:
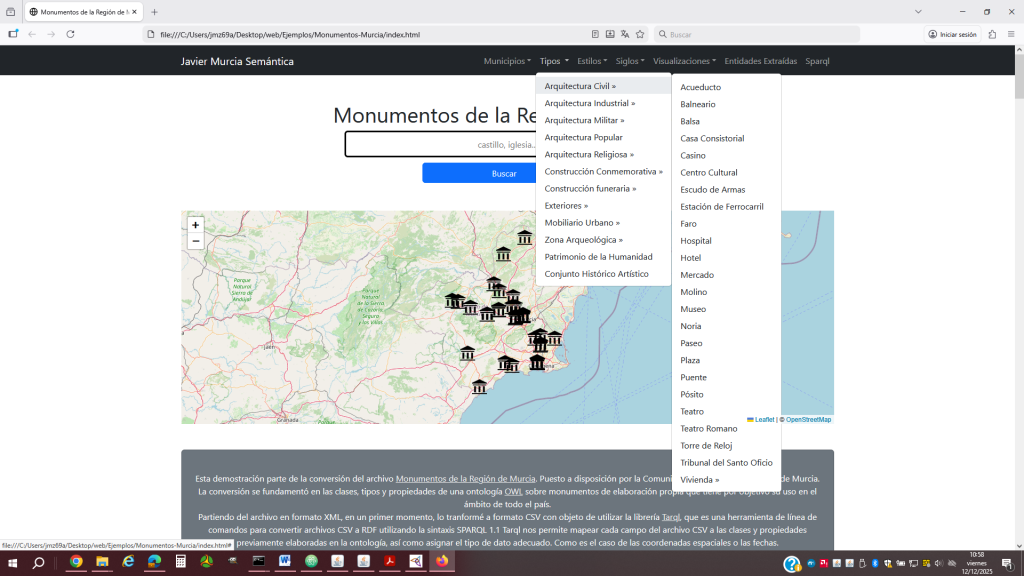
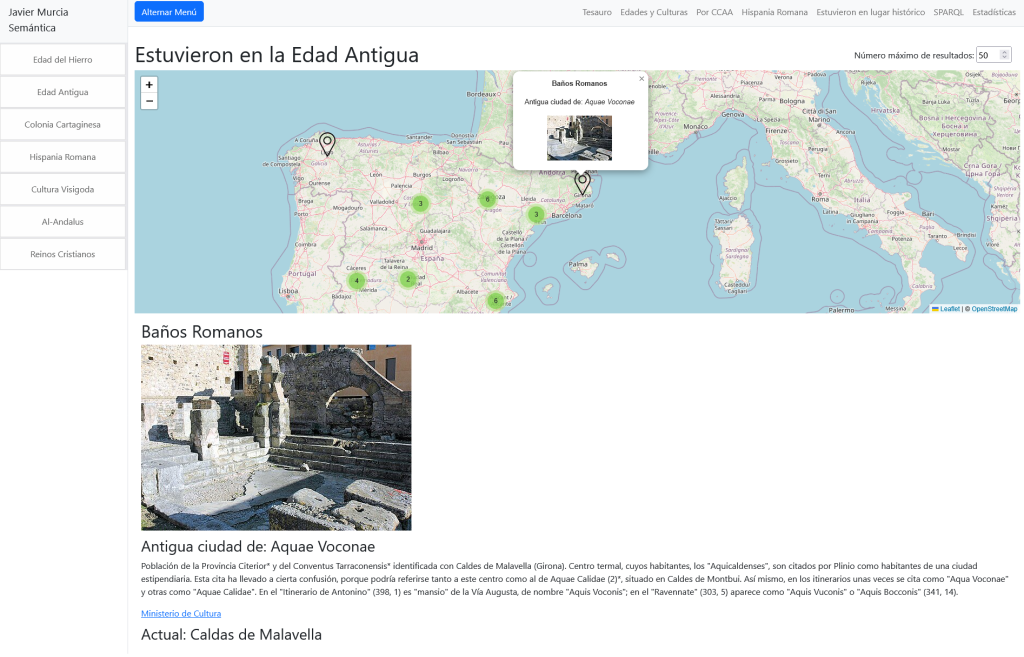
Las páginas de detalle incluyen el texto de la descripción, clases y categorías de la ontología, recomendaciones en base a las tipologías, ubicaciones, estilo, etc…
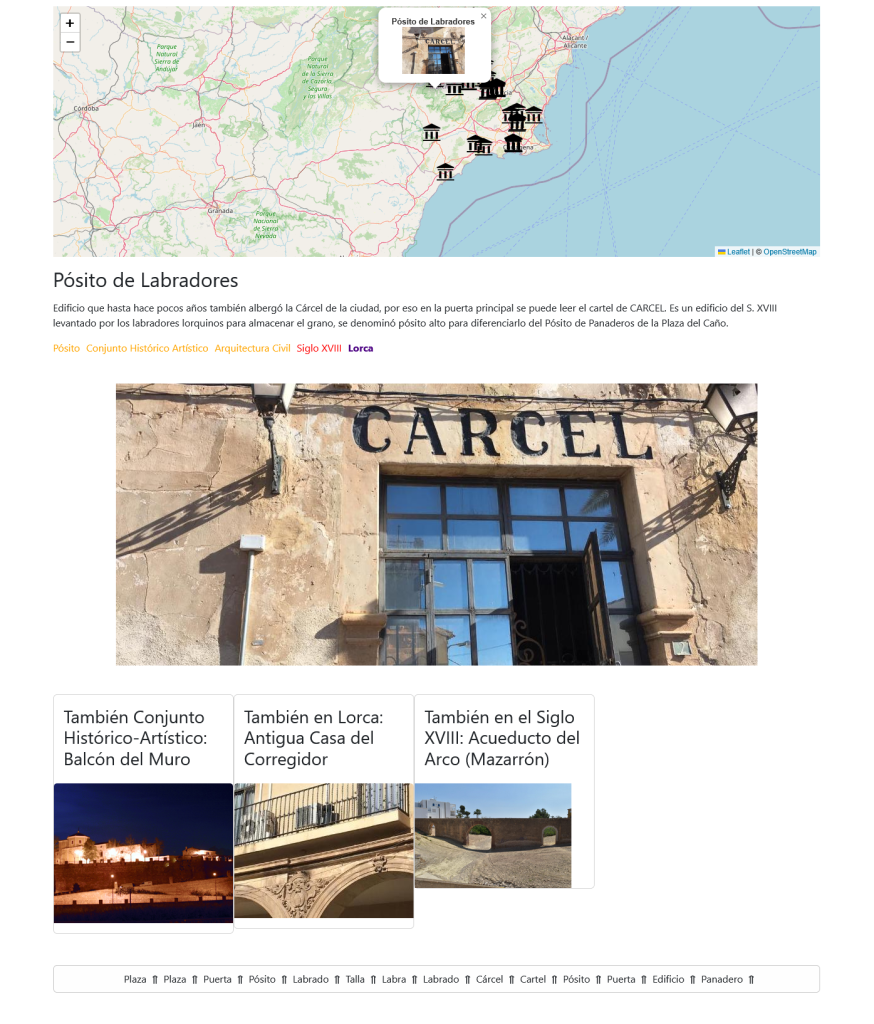
Gracias a la extracción de entidades, en la parte inferior, tenemos relaciones adicionales:
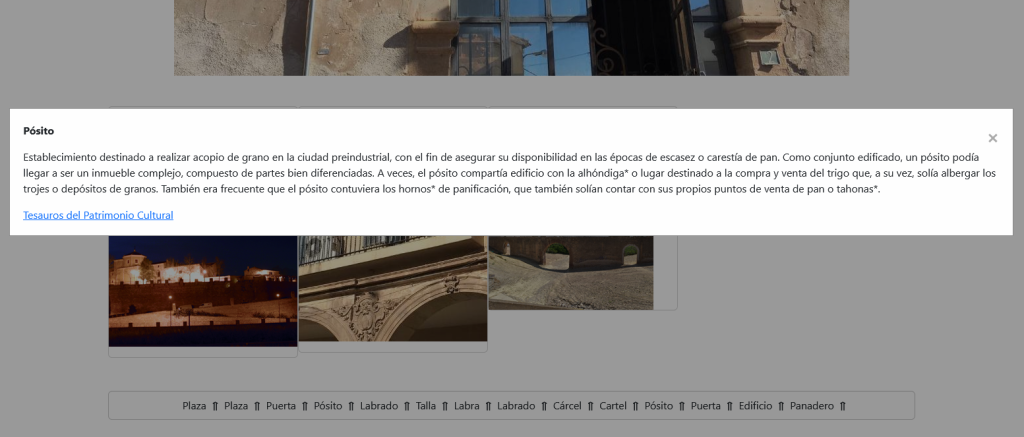
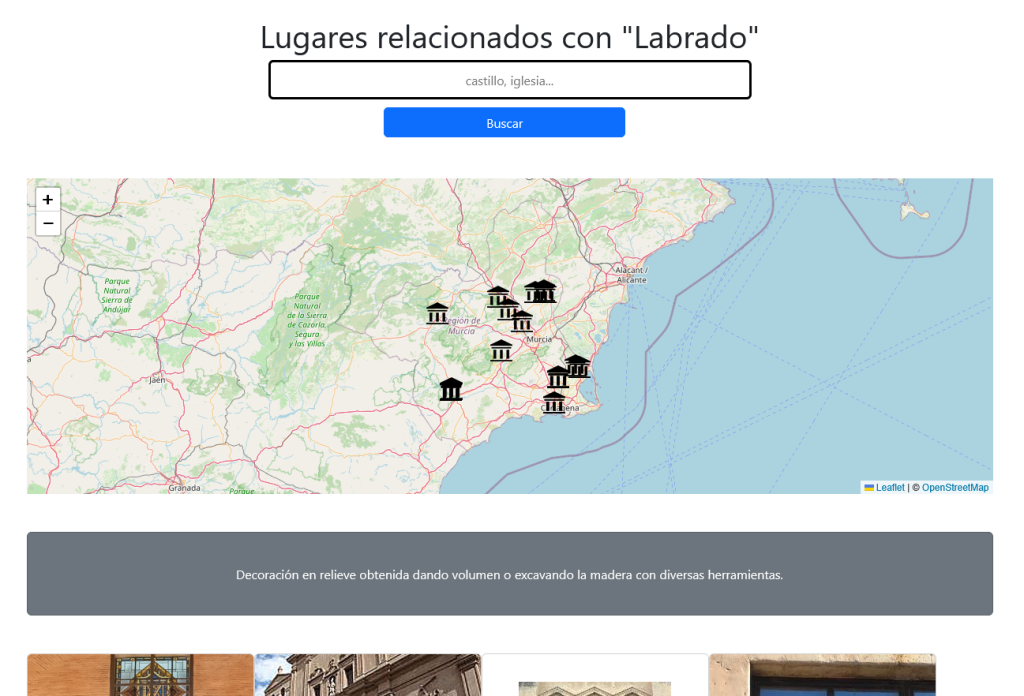
Podemos consultar sus definiciones en Dbpedia o en el Tesauro y también son útiles para hacer filtrado de lugares de interés por esas relaciones extraídas:
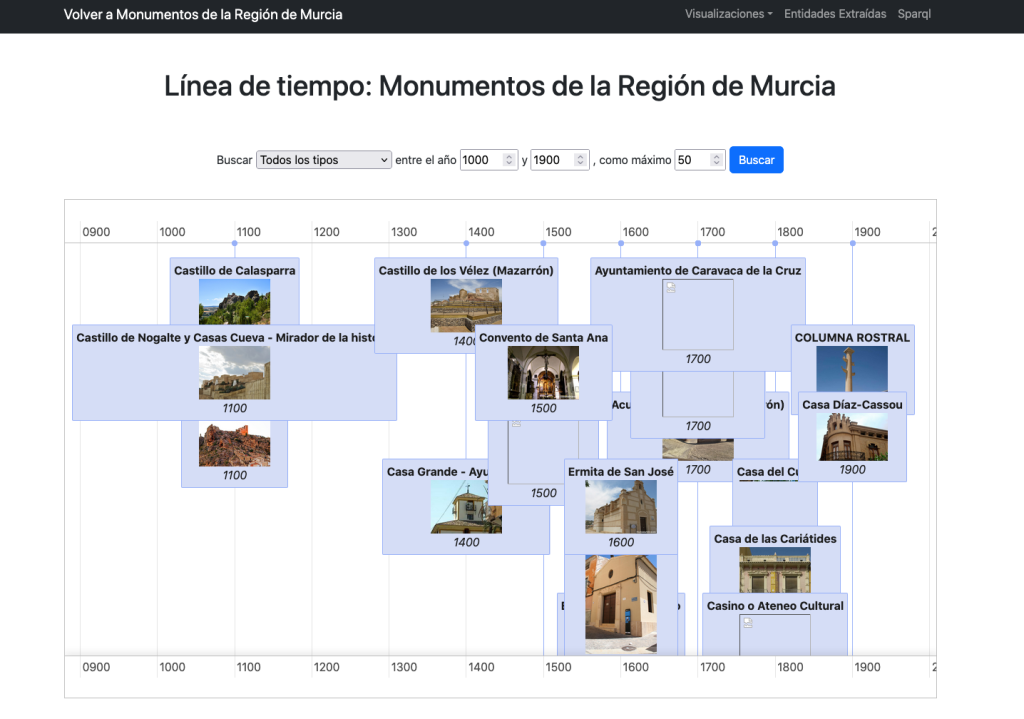
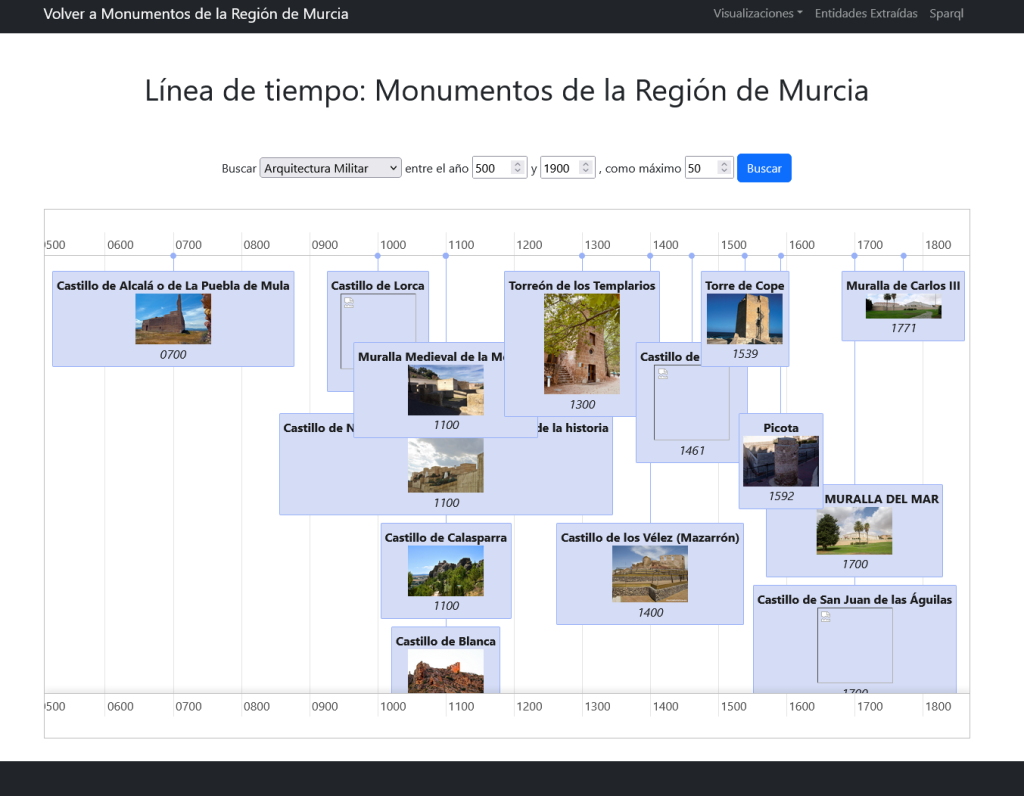
Se incluye una línea de tiempo en la que desplegar los monumentos por tipos y estilos según su fecha de creación o construcción:
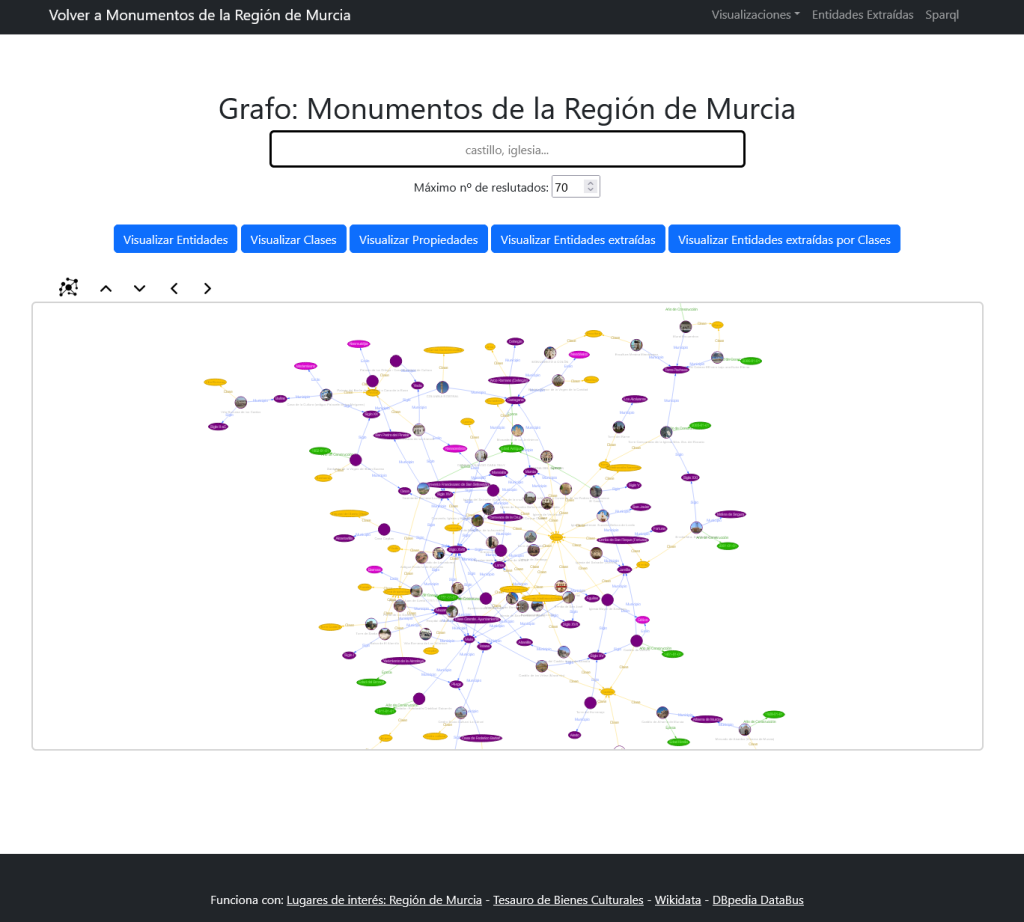
También una sección donde visualizar la ontología, las entidades, y las relaciones extraídas:
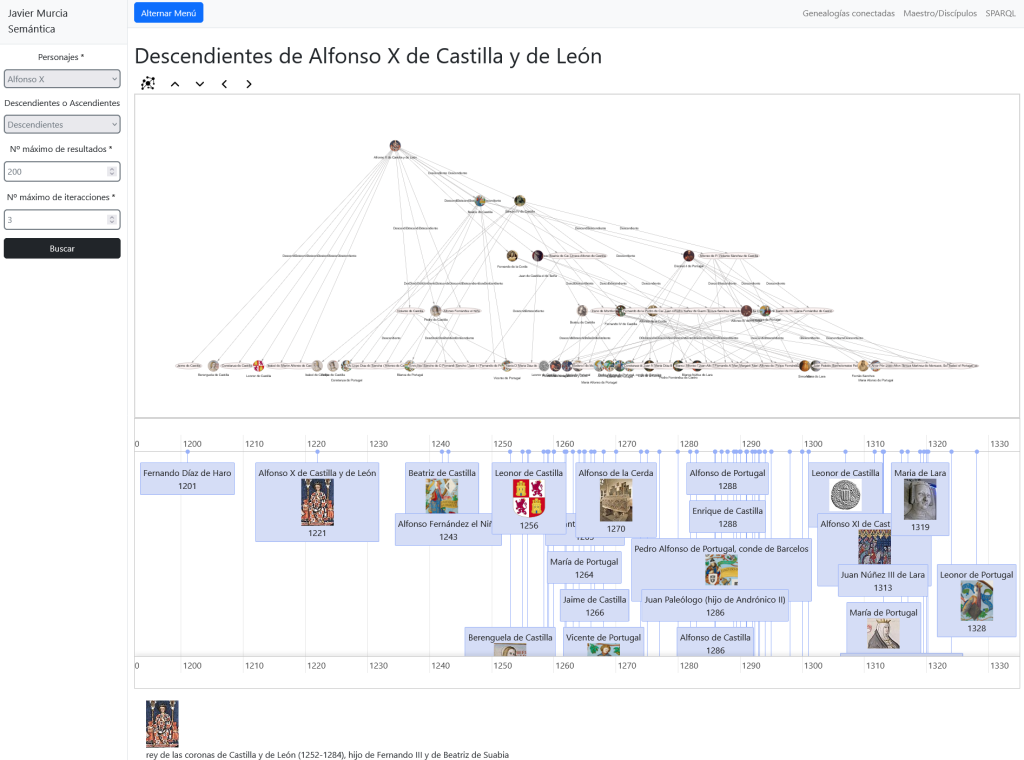
Tenemos una sección especial para navegar con las entidades y las categorías extraídas:

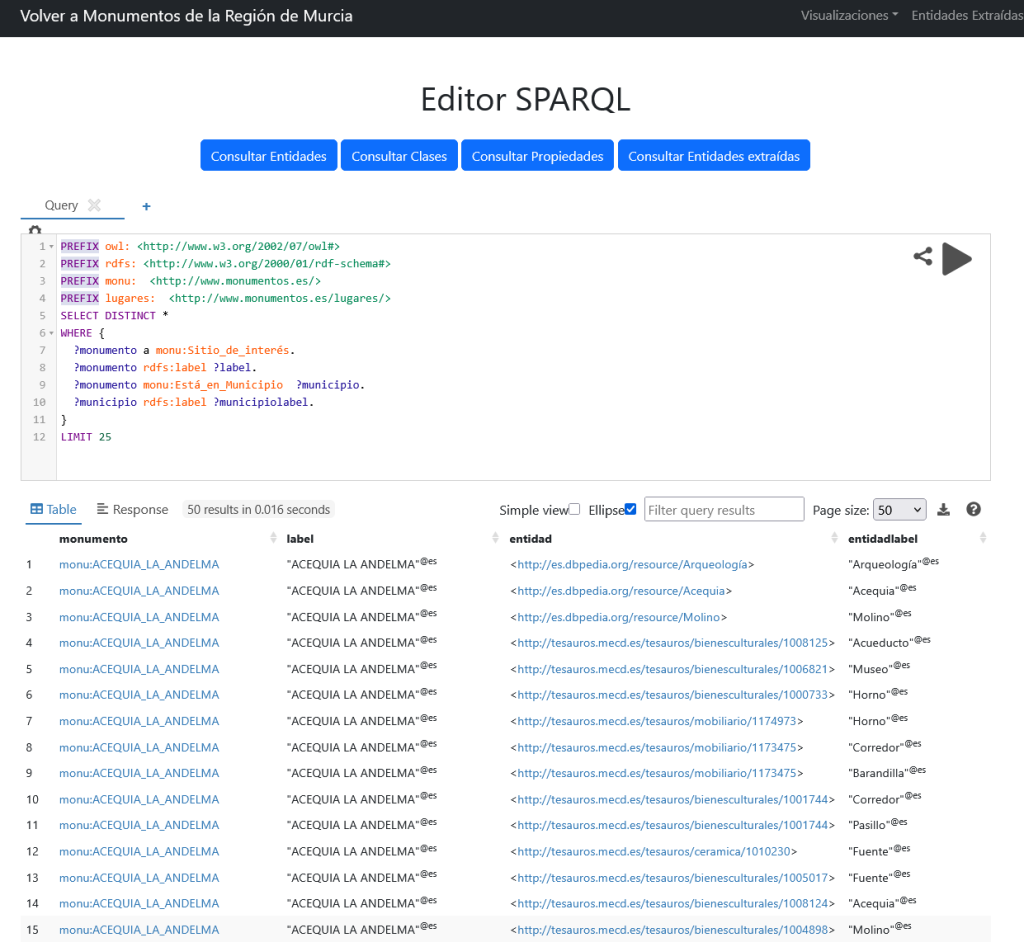
Y se incluye un punto SPARQL para realizar consultas:
Estadísticas del proyecto
| Sitios de interés | 461 |
| Entidades extraídas | 8.357 |
| Categorías dbpedia | 135 |
| Categorías Tesauro | 474 |
| Número de triples | 2.6181 |
| Categorías navegables Ontología | 135 |
| Categorías navegables Extracción | 8.357 |
Aplicaciones prácticas
- Portales culturales semánticos.
- Turismo inteligente.
- Recomendadores culturales.
- Integración con GIS.
- Análisis de patrimonio por épocas, estilos o materiales.
- Enriquecimiento automático de catálogos.
- Sistemas de recomendación en ecommerce y webs.
Qué demuestra este proyecto:
- Dominio de Web Semántica.
- Transformación de datos reales.
- Modelado ontológico.
- SPARQL avanzado.
- Entity linking.
- Publicación web basada en grafos.